 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlamas Know What GPTs Don't Show: Surrogate Models for Confidence Estimation
Paper and Code
Nov 15, 2023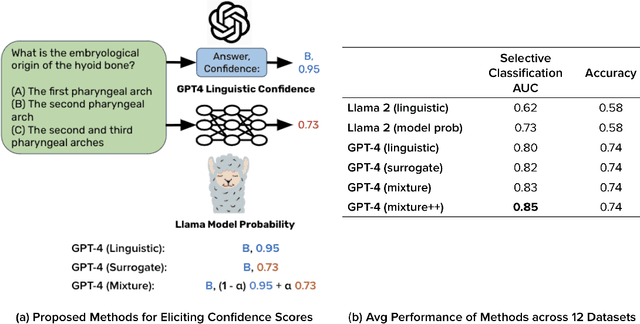
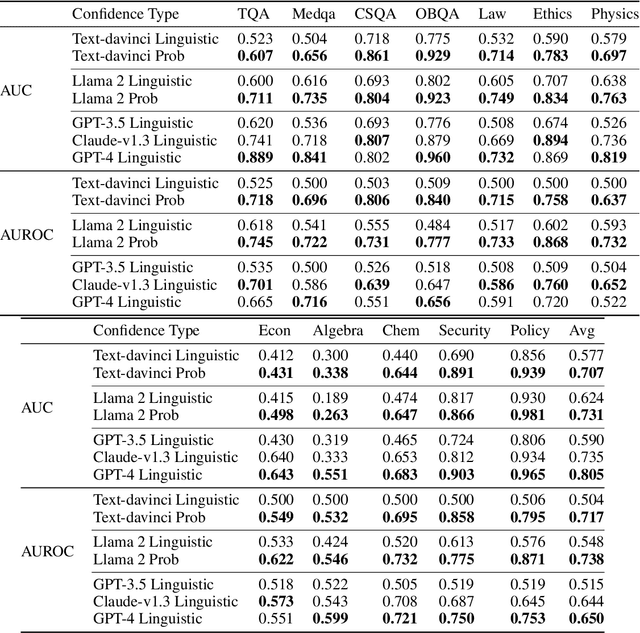

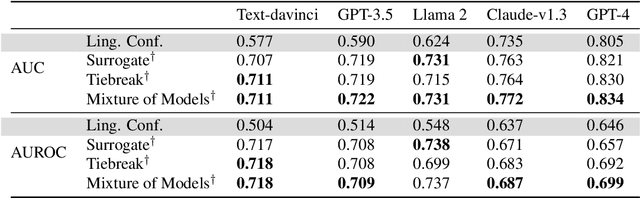
To maintain user trust, large language models (LLMs) should signal low confidence on examples where they are incorrect, instead of misleading the user. The standard approach of estimating confidence is to use the softmax probabilities of these models, but as of November 2023, state-of-the-art LLMs such as GPT-4 and Claude-v1.3 do not provide access to these probabilities. We first study eliciting confidence linguistically -- asking an LLM for its confidence in its answer -- which performs reasonably (80.5% AUC on GPT-4 averaged across 12 question-answering datasets -- 7% above a random baseline) but leaves room for improvement. We then explore using a surrogate confidence model -- using a model where we do have probabilities to evaluate the original model's confidence in a given question. Surprisingly, even though these probabilities come from a different and often weaker model, this method leads to higher AUC than linguistic confidences on 9 out of 12 datasets. Our best method composing linguistic confidences and surrogate model probabilities gives state-of-the-art confidence estimates on all 12 datasets (84.6% average AUC on GPT-4).