 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
FiLM: Fill-in Language Models for Any-Order Generation
Oct 15, 2023



Language models have become the backbone of today's AI systems. However, their predominant left-to-right generation limits the use of bidirectional context, which is essential for tasks that involve filling text in the middle. We propose the Fill-in Language Model (FiLM), a new language modeling approach that allows for flexible generation at any position without adhering to a specific generation order. Its training extends the masked language modeling objective by adopting varying mask probabilities sampled from the Beta distribution to enhance the generative capabilities of FiLM. During inference, FiLM can seamlessly insert missing phrases, sentences, or paragraphs, ensuring that the outputs are fluent and are coherent with the surrounding context. In both automatic and human evaluations, FiLM outperforms existing infilling methods that rely on left-to-right language models trained on rearranged text segments. FiLM is easy to implement and can be either trained from scratch or fine-tuned from a left-to-right language model. Notably, as the model size grows, FiLM's perplexity approaches that of strong left-to-right language models of similar sizes, indicating FiLM's scalability and potential as a large language model.
Generating Sequences by Learning to Self-Correct
Oct 31, 2022Sequence generation applications require satisfying semantic constraints, such as ensuring that programs are correct, using certain keywords, or avoiding undesirable content. Language models, whether fine-tuned or prompted with few-shot demonstrations, frequently violate these constraints, and lack a mechanism to iteratively revise their outputs. Moreover, some powerful language models are of extreme scale or inaccessible, making it inefficient, if not infeasible, to update their parameters for task-specific adaptation. We present Self-Correction, an approach that decouples an imperfect base generator (an off-the-shelf language model or supervised sequence-to-sequence model) from a separate corrector that learns to iteratively correct imperfect generations. To train the corrector, we propose an online training procedure that can use either scalar or natural language feedback on intermediate imperfect generations. We show that Self-Correction improves upon the base generator in three diverse generation tasks - mathematical program synthesis, lexically-constrained generation, and toxicity control - even when the corrector is much smaller than the base generator.
Controlling Directions Orthogonal to a Classifier
Jan 27, 2022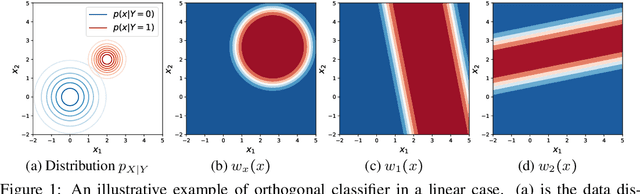
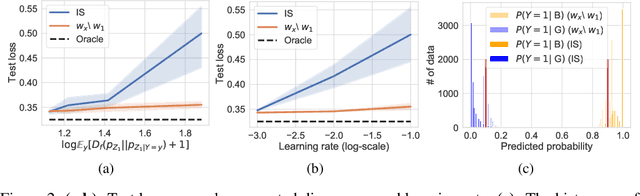


We propose to identify directions invariant to a given classifier so that these directions can be controlled in tasks such as style transfer. While orthogonal decomposition is directly identifiable when the given classifier is linear, we formally define a notion of orthogonality in the non-linear case. We also provide a surprisingly simple method for constructing the orthogonal classifier (a classifier utilizing directions other than those of the given classifier). Empirically, we present three use cases where controlling orthogonal variation is important: style transfer, domain adaptation, and fairness. The orthogonal classifier enables desired style transfer when domains vary in multiple aspects, improves domain adaptation with label shifts and mitigates the unfairness as a predictor. The code is available at http://github.com/Newbeeer/orthogonal_classifier
Blank Language Models
Feb 08, 2020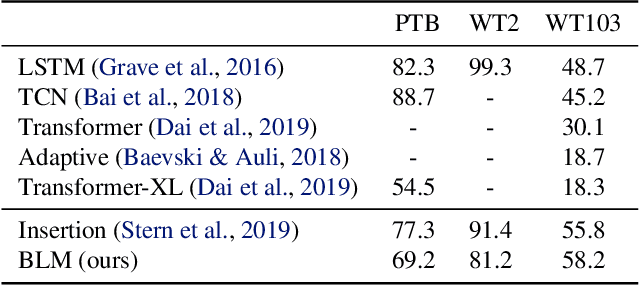

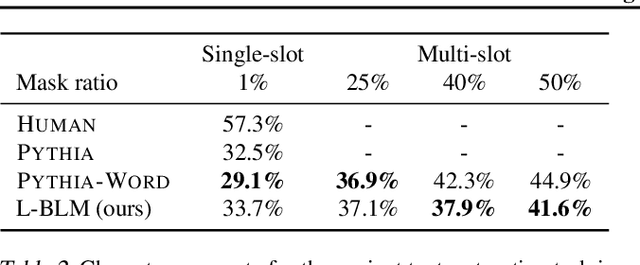
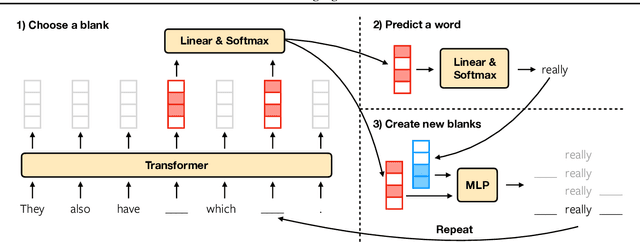
We propose Blank Language Model (BLM), a model that generates sequences by dynamically creating and filling in blanks. Unlike previous masked language models or the Insertion Transformer, BLM uses blanks to control which part of the sequence to expand. This fine-grained control of generation is ideal for a variety of text editing and rewriting tasks. The model can start from a single blank or partially completed text with blanks at specified locations. It iteratively determines which word to place in a blank and whether to insert new blanks, and stops generating when no blanks are left to fill. BLM can be efficiently trained using a lower bound of the marginal data likelihood, and achieves perplexity comparable to traditional left-to-right language models on the Penn Treebank and WikiText datasets. On the task of filling missing text snippets, BLM significantly outperforms all other baselines in terms of both accuracy and fluency. Experiments on style transfer and damaged ancient text restoration demonstrate the potential of this framework for a wide range of applications.
Learning to Make Generalizable and Diverse Predictions for Retrosynthesis
Oct 21, 2019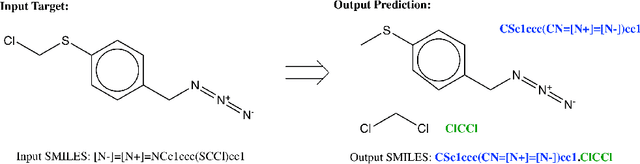
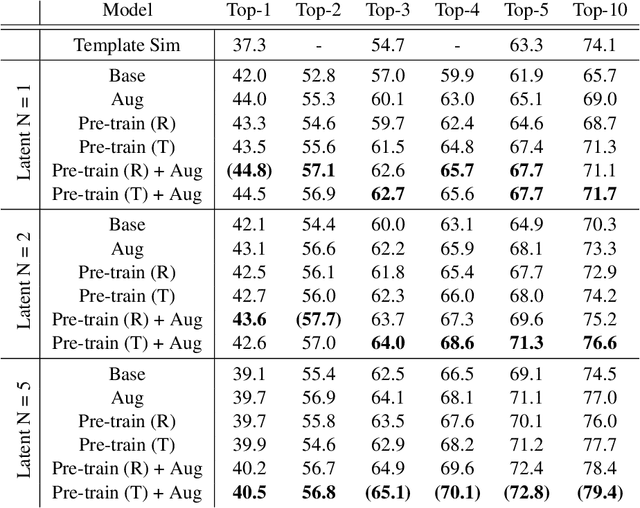
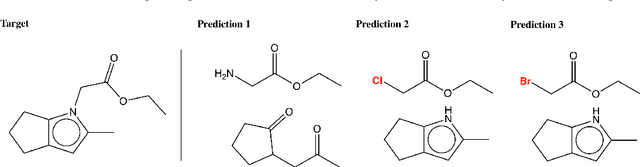

We propose a new model for making generalizable and diverse retrosynthetic reaction predictions. Given a target compound, the task is to predict the likely chemical reactants to produce the target. This generative task can be framed as a sequence-to-sequence problem by using the SMILES representations of the molecules. Building on top of the popular Transformer architecture, we propose two novel pre-training methods that construct relevant auxiliary tasks (plausible reactions) for our problem. Furthermore, we incorporate a discrete latent variable model into the architecture to encourage the model to produce a diverse set of alternative predictions. On the 50k subset of reaction examples from the United States patent literature (USPTO-50k) benchmark dataset, our model greatly improves performance over the baseline, while also generating predictions that are more diverse.
Latent Space Secrets of Denoising Text-Autoencoders
May 29, 2019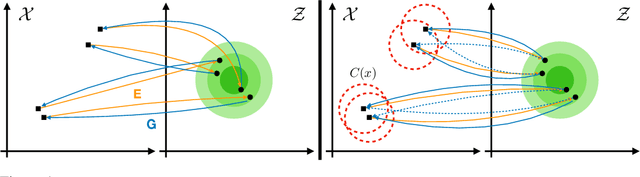

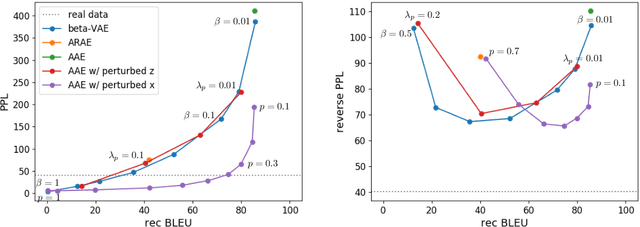
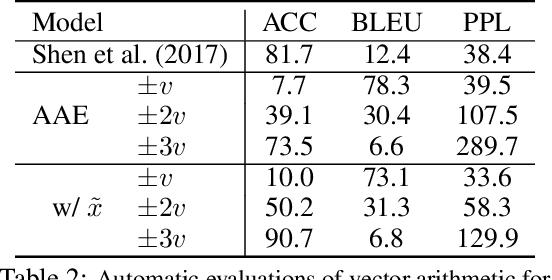
While neural language models have recently demonstrated impressive performance in unconditional text generation, controllable generation and manipulation of text remain challenging. Latent variable generative models provide a natural approach for control, but their application to text has proven more difficult than to images. Models such as variational autoencoders may suffer from posterior collapse or learning an irregular latent geometry. We propose to instead employ adversarial autoencoders (AAEs) and add local perturbations by randomly replacing/removing words from input sentences during training. Within the prior enforced by the adversary, structured perturbations in the data space begin to carve and organize the latent space. Theoretically, we prove that perturbations encourage similar sentences to map to similar latent representations. Experimentally, we investigate the trade-off between text-generation and autoencoder-reconstruction capabilities. Our straightforward approach significantly improves over regular AAEs as well as other autoencoders, and enables altering the tense/sentiment of sentences through simple addition of a fixed vector offset to their latent representation.
Mixture Models for Diverse Machine Translation: Tricks of the Trade
Feb 20, 2019
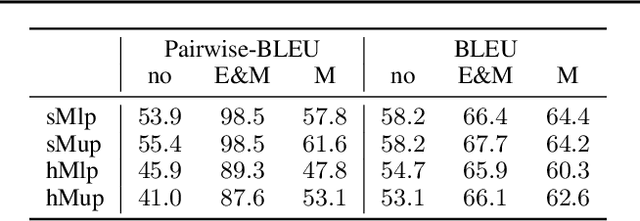
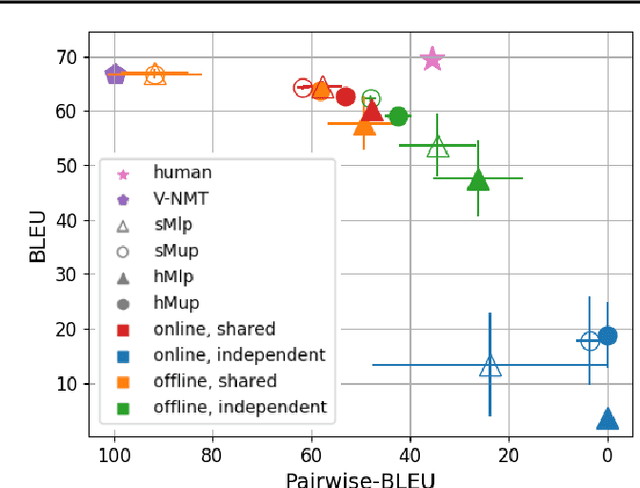
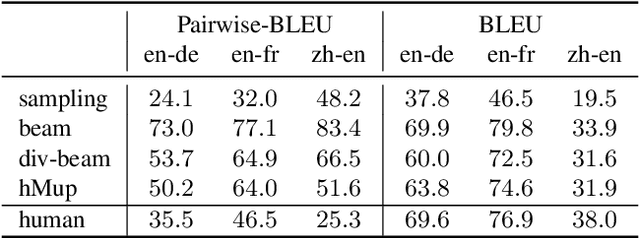
Mixture models trained via EM are among the simplest, most widely used and well understood latent variable models in the machine learning literature. Surprisingly, these models have been hardly explored in text generation applications such as machine translation. In principle, they provide a latent variable to control generation and produce a diverse set of hypotheses. In practice, however, mixture models are prone to degeneracies---often only one component gets trained or the latent variable is simply ignored. We find that disabling dropout noise in responsibility computation is critical to successful training. In addition, the design choices of parameterization, prior distribution, hard versus soft EM and online versus offline assignment can dramatically affect model performance. We develop an evaluation protocol to assess both quality and diversity of generations against multiple references, and provide an extensive empirical study of several mixture model variants. Our analysis shows that certain types of mixture models are more robust and offer the best trade-off between translation quality and diversity compared to variational models and diverse decoding approaches.
Style Transfer from Non-Parallel Text by Cross-Alignment
Nov 06, 2017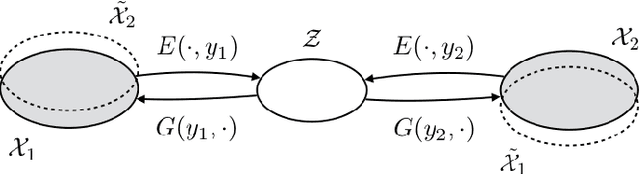

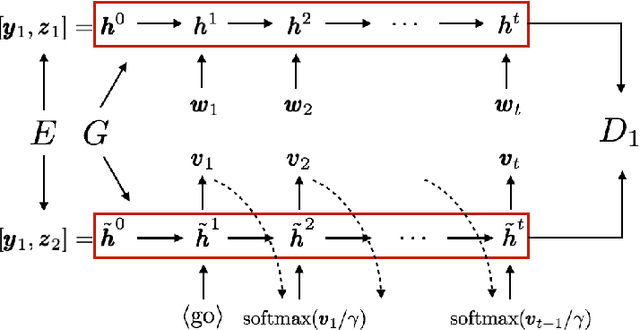

This paper focuses on style transfer on the basis of non-parallel text. This is an instance of a broad family of problems including machine translation, decipherment, and sentiment modification. The key challenge is to separate the content from other aspects such as style. We assume a shared latent content distribution across different text corpora, and propose a method that leverages refined alignment of latent representations to perform style transfer. The transferred sentences from one style should match example sentences from the other style as a population. We demonstrate the effectiveness of this cross-alignment method on three tasks: sentiment modification, decipherment of word substitution ciphers, and recovery of word order.