 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Softmax Fails at the Top: Extreme Value Corrections for InfoNCE
May 29, 2026InfoNCE is the standard contrastive learning objective, but its softmax form is not only a computational convenience: it also encodes a statistical assumption about how the top-scoring example is selected. Using extreme value theory, we show that this assumption is often misaligned with the normalized embedding setting used in modern contrastive learning. Motivated by this mismatch, we propose \textsc{WEINCE}, a simple modification of InfoNCE that uses anchor-wise online batch statistics to blend the usual softmax logits with an endpoint shortfall correction, adding no trainable parameters. Across five vision benchmarks, \textsc{WEINCE} yields consistent improvements in frozen-feature evaluation. These results show that a more faithful statistical treatment of hard negatives can improve contrastive objectives.
Learning Low-Dimensional Representation for O-RAN Testing via Transformer-ESN
Apr 14, 2026Open Radio Access Network (O-RAN) architectures enhance flexibility for 6G and NextG networks. However, it also brings significant challenges in O-RAN testing with evaluating abundant, high-dimensional key performance indicators (KPIs). In this paper, we introduce a novel two-stage framework to learn temporally-aware low-dimensional representations of O-RAN testing KPIs. To be specific, stage one employs an information-theoretic H-score to train a hybrid self-attentive transformer and echo state network (ESN) reservoir, called Transformer-ESN, capturing temporal dynamics and producing task-aligned $8$-dimensional embeddings. Stage two evaluates these embeddings by training a lightweight multilayer perceptron (MLP) predictor exclusively on them for key target KPIs such as reference signal received quality (RSRQ) and spectral efficiency. Using real-world O-RAN testbed data (video streaming with interference), our approach demonstrates a significant advantage specifically when training samples are very limited. In this scenario, the low-dimensional representations learned from the Transformer-ESN yield mean square error (MSE) reductions of up to 41.9\% for RSRQ and 29.9\% for spectral efficiency compared to predictions from the original high-dimensional data. The framework exhibits high efficiency for O-RAN testing, significantly reducing testing complexities for O-RAN systems.
When Learning Hurts: Fixed-Pole RNN for Real-Time Online Training
Feb 25, 2026Recurrent neural networks (RNNs) can be interpreted as discrete-time state-space models, where the state evolution corresponds to an infinite-impulse-response (IIR) filtering operation governed by both feedforward weights and recurrent poles. While, in principle, all parameters including pole locations can be optimized via backpropagation through time (BPTT), such joint learning incurs substantial computational overhead and is often impractical for applications with limited training data. Echo state networks (ESNs) mitigate this limitation by fixing the recurrent dynamics and training only a linear readout, enabling efficient and stable online adaptation. In this work, we analytically and empirically examine why learning recurrent poles does not provide tangible benefits in data-constrained, real-time learning scenarios. Our analysis shows that pole learning renders the weight optimization problem highly non-convex, requiring significantly more training samples and iterations for gradient-based methods to converge to meaningful solutions. Empirically, we observe that for complex-valued data, gradient descent frequently exhibits prolonged plateaus, and advanced optimizers offer limited improvement. In contrast, fixed-pole architectures induce stable and well-conditioned state representations even with limited training data. Numerical results demonstrate that fixed-pole networks achieve superior performance with lower training complexity, making them more suitable for online real-time tasks.
A Universal Neural Receiver that Learns at the Speed of Wireless
Feb 17, 2026Today we design wireless networks using mathematical models that govern communication in different propagation environments. We rely on measurement campaigns to deliver parametrized propagation models, and on the 3GPP standards process to optimize model-based performance, but as wireless networks become more complex this model-based approach is losing ground. Mobile Network Operators (MNOs) are counting on Artificial Intelligence (AI) to transform wireless by increasing spectral efficiency, reducing signaling overhead, and enabling continuous network innovation through software upgrades. They may also be interested in new use cases like integrated sensing and communications (ISAC). All we need is an AI-native physical layer, so why not simply tailor the offline AI algorithms that have revolutionized image and natural language processing to the wireless domain? We argue that these algorithms rely on off-line training that is precluded by the sub-millisecond speeds at which the wireless interference environment changes. We present an alternative architecture, a universal neural receiver based on convolution, which governs transmit and receive signal processing of any signal in any part of the wireless spectrum. Our neural receiver is designed to invert convolution, and we separate the question of which convolution to invert from the actual deconvolution. The neural network that performs deconvolution is very simple, and we configure this network by setting weights based on domain knowledge. By telling our neural network what we know, we avoid extensive offline training. By developing a universal receiver, we hope to simplify discussions about the proper choice of waveform for different use cases in the international standards. Since the receiver architecture is largely independent of technologies introduced at the base station, we hope to increase the rate of innovation in wireless.
Separable Computation of Information Measures
Jan 25, 2025
We study a separable design for computing information measures, where the information measure is computed from learned feature representations instead of raw data. Under mild assumptions on the feature representations, we demonstrate that a class of information measures admit such separable computation, including mutual information, $f$-information, Wyner's common information, G{\'a}cs--K{\"o}rner common information, and Tishby's information bottleneck. Our development establishes several new connections between information measures and the statistical dependence structure. The characterizations also provide theoretical guarantees of practical designs for estimating information measures through representation learning.
AI and Deep Learning for THz Ultra-Massive MIMO: From Model-Driven Approaches to Foundation Models
Dec 13, 2024In this paper, we explore the potential of artificial intelligence (AI) to address the challenges posed by terahertz ultra-massive multiple-input multiple-output (THz UM-MIMO) systems. We begin by outlining the characteristics of THz UM-MIMO systems, and identify three primary challenges for the transceiver design: 'hard to compute', 'hard to model', and 'hard to measure'. We argue that AI can provide a promising solution to these challenges. We then propose two systematic research roadmaps for developing AI algorithms tailored for THz UM-MIMO systems. The first roadmap, called model-driven deep learning (DL), emphasizes the importance to leverage available domain knowledge and advocates for adopting AI only to enhance the bottleneck modules within an established signal processing or optimization framework. We discuss four essential steps to make it work, including algorithmic frameworks, basis algorithms, loss function design, and neural architecture design. Afterwards, we present a forward-looking vision through the second roadmap, i.e., physical layer foundation models. This approach seeks to unify the design of different transceiver modules by focusing on their common foundation, i.e., the wireless channel. We propose to train a single, compact foundation model to estimate the score function of wireless channels, which can serve as a versatile prior for designing a wide variety of transceiver modules. We will also guide the readers through four essential steps, including general frameworks, conditioning, site-specific adaptation, and the joint design of foundation models and model-driven DL.
Dependence Induced Representations
Nov 22, 2024We study the problem of learning feature representations from a pair of random variables, where we focus on the representations that are induced by their dependence. We provide sufficient and necessary conditions for such dependence induced representations, and illustrate their connections to Hirschfeld--Gebelein--R\'{e}nyi (HGR) maximal correlation functions and minimal sufficient statistics. We characterize a large family of loss functions that can learn dependence induced representations, including cross entropy, hinge loss, and their regularized variants. In particular, we show that the features learned from this family can be expressed as the composition of a loss-dependent function and the maximal correlation function, which reveals a key connection between representations learned from different losses. Our development also gives a statistical interpretation of the neural collapse phenomenon observed in deep classifiers. Finally, we present the learning design based on the feature separation, which allows hyperparameter tuning during inference.
Towards xAI: Configuring RNN Weights using Domain Knowledge for MIMO Receive Processing
Oct 09, 2024Deep learning is making a profound impact in the physical layer of wireless communications. Despite exhibiting outstanding empirical performance in tasks such as MIMO receive processing, the reasons behind the demonstrated superior performance improvement remain largely unclear. In this work, we advance the field of Explainable AI (xAI) in the physical layer of wireless communications utilizing signal processing principles. Specifically, we focus on the task of MIMO-OFDM receive processing (e.g., symbol detection) using reservoir computing (RC), a framework within recurrent neural networks (RNNs), which outperforms both conventional and other learning-based MIMO detectors. Our analysis provides a signal processing-based, first-principles understanding of the corresponding operation of the RC. Building on this fundamental understanding, we are able to systematically incorporate the domain knowledge of wireless systems (e.g., channel statistics) into the design of the underlying RNN by directly configuring the untrained RNN weights for MIMO-OFDM symbol detection. The introduced RNN weight configuration has been validated through extensive simulations demonstrating significant performance improvements. This establishes a foundation for explainable RC-based architectures in MIMO-OFDM receive processing and provides a roadmap for incorporating domain knowledge into the design of neural networks for NextG systems.
Learning at the Speed of Wireless: Online Real-Time Learning for AI-Enabled MIMO in NextG
Mar 05, 2024



Integration of artificial intelligence (AI) and machine learning (ML) into the air interface has been envisioned as a key technology for next-generation (NextG) cellular networks. At the air interface, multiple-input multiple-output (MIMO) and its variants such as multi-user MIMO (MU-MIMO) and massive/full-dimension MIMO have been key enablers across successive generations of cellular networks with evolving complexity and design challenges. Initiating active investigation into leveraging AI/ML tools to address these challenges for MIMO becomes a critical step towards an AI-enabled NextG air interface. At the NextG air interface, the underlying wireless environment will be extremely dynamic with operation adaptations performed on a sub-millisecond basis by MIMO operations such as MU-MIMO scheduling and rank/link adaptation. Given the enormously large number of operation adaptation possibilities, we contend that online real-time AI/ML-based approaches constitute a promising paradigm. To this end, we outline the inherent challenges and offer insights into the design of such online real-time AI/ML-based solutions for MIMO operations. An online real-time AI/ML-based method for MIMO-OFDM channel estimation is then presented, serving as a potential roadmap for developing similar techniques across various MIMO operations in NextG.
Operator SVD with Neural Networks via Nested Low-Rank Approximation
Feb 06, 2024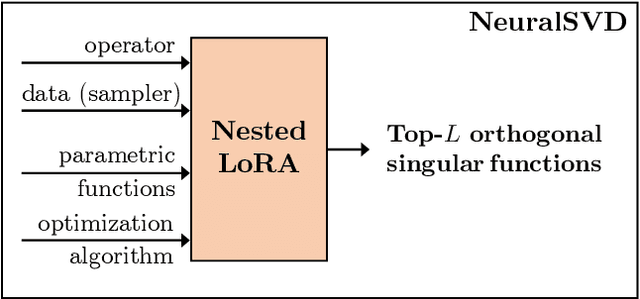
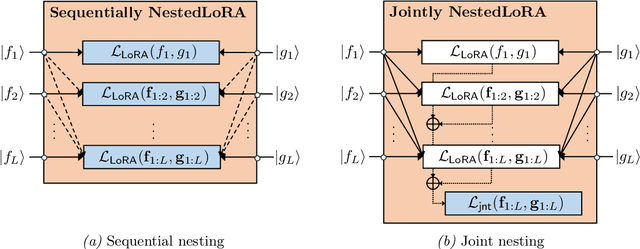

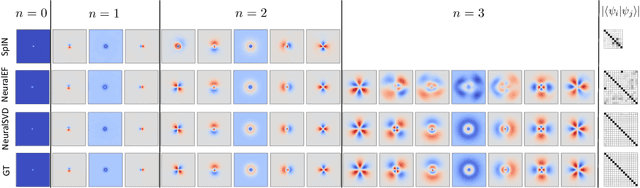
Computing eigenvalue decomposition (EVD) of a given linear operator, or finding its leading eigenvalues and eigenfunctions, is a fundamental task in many machine learning and scientific computing problems. For high-dimensional eigenvalue problems, training neural networks to parameterize the eigenfunctions is considered as a promising alternative to the classical numerical linear algebra techniques. This paper proposes a new optimization framework based on the low-rank approximation characterization of a truncated singular value decomposition, accompanied by new techniques called nesting for learning the top-$L$ singular values and singular functions in the correct order. The proposed method promotes the desired orthogonality in the learned functions implicitly and efficiently via an unconstrained optimization formulation, which is easy to solve with off-the-shelf gradient-based optimization algorithms. We demonstrate the effectiveness of the proposed optimization framework for use cases in computational physics and machine learning.