 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture Models for Diverse Machine Translation: Tricks of the Trade
Paper and Code
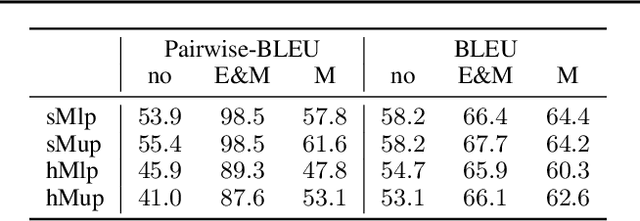
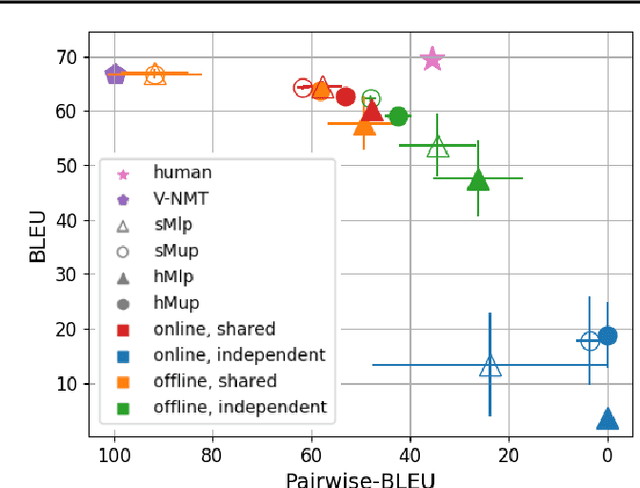
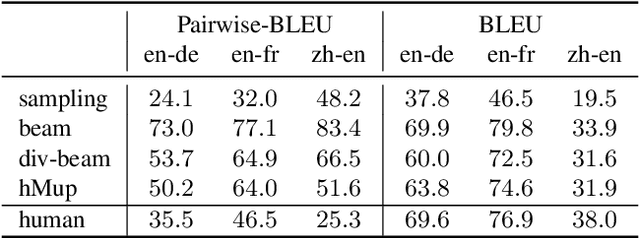
Mixture models trained via EM are among the simplest, most widely used and well understood latent variable models in the machine learning literature. Surprisingly, these models have been hardly explored in text generation applications such as machine translation. In principle, they provide a latent variable to control generation and produce a diverse set of hypotheses. In practice, however, mixture models are prone to degeneracies---often only one component gets trained or the latent variable is simply ignored. We find that disabling dropout noise in responsibility computation is critical to successful training. In addition, the design choices of parameterization, prior distribution, hard versus soft EM and online versus offline assignment can dramatically affect model performance. We develop an evaluation protocol to assess both quality and diversity of generations against multiple references, and provide an extensive empirical study of several mixture model variants. Our analysis shows that certain types of mixture models are more robust and offer the best trade-off between translation quality and diversity compared to variational models and diverse decoding approaches.