 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA unified complexity bound for logconcave sampling
Jun 10, 2026We give a simple, unified, and nearly tight bound for sampling arbitrary logconcave distributions from a warm start using the In-and-Out algorithm along with exponential lifting. The main new ingredient in the analysis is an improved bound on the Poincaré constant of a lifted distribution. As a consequence, the resulting convergence rate is nearly tight for both constrained settings (e.g., Gaussian restricted to a convex body) and well-conditioned settings (e.g., strongly logconcave and smooth densities).
Zeroth-order log-concave sampling
Jul 24, 2025We study the zeroth-order query complexity of log-concave sampling, specifically uniform sampling from convex bodies using membership oracles. We propose a simple variant of the proximal sampler that achieves the query complexity with matched R\'enyi orders between the initial warmness and output guarantee. Specifically, for any $\varepsilon>0$ and $q\geq2$, the sampler, initialized at $\pi_{0}$, outputs a sample whose law is $\varepsilon$-close in $q$-R\'enyi divergence to $\pi$, the uniform distribution over a convex body in $\mathbb{R}^{d}$, using $\widetilde{O}(qM_{q}^{q/(q-1)}d^{2}\,\lVert\operatorname{cov}\pi\rVert\log\frac{1}{\varepsilon})$ membership queries, where $M_{q}=\lVert\text{d}\pi_{0}/\text{d}\pi\rVert_{L^{q}(\pi)}$. We further introduce a simple annealing scheme that produces a warm start in $q$-R\'enyi divergence (i.e., $M_{q}=O(1)$) using $\widetilde{O}(qd^{2}R^{3/2}\,\lVert\operatorname{cov}\pi\rVert^{1/4})$ queries, where $R^{2}=\mathbb{E}_{\pi}[|\cdot|^{2}]$. This interpolates between known complexities for warm-start generation in total variation and R\'enyi-infinity divergence. To relay a R\'enyi warmness across the annealing scheme, we establish hypercontractivity under simultaneous heat flow and translate it into an improved mixing guarantee for the proximal sampler under a logarithmic Sobolev inequality. These results extend naturally to general log-concave distributions accessible via evaluation oracles, incurring additional quadratic queries.
Faster logconcave sampling from a cold start in high dimension
May 03, 2025We present a faster algorithm to generate a warm start for sampling an arbitrary logconcave density specified by an evaluation oracle, leading to the first sub-cubic sampling algorithms for inputs in (near-)isotropic position. A long line of prior work incurred a warm-start penalty of at least linear in the dimension, hitting a cubic barrier, even for the special case of uniform sampling from convex bodies. Our improvement relies on two key ingredients of independent interest. (1) We show how to sample given a warm start in weaker notions of distance, in particular $q$-R\'enyi divergence for $q=\widetilde{\mathcal{O}}(1)$, whereas previous analyses required stringent $\infty$-R\'enyi divergence (with the exception of Hit-and-Run, whose known mixing time is higher). This marks the first improvement in the required warmness since Lov\'asz and Simonovits (1991). (2) We refine and generalize the log-Sobolev inequality of Lee and Vempala (2018), originally established for isotropic logconcave distributions in terms of the diameter of the support, to logconcave distributions in terms of a geometric average of the support diameter and the largest eigenvalue of the covariance matrix.
Fast Tensor Completion via Approximate Richardson Iteration
Feb 13, 2025We study tensor completion (TC) through the lens of low-rank tensor decomposition (TD). Many TD algorithms use fast alternating minimization methods, which solve highly structured linear regression problems at each step (e.g., for CP, Tucker, and tensor-train decompositions). However, such algebraic structure is lost in TC regression problems, making direct extensions unclear. To address this, we propose a lifting approach that approximately solves TC regression problems using structured TD regression algorithms as blackbox subroutines, enabling sublinear-time methods. We theoretically analyze the convergence rate of our approximate Richardson iteration based algorithm, and we demonstrate on real-world tensors that its running time can be 100x faster than direct methods for CP completion.
Sampling and Integration of Logconcave Functions by Algorithmic Diffusion
Nov 20, 2024
We study the complexity of sampling, rounding, and integrating arbitrary logconcave functions. Our new approach provides the first complexity improvements in nearly two decades for general logconcave functions for all three problems, and matches the best-known complexities for the special case of uniform distributions on convex bodies. For the sampling problem, our output guarantees are significantly stronger than previously known, and lead to a streamlined analysis of statistical estimation based on dependent random samples.
Covariance estimation using Markov chain Monte Carlo
Oct 22, 2024We investigate the complexity of covariance matrix estimation for Gibbs distributions based on dependent samples from a Markov chain. We show that when $\pi$ satisfies a Poincar\'e inequality and the chain possesses a spectral gap, we can achieve similar sample complexity using MCMC as compared to an estimator constructed using i.i.d. samples, with potentially much better query complexity. As an application of our methods, we show improvements for the query complexity in both constrained and unconstrained settings for concrete instances of MCMC. In particular, we provide guarantees regarding isotropic rounding procedures for sampling uniformly on convex bodies.
Rényi-infinity constrained sampling with $d^3$ membership queries
Jul 17, 2024Uniform sampling over a convex body is a fundamental algorithmic problem, yet the convergence in KL or R\'enyi divergence of most samplers remains poorly understood. In this work, we propose a constrained proximal sampler, a principled and simple algorithm that possesses elegant convergence guarantees. Leveraging the uniform ergodicity of this sampler, we show that it converges in the R\'enyi-infinity divergence ($\mathcal R_\infty$) with no query complexity overhead when starting from a warm start. This is the strongest of commonly considered performance metrics, implying rates in $\{\mathcal R_q, \mathsf{KL}\}$ convergence as special cases. By applying this sampler within an annealing scheme, we propose an algorithm which can approximately sample $\varepsilon$-close to the uniform distribution on convex bodies in $\mathcal R_\infty$-divergence with $\widetilde{\mathcal{O}}(d^3\, \text{polylog} \frac{1}{\varepsilon})$ query complexity. This improves on all prior results in $\{\mathcal R_q, \mathsf{KL}\}$-divergences, without resorting to any algorithmic modifications or post-processing of the sample. It also matches the prior best known complexity in total variation distance.
In-and-Out: Algorithmic Diffusion for Sampling Convex Bodies
May 02, 2024

We present a new random walk for uniformly sampling high-dimensional convex bodies. It achieves state-of-the-art runtime complexity with stronger guarantees on the output than previously known, namely in R\'enyi divergence (which implies TV, $\mathcal{W}_2$, KL, $\chi^2$). The proof departs from known approaches for polytime algorithms for the problem -- we utilize a stochastic diffusion perspective to show contraction to the target distribution with the rate of convergence determined by functional isoperimetric constants of the stationary density.
Sampling from the Mean-Field Stationary Distribution
Feb 18, 2024
We study the complexity of sampling from the stationary distribution of a mean-field SDE, or equivalently, the complexity of minimizing a functional over the space of probability measures which includes an interaction term. Our main insight is to decouple the two key aspects of this problem: (1) approximation of the mean-field SDE via a finite-particle system, via uniform-in-time propagation of chaos, and (2) sampling from the finite-particle stationary distribution, via standard log-concave samplers. Our approach is conceptually simpler and its flexibility allows for incorporating the state-of-the-art for both algorithms and theory. This leads to improved guarantees in numerous settings, including better guarantees for optimizing certain two-layer neural networks in the mean-field regime.
Understanding Adam Optimizer via Online Learning of Updates: Adam is FTRL in Disguise
Feb 02, 2024
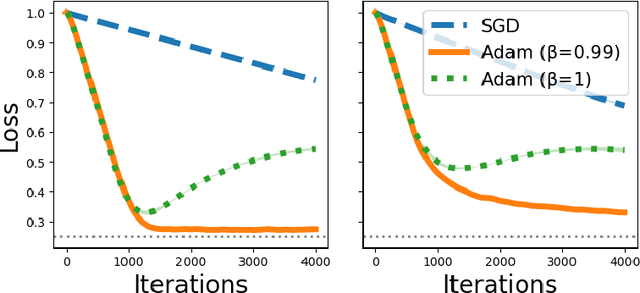
Despite the success of the Adam optimizer in practice, the theoretical understanding of its algorithmic components still remains limited. In particular, most existing analyses of Adam show the convergence rate that can be simply achieved by non-adative algorithms like SGD. In this work, we provide a different perspective based on online learning that underscores the importance of Adam's algorithmic components. Inspired by Cutkosky et al. (2023), we consider the framework called online learning of updates, where we choose the updates of an optimizer based on an online learner. With this framework, the design of a good optimizer is reduced to the design of a good online learner. Our main observation is that Adam corresponds to a principled online learning framework called Follow-the-Regularized-Leader (FTRL). Building on this observation, we study the benefits of its algorithmic components from the online learning perspective.