 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaCO: A Fast and Portable Bayesian Compiler Optimization Framework
Dec 01, 2022

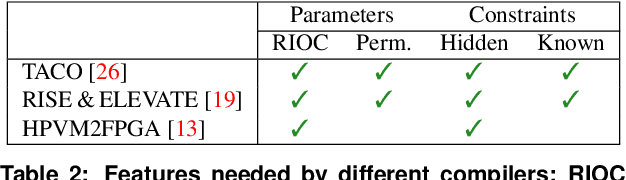
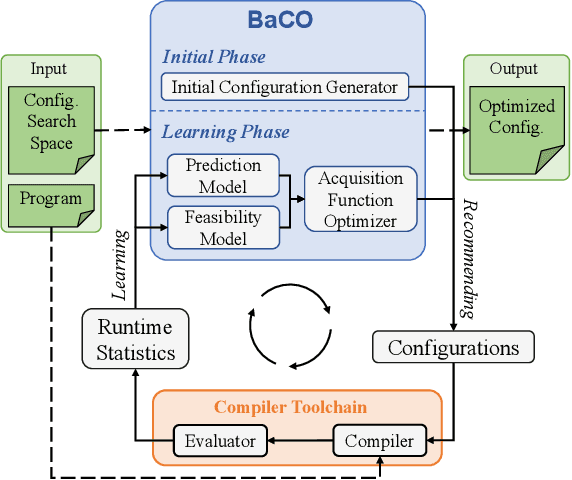
We introduce the Bayesian Compiler Optimization framework (BaCO), a general purpose autotuner for modern compilers targeting CPUs, GPUs, and FPGAs. BaCO provides the flexibility needed to handle the requirements of modern autotuning tasks. Particularly, it deals with permutation, ordered, and continuous parameter types along with both known and unknown parameter constraints. To reason about these parameter types and efficiently deliver high-quality code, BaCO uses Bayesian optimization algorithms specialized towards the autotuning domain. We demonstrate BaCO's effectiveness on three modern compiler systems: TACO, RISE & ELEVATE, and HPVM2FPGA for CPUs, GPUs, and FPGAs respectively. For these domains, BaCO outperforms current state-of-the-art autotuners by delivering on average 1.39x-1.89x faster code with a tiny search budget, and BaCO is able to reach expert-level performance 2.89x-8.77x faster.
$π$BO: Augmenting Acquisition Functions with User Beliefs for Bayesian Optimization
Apr 23, 2022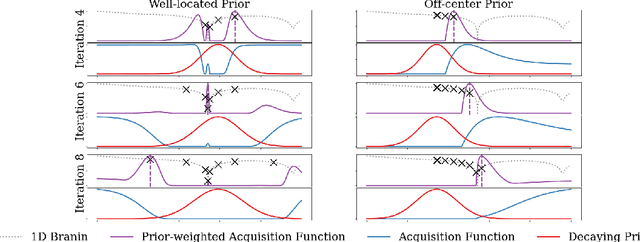
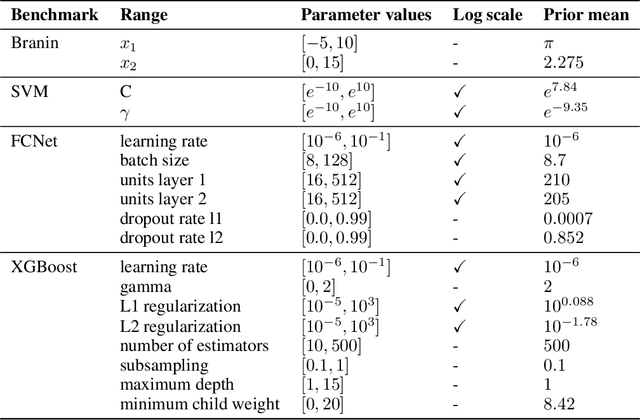
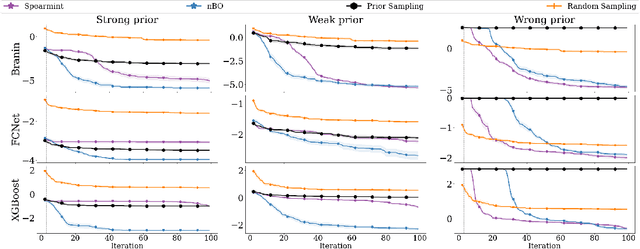

Bayesian optimization (BO) has become an established framework and popular tool for hyperparameter optimization (HPO) of machine learning (ML) algorithms. While known for its sample-efficiency, vanilla BO can not utilize readily available prior beliefs the practitioner has on the potential location of the optimum. Thus, BO disregards a valuable source of information, reducing its appeal to ML practitioners. To address this issue, we propose $\pi$BO, an acquisition function generalization which incorporates prior beliefs about the location of the optimum in the form of a probability distribution, provided by the user. In contrast to previous approaches, $\pi$BO is conceptually simple and can easily be integrated with existing libraries and many acquisition functions. We provide regret bounds when $\pi$BO is applied to the common Expected Improvement acquisition function and prove convergence at regular rates independently of the prior. Further, our experiments show that $\pi$BO outperforms competing approaches across a wide suite of benchmarks and prior characteristics. We also demonstrate that $\pi$BO improves on the state-of-the-art performance for a popular deep learning task, with a 12.5 $\times$ time-to-accuracy speedup over prominent BO approaches.
Prior-guided Bayesian Optimization
Jun 25, 2020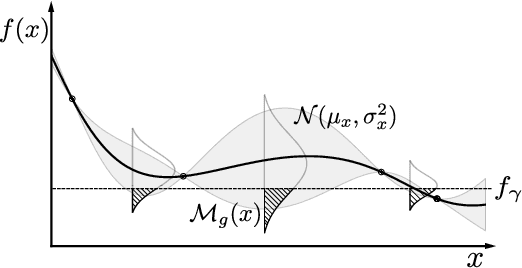
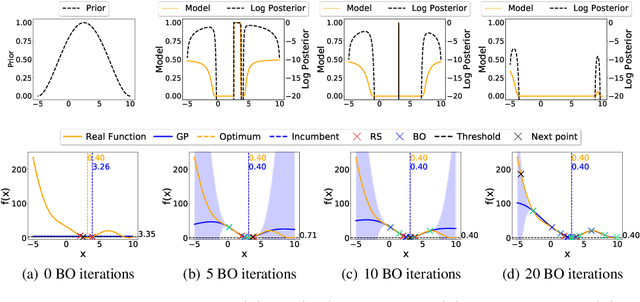
While Bayesian Optimization (BO) is a very popular method for optimizing expensive black-box functions, it fails to leverage the experience of domain experts. This causes BO to waste function evaluations on commonly known bad regions of design choices, e.g., hyperparameters of a machine learning algorithm. To address this issue, we introduce Prior-guided Bayesian Optimization (PrBO). PrBO allows users to inject their knowledge into the optimization process in the form of priors about which parts of the input space will yield the best performance, rather than BO's standard priors over functions which are much less intuitive for users. PrBO then combines these priors with BO's standard probabilistic model to yield a posterior. We show that PrBO is more sample efficient than state-of-the-art methods without user priors and 10,000$\times$ faster than random search, on a common suite of benchmarks and a real-world hardware design application. We also show that PrBO converges faster even if the user priors are not entirely accurate and that it robustly recovers from misleading priors.
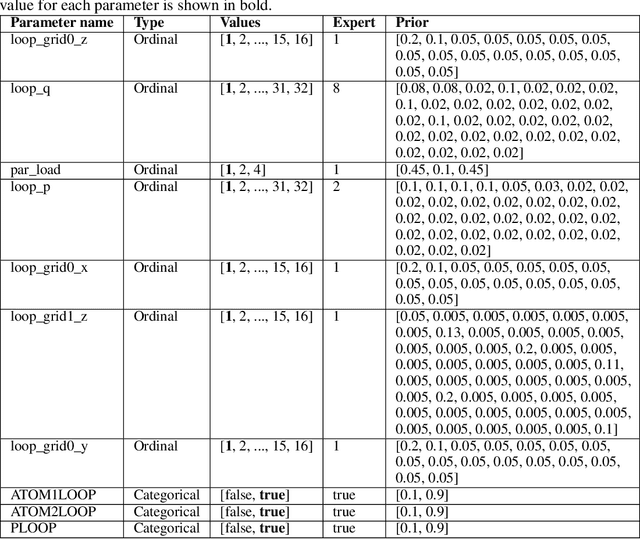
DeepFreak: Learning Crystallography Diffraction Patterns with Automated Machine Learning
May 03, 2019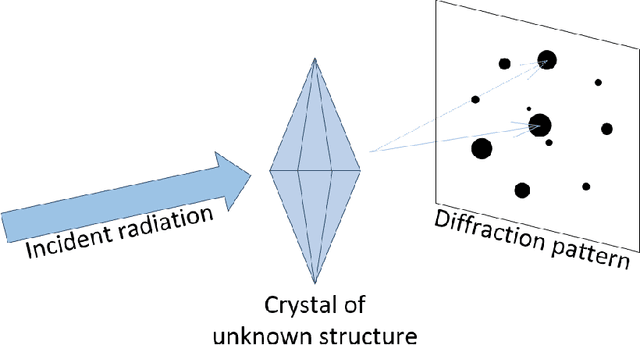

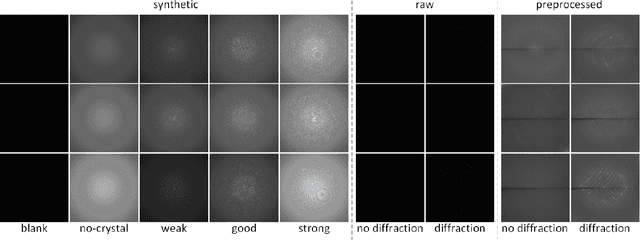
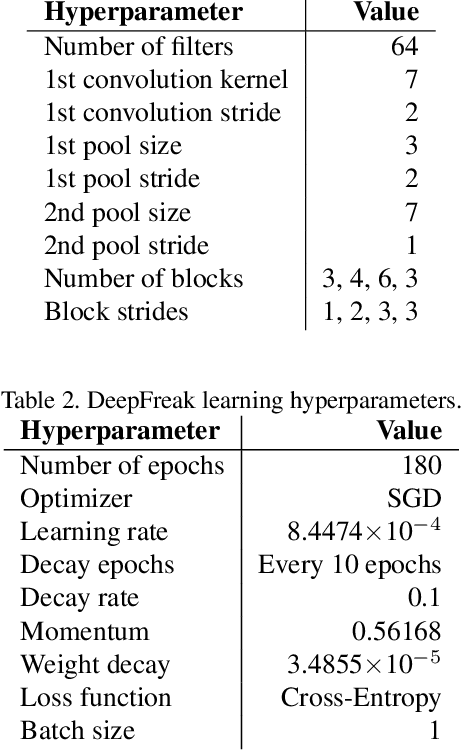
Serial crystallography is the field of science that studies the structure and properties of crystals via diffraction patterns. In this paper, we introduce a new serial crystallography dataset comprised of real and synthetic images; the synthetic images are generated through the use of a simulator that is both scalable and accurate. The resulting dataset is called DiffraNet, and it is composed of 25,457 512x512 grayscale labeled images. We explore several computer vision approaches for classification on DiffraNet such as standard feature extraction algorithms associated with Random Forests and Support Vector Machines but also an end-to-end CNN topology dubbed DeepFreak tailored to work on this new dataset. All implementations are publicly available and have been fine-tuned using off-the-shelf AutoML optimization tools for a fair comparison. Our best model achieves 98.5% accuracy on synthetic images and 94.51% accuracy on real images. We believe that the DiffraNet dataset and its classification methods will have in the long term a positive impact in accelerating discoveries in many disciplines, including chemistry, geology, biology, materials science, metallurgy, and physics.