 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalog RF Computing: A New Paradigm for Energy-Efficient Edge AI Over MU-MIMO Systems
May 14, 2026Modern edge devices increasingly rely on neural networks for intelligent applications. However, conventional digital computing-based edge inference requires substantial memory and energy consumption. In analog radio frequency (RF) computing, a base station (BS) encodes the weights of the neural networks and broadcasts the RF waveforms to the clients. Each client reuses its passive mixer to multiply the received weight-encoded waveform with a locally generated input-encoded waveform. This enables wireless receivers to perform the matrix-vector multiplications (MVMs) that account for most of the computation burden in edge inference with ultra-low energy consumption. Unlike conventional downlink transmissions which are optimized for communications, analog RF computing requires a computing-centric physical layer that controls both the analog MVM accuracy and the energy consumption for inference. Motivated by this, in this paper, we propose a physical layer design framework for analog RF computing in MU-MIMO wireless systems. We derive tractable models for computing accuracy and energy consumption for inference, formulate a joint BS beamforming and client-side scaling problem subject to computing accuracy, transmit power, and hardware constraints, and develop a low-complexity algorithm to solve the non-convex problem. The proposed design provides client- and layer-specific accuracy control for both uniform- and mixed-precision inference. Simulations under 3GPP specifications show that analog RF computing can significantly reduce client-side energy consumption by nearly two orders of magnitude compared to digital computing, while mixed-precision inference requires even lower energy consumption than uniform-precision inference. Overall, these results establish analog RF computing over wireless networks as a promising paradigm for energy-efficient edge inference.
Beyond Rigid Alignment: Graph Federated Learning via Dual Manifold Calibration
May 07, 2026Graph Federated Learning (GFL) enables collaborative representation learning across distributed subgraphs while preserving privacy. However, heterogeneity remains a critical challenge, as subgraphs across clients typically differ significantly in both semantics and structures. Existing methods address heterogeneity by enforcing the rigid alignment of model parameters or prototypes between clients and the server. However, these alignments implicitly rely on a restrictive global linearity assumption that summarizes local data distributions using a single and globally consistent representation space. This severely compresses the personalized representation space of clients and fails to preserve diverse local graph distributions. To overcome these limitations, we propose Federated Graph Manifold Calibration (FedGMC), a novel paradigm that tackles semantic heterogeneity and structural heterogeneity from a unified manifold perspective. Instead of enforcing rigid alignment, FedGMC introduces a dual manifold calibration mechanism that preserves global commonalities while maximizing the personalized representation space of local clients. Specifically, for semantic heterogeneity, the server constructs a geometrically optimal semantic manifold via equidistant semantic anchors, so as to guide the calibration of local semantic manifolds. For structural heterogeneity, the server constructs a global structural manifold by building global structural templates, so as to guide the calibration of local structural manifolds. Finally, the server dynamically refines both global semantic manifolds and structural manifolds by aggregating local manifolds. Extensive experiments on eleven homophilic and heterophilic graphs demonstrate that FedGMC effectively balances global commonality and local personalization, thereby significantly outperforming state-of-the-art baseline methods.
Graph Federated Unlearning for Privacy Preservation
May 04, 2026Graph federated learning (GFL) facilitates decentralized training on distributed graph data while keeping sensitive user information local, aligning with policies such as GDPR and CCPA that grant users the right to freely join or withdraw from learning systems. However, even decentralized, user information can persist after quitting, potentially propagating to central servers and then redistributing to malicious clients. This privacy leakage during user withdrawal, despite its importance, has received seldom attention in GFL. To fill the gap, we explore the potential of machine unlearning (MU) to thoroughly remove user information. However, classical MU methods are known to degrade overall performance, a problem that is exacerbated in GFL due to local message passing and global model collaboration. To this end, we make two adjustments to mitigate this challenge for GFL. First, we ensure unlearning updates that minimally affect overall performance, steering them in directions orthogonal to the gradients from learning other data. Second, we introduce virtual clients, maintained by the central server, to preserve graph topology and global embeddings without recovering information of removed entities. We conduct comprehensive experiments under a representative user-withdrawal scenario and propose a novel membership inference framework to rigorously evaluate and validate the reliability of our privacy preservation. The experimental results demonstrate the effectiveness of our approach, which also surpasses the performance of seven state-of-the-art baseline methods.
Heterogeneity-Aware Knowledge Sharing for Graph Federated Learning
Jan 29, 2026Graph Federated Learning (GFL) enables distributed graph representation learning while protecting the privacy of graph data. However, GFL suffers from heterogeneity arising from diverse node features and structural topologies across multiple clients. To address both types of heterogeneity, we propose a novel graph Federated learning method via Semantic and Structural Alignment (FedSSA), which shares the knowledge of both node features and structural topologies. For node feature heterogeneity, we propose a novel variational model to infer class-wise node distributions, so that we can cluster clients based on inferred distributions and construct cluster-level representative distributions. We then minimize the divergence between local and cluster-level distributions to facilitate semantic knowledge sharing. For structural heterogeneity, we employ spectral Graph Neural Networks (GNNs) and propose a spectral energy measure to characterize structural information, so that we can cluster clients based on spectral energy and build cluster-level spectral GNNs. We then align the spectral characteristics of local spectral GNNs with those of cluster-level spectral GNNs to enable structural knowledge sharing. Experiments on six homophilic and five heterophilic graph datasets under both non-overlapping and overlapping partitioning settings demonstrate that FedSSA consistently outperforms eleven state-of-the-art methods.
Multimodal Deep Learning-Empowered Beam Prediction in Future THz ISAC Systems
May 05, 2025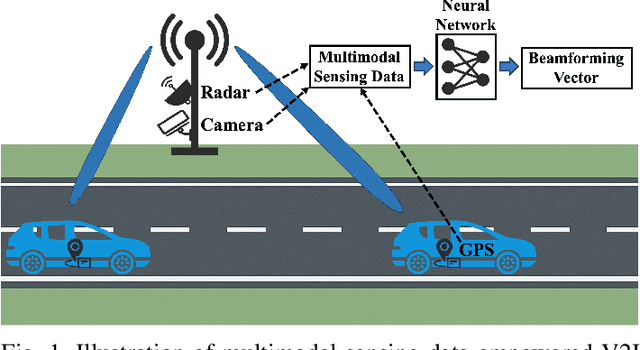
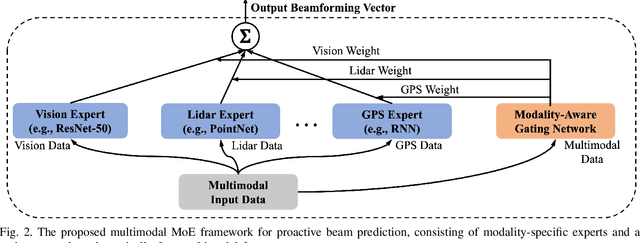
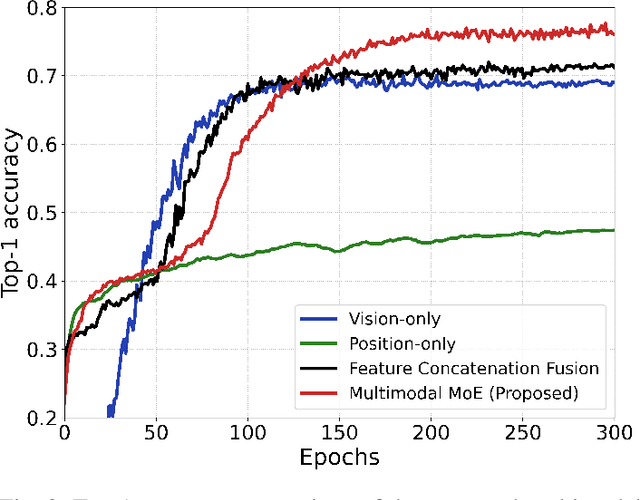
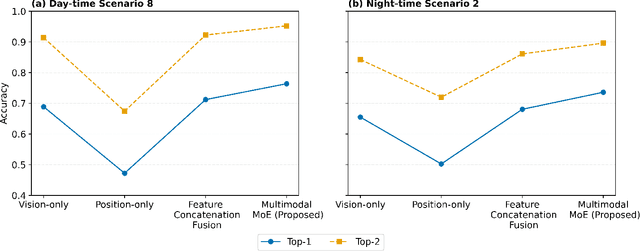
Integrated sensing and communication (ISAC) systems operating at terahertz (THz) bands are envisioned to enable both ultra-high data-rate communication and precise environmental awareness for next-generation wireless networks. However, the narrow width of THz beams makes them prone to misalignment and necessitates frequent beam prediction in dynamic environments. Multimodal sensing, which integrates complementary modalities such as camera images, positional data, and radar measurements, has recently emerged as a promising solution for proactive beam prediction. Nevertheless, existing multimodal approaches typically employ static fusion architectures that cannot adjust to varying modality reliability and contributions, thereby degrading predictive performance and robustness. To address this challenge, we propose a novel and efficient multimodal mixture-of-experts (MoE) deep learning framework for proactive beam prediction in THz ISAC systems. The proposed multimodal MoE framework employs multiple modality-specific expert networks to extract representative features from individual sensing modalities, and dynamically fuses them using adaptive weights generated by a gating network according to the instantaneous reliability of each modality. Simulation results in realistic vehicle-to-infrastructure (V2I) scenarios demonstrate that the proposed MoE framework outperforms traditional static fusion methods and unimodal baselines in terms of prediction accuracy and adaptability, highlighting its potential in practical THz ISAC systems with ultra-massive multiple-input multiple-output (MIMO).
Homophily Heterogeneity Matters in Graph Federated Learning: A Spectrum Sharing and Complementing Perspective
Feb 19, 2025

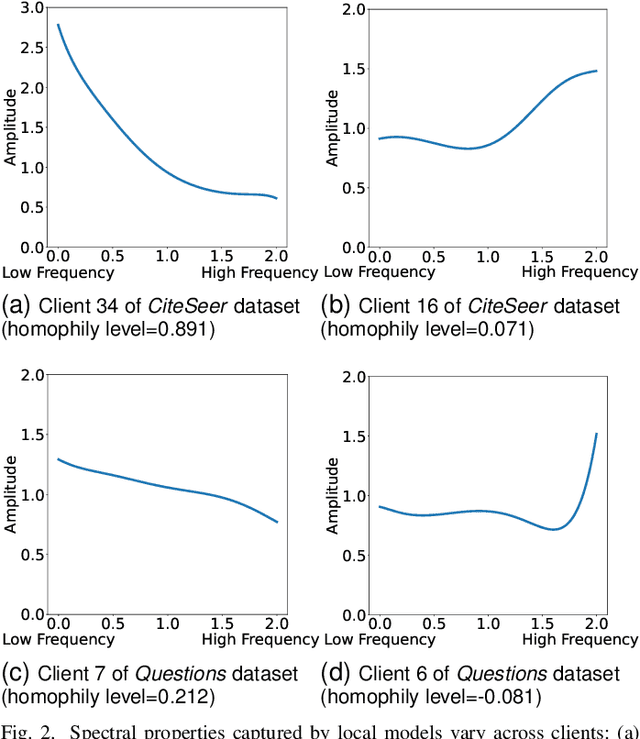

Since heterogeneity presents a fundamental challenge in graph federated learning, many existing methods are proposed to deal with node feature heterogeneity and structure heterogeneity. However, they overlook the critical homophily heterogeneity, which refers to the substantial variation in homophily levels across graph data from different clients. The homophily level represents the proportion of edges connecting nodes that belong to the same class. Due to adapting to their local homophily, local models capture inconsistent spectral properties across different clients, significantly reducing the effectiveness of collaboration. Specifically, local models trained on graphs with high homophily tend to capture low-frequency information, whereas local models trained on graphs with low homophily tend to capture high-frequency information. To effectively deal with homophily heterophily, we introduce the spectral Graph Neural Network (GNN) and propose a novel Federated learning method by mining Graph Spectral Properties (FedGSP). On one hand, our proposed FedGSP enables clients to share generic spectral properties (i.e., low-frequency information), allowing all clients to benefit through collaboration. On the other hand, inspired by our theoretical findings, our proposed FedGSP allows clients to complement non-generic spectral properties by acquiring the spectral properties they lack (i.e., high-frequency information), thereby obtaining additional information gain. Extensive experiments conducted on six homophilic and five heterophilic graph datasets, across both non-overlapping and overlapping settings, validate the superiority of our method over eleven state-of-the-art methods. Notably, our FedGSP outperforms the second-best method by an average margin of 3.28% on all heterophilic datasets.
Modeling Inter-Intra Heterogeneity for Graph Federated Learning
Dec 16, 2024



Heterogeneity is a fundamental and challenging issue in federated learning, especially for the graph data due to the complex relationships among the graph nodes. To deal with the heterogeneity, lots of existing methods perform the weighted federation based on their calculated similarities between pairwise clients (i.e., subgraphs). However, their inter-subgraph similarities estimated with the outputs of local models are less reliable, because the final outputs of local models may not comprehensively represent the real distribution of subgraph data. In addition, they ignore the critical intra-heterogeneity which usually exists within each subgraph itself. To address these issues, we propose a novel Federated learning method by integrally modeling the Inter-Intra Heterogeneity (FedIIH). For the inter-subgraph relationship, we propose a novel hierarchical variational model to infer the whole distribution of subgraph data in a multi-level form, so that we can accurately characterize the inter-subgraph similarities with the global perspective. For the intra-heterogeneity, we disentangle the subgraph into multiple latent factors and partition the model parameters into multiple parts, where each part corresponds to a single latent factor. Our FedIIH not only properly computes the distribution similarities between subgraphs, but also learns disentangled representations that are robust to irrelevant factors within subgraphs, so that it successfully considers the inter- and intra- heterogeneity simultaneously. Extensive experiments on six homophilic and five heterophilic graph datasets in both non-overlapping and overlapping settings demonstrate the effectiveness of our method when compared with nine state-of-the-art methods. Specifically, FedIIH averagely outperforms the second-best method by a large margin of 5.79% on all heterophilic datasets.
AI and Deep Learning for THz Ultra-Massive MIMO: From Model-Driven Approaches to Foundation Models
Dec 13, 2024In this paper, we explore the potential of artificial intelligence (AI) to address the challenges posed by terahertz ultra-massive multiple-input multiple-output (THz UM-MIMO) systems. We begin by outlining the characteristics of THz UM-MIMO systems, and identify three primary challenges for the transceiver design: 'hard to compute', 'hard to model', and 'hard to measure'. We argue that AI can provide a promising solution to these challenges. We then propose two systematic research roadmaps for developing AI algorithms tailored for THz UM-MIMO systems. The first roadmap, called model-driven deep learning (DL), emphasizes the importance to leverage available domain knowledge and advocates for adopting AI only to enhance the bottleneck modules within an established signal processing or optimization framework. We discuss four essential steps to make it work, including algorithmic frameworks, basis algorithms, loss function design, and neural architecture design. Afterwards, we present a forward-looking vision through the second roadmap, i.e., physical layer foundation models. This approach seeks to unify the design of different transceiver modules by focusing on their common foundation, i.e., the wireless channel. We propose to train a single, compact foundation model to estimate the score function of wireless channels, which can serve as a versatile prior for designing a wide variety of transceiver modules. We will also guide the readers through four essential steps, including general frameworks, conditioning, site-specific adaptation, and the joint design of foundation models and model-driven DL.
Bayes-Optimal Unsupervised Learning for Channel Estimation in Near-Field Holographic MIMO
Dec 16, 2023



Holographic MIMO (HMIMO) is being increasingly recognized as a key enabling technology for 6G wireless systems through the deployment of an extremely large number of antennas within a compact space to fully exploit the potentials of the electromagnetic (EM) channel. Nevertheless, the benefits of HMIMO systems cannot be fully unleashed without an efficient means to estimate the high-dimensional channel, whose distribution becomes increasingly complicated due to the accessibility of the near-field region. In this paper, we address the fundamental challenge of designing a low-complexity Bayes-optimal channel estimator in near-field HMIMO systems operating in unknown EM environments. The core idea is to estimate the HMIMO channels solely based on the Stein's score function of the received pilot signals and an estimated noise level, without relying on priors or supervision that is not feasible in practical deployment. A neural network is trained with the unsupervised denoising score matching objective to learn the parameterized score function. Meanwhile, a principal component analysis (PCA)-based algorithm is proposed to estimate the noise level leveraging the low-rank near-field spatial correlation. Building upon these techniques, we develop a Bayes-optimal score-based channel estimator for fully-digital HMIMO transceivers in a closed form. The optimal score-based estimator is also extended to hybrid analog-digital HMIMO systems by incorporating it into a low-complexity message passing algorithm. The (quasi-) Bayes-optimality of the proposed estimators is validated both in theory and by extensive simulation results. In addition to optimality, it is shown that our proposal is robust to various mismatches and can quickly adapt to dynamic EM environments in an online manner thanks to its unsupervised nature, demonstrating its potential in real-world deployment.
Learning Bayes-Optimal Channel Estimation for Holographic MIMO in Unknown EM Environments
Nov 14, 2023



Holographic MIMO (HMIMO) has recently been recognized as a promising enabler for future 6G systems through the use of an ultra-massive number of antennas in a compact space to exploit the propagation characteristics of the electromagnetic (EM) channel. Nevertheless, the promised gain of HMIMO could not be fully unleashed without an efficient means to estimate the high-dimensional channel. Bayes-optimal estimators typically necessitate either a large volume of supervised training samples or a priori knowledge of the true channel distribution, which could hardly be available in practice due to the enormous system scale and the complicated EM environments. It is thus important to design a Bayes-optimal estimator for the HMIMO channels in arbitrary and unknown EM environments, free of any supervision or priors. This work proposes a self-supervised minimum mean-square-error (MMSE) channel estimation algorithm based on powerful machine learning tools, i.e., score matching and principal component analysis. The training stage requires only the pilot signals, without knowing the spatial correlation, the ground-truth channels, or the received signal-to-noise-ratio. Simulation results will show that, even being totally self-supervised, the proposed algorithm can still approach the performance of the oracle MMSE method with an extremely low complexity, making it a competitive candidate in practice.