 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrast encodes inductive bias: separating slow noise from dynamics in predictive representation learning
Jun 05, 2026Self-supervised methods that learn representations and predict dynamics fully in the latent space, such as JEPA, have been shown to confuse slowly varying noise with the dynamical signals they aim to capture. Specifically, when noise features remain approximately constant within each trajectory, contrastive predictive objectives preferentially encode these features instead of the true latent variables governing the system. The learned representation then becomes dominated by trajectory-specific noise, so downstream performance degrades with noise strength and does not improve even as the number and duration of training trajectories increase. We argue that this failure is a property of the objective itself, shared by a long line of contrastive predictive objectives that sample negatives across trajectories. To illustrate this generality, we study the failure mode and its remedy in two settings: a standard SimCLR-style JEPA on a synthetic moving-dot dataset, and DySIB, a recently introduced method designed for extracting physically interpretable representations of dynamics, on movies of a rigid-body pendulum. When negatives are instead sampled within a single trajectory, the slow noise can no longer distinguish frames within that trajectory, removing the predictive shortcut. Training one encoder simultaneously on many such trajectories then forces it to encode the variables relevant for the dynamics, with longer trajectories yielding better representations even for strong slow noise. Our results point toward principles for designing contrastive predictive objectives in dynamical representation learning, especially for physical systems with noisy experimental observations.
Information bottleneck for learning the phase space of dynamics from high-dimensional experimental data
Apr 27, 2026Identifying the dynamical state variables of a system from high-dimensional observations is a central problem across physical sciences. The challenge is that the state variables are not directly observable and must be inferred from raw high-dimensional data without supervision. Here we introduce DySIB (Dynamical Symmetric Information Bottleneck) as a method to learn low-dimensional representations of time-series data by maximizing predictive mutual information between past and future observation windows while penalizing representation complexity. This objective operates entirely in latent space and avoids reconstruction of the observations. We apply DySIB to an experimental video dataset of a physical pendulum, where the underlying state space is known. The method, with hyperparameters of the learning architecture set self-consistently by the data, recovers a two-dimensional representation that matches the dimensionality, topology, and geometry of the pendulum phase space, with the learned coordinates aligning smoothly with the canonical angle and angular velocity. These results demonstrate, on a well-characterized experimental system, that predictive information in latent space can be used to recover interpretable dynamical coordinates directly from high-dimensional data.
Multi-Agent Empowerment and Emergence of Complex Behavior in Groups
Apr 22, 2026Intrinsic motivations are receiving increasing attention, i.e. behavioral incentives that are not engineered, but emerge from the interaction of an agent with its surroundings. In this work we study the emergence of behaviors driven by one such incentive, empowerment, specifically in the context of more than one agent. We formulate a principled extension of empowerment to the multi-agent setting, and demonstrate its efficient calculation. We observe that this intrinsic motivation gives rise to characteristic modes of group-organization in two qualitatively distinct environments: a pair of agents coupled by a tendon, and a controllable Vicsek flock. This demonstrates the potential of intrinsic motivations such as empowerment to not just drive behavior for only individual agents but also higher levels of behavioral organization at scale.
Mutual information and task-relevant latent dimensionality
Feb 08, 2026Estimating the dimensionality of the latent representation needed for prediction -- the task-relevant dimension -- is a difficult, largely unsolved problem with broad scientific applications. We cast it as an Information Bottleneck question: what embedding bottleneck dimension is sufficient to compress predictor and predicted views while preserving their mutual information (MI). This repurposes neural MI estimators for dimensionality estimation. We show that standard neural estimators with separable/bilinear critics systematically inflate the inferred dimension, and we address this by introducing a hybrid critic that retains an explicit dimensional bottleneck while allowing flexible nonlinear cross-view interactions, thereby preserving the latent geometry. We further propose a one-shot protocol that reads off the effective dimension from a single over-parameterized hybrid model, without sweeping over bottleneck sizes. We validate the approach on synthetic problems with known task-relevant dimension. We extend the approach to intrinsic dimensionality by constructing paired views of a single dataset, enabling comparison with classical geometric dimension estimators. In noisy regimes where those estimators degrade, our approach remains reliable. Finally, we demonstrate the utility of the method on multiple physics datasets.
Better Together: Cross and Joint Covariances Enhance Signal Detectability in Undersampled Data
Jul 29, 2025Many data-science applications involve detecting a shared signal between two high-dimensional variables. Using random matrix theory methods, we determine when such signal can be detected and reconstructed from sample correlations, despite the background of sampling noise induced correlations. We consider three different covariance matrices constructed from two high-dimensional variables: their individual self covariance, their cross covariance, and the self covariance of the concatenated (joint) variable, which incorporates the self and the cross correlation blocks. We observe the expected Baik, Ben Arous, and P\'ech\'e detectability phase transition in all these covariance matrices, and we show that joint and cross covariance matrices always reconstruct the shared signal earlier than the self covariances. Whether the joint or the cross approach is better depends on the mismatch of dimensionalities between the variables. We discuss what these observations mean for choosing the right method for detecting linear correlations in data and how these findings may generalize to nonlinear statistical dependencies.
Learning force laws in many-body systems
Oct 08, 2023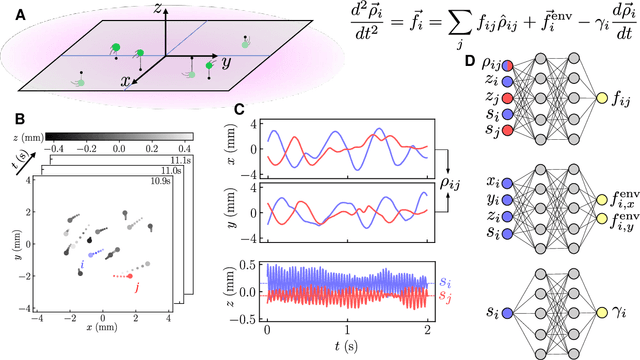
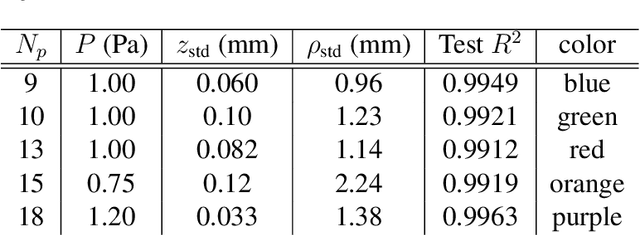
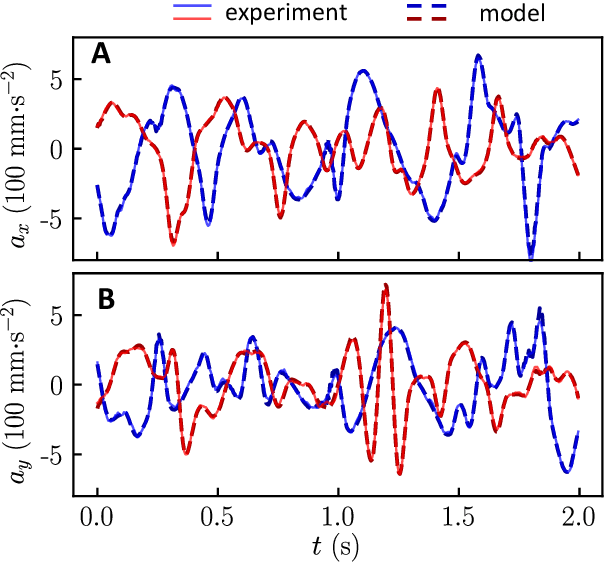
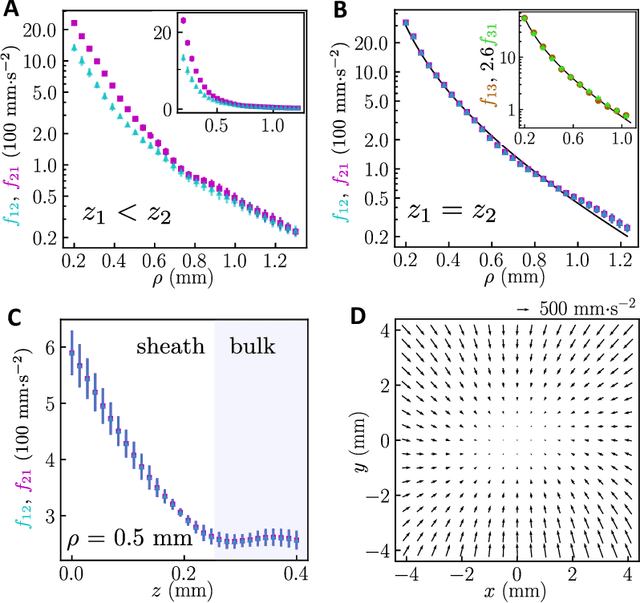
Scientific laws describing natural systems may be more complex than our intuition can handle, and thus how we discover laws must change. Machine learning (ML) models can analyze large quantities of data, but their structure should match the underlying physical constraints to provide useful insight. Here we demonstrate a ML approach that incorporates such physical intuition to infer force laws in dusty plasma experiments. Trained on 3D particle trajectories, the model accounts for inherent symmetries and non-identical particles, accurately learns the effective non-reciprocal forces between particles, and extracts each particle's mass and charge. The model's accuracy (R^2 > 0.99) points to new physics in dusty plasma beyond the resolution of current theories and demonstrates how ML-powered approaches can guide new routes of scientific discovery in many-body systems.
Simultaneous Dimensionality Reduction: A Data Efficient Approach for Multimodal Representations Learning
Oct 05, 2023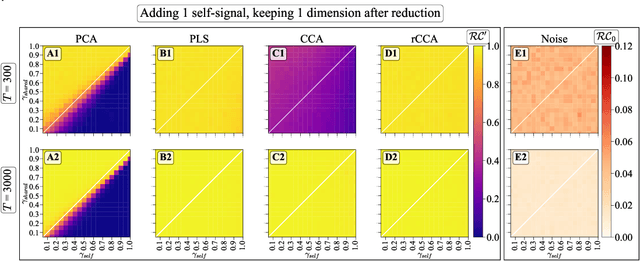
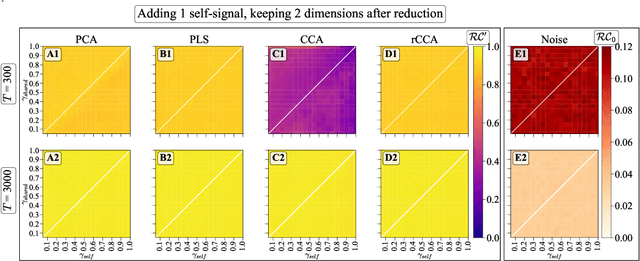
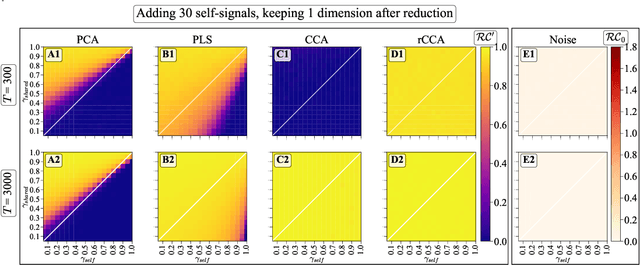
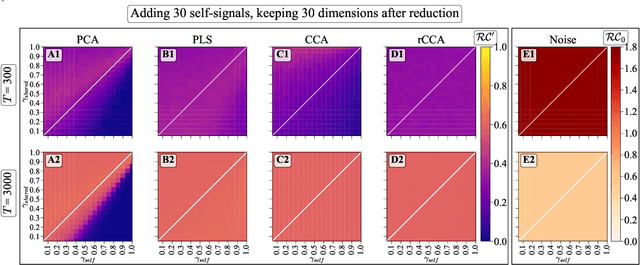
We explore two primary classes of approaches to dimensionality reduction (DR): Independent Dimensionality Reduction (IDR) and Simultaneous Dimensionality Reduction (SDR). In IDR methods, of which Principal Components Analysis is a paradigmatic example, each modality is compressed independently, striving to retain as much variation within each modality as possible. In contrast, in SDR, one simultaneously compresses the modalities to maximize the covariation between the reduced descriptions while paying less attention to how much individual variation is preserved. Paradigmatic examples include Partial Least Squares and Canonical Correlations Analysis. Even though these DR methods are a staple of statistics, their relative accuracy and data set size requirements are poorly understood. We introduce a generative linear model to synthesize multimodal data with known variance and covariance structures to examine these questions. We assess the accuracy of the reconstruction of the covariance structures as a function of the number of samples, signal-to-noise ratio, and the number of varying and covarying signals in the data. Using numerical experiments, we demonstrate that linear SDR methods consistently outperform linear IDR methods and yield higher-quality, more succinct reduced-dimensional representations with smaller datasets. Remarkably, regularized CCA can identify low-dimensional weak covarying structures even when the number of samples is much smaller than the dimensionality of the data, which is a regime challenging for all dimensionality reduction methods. Our work corroborates and explains previous observations in the literature that SDR can be more effective in detecting covariation patterns in data. These findings suggest that SDR should be preferred to IDR in real-world data analysis when detecting covariation is more important than preserving variation.
Deep Variational Multivariate Information Bottleneck -- A Framework for Variational Losses
Oct 05, 2023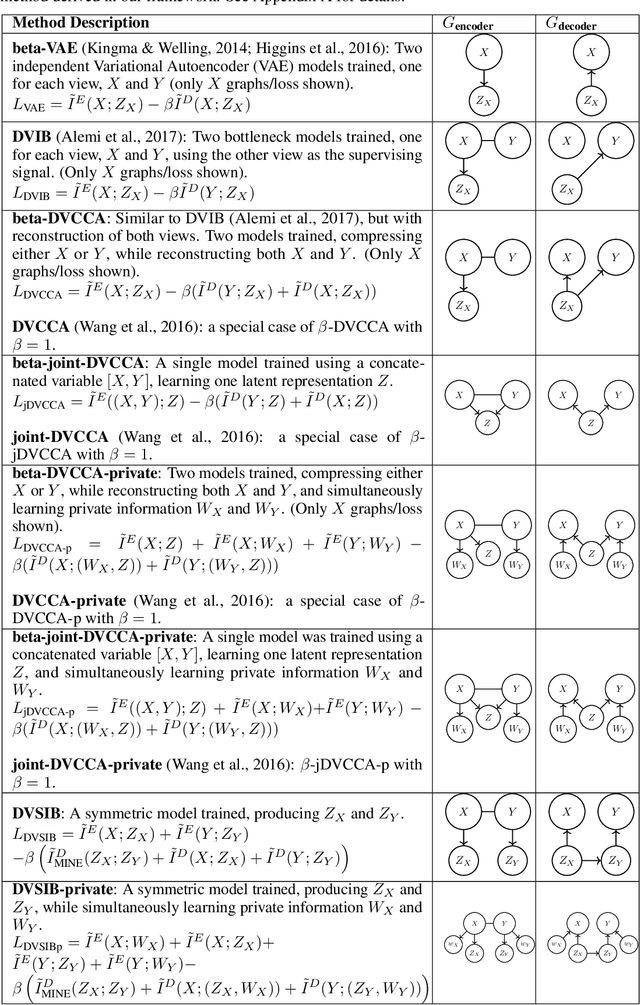

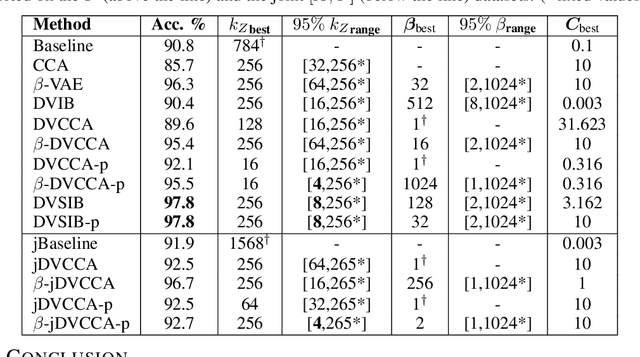
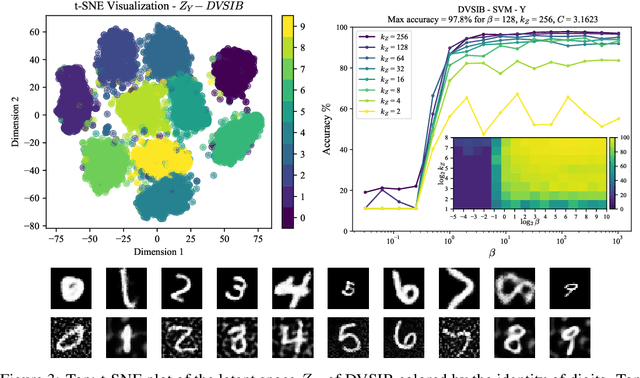
Variational dimensionality reduction methods are known for their high accuracy, generative abilities, and robustness. These methods have many theoretical justifications. Here we introduce a unifying principle rooted in information theory to rederive and generalize existing variational methods and design new ones. We base our framework on an interpretation of the multivariate information bottleneck, in which two Bayesian networks are traded off against one another. We interpret the first network as an encoder graph, which specifies what information to keep when compressing the data. We interpret the second network as a decoder graph, which specifies a generative model for the data. Using this framework, we rederive existing dimensionality reduction methods such as the deep variational information bottleneck (DVIB), beta variational auto-encoders (beta-VAE), and deep variational canonical correlation analysis (DVCCA). The framework naturally introduces a trade-off parameter between compression and reconstruction in the DVCCA family of algorithms, resulting in the new beta-DVCCA family. In addition, we derive a new variational dimensionality reduction method, deep variational symmetric informational bottleneck (DVSIB), which simultaneously compresses two variables to preserve information between their compressed representations. We implement all of these algorithms and evaluate their ability to produce shared low dimensional latent spaces on a modified noisy MNIST dataset. We show that algorithms that are better matched to the structure of the data (beta-DVCCA and DVSIB) produce better latent spaces as measured by classification accuracy and the dimensionality of the latent variables. We believe that this framework can be used to unify other multi-view representation learning algorithms. Additionally, it provides a straightforward framework for deriving problem-specific loss functions.
Data efficiency, dimensionality reduction, and the generalized symmetric information bottleneck
Sep 11, 2023The Symmetric Information Bottleneck (SIB), an extension of the more familiar Information Bottleneck, is a dimensionality reduction technique that simultaneously compresses two random variables to preserve information between their compressed versions. We introduce the Generalized Symmetric Information Bottleneck (GSIB), which explores different functional forms of the cost of such simultaneous reduction. We then explore the dataset size requirements of such simultaneous compression. We do this by deriving bounds and root-mean-squared estimates of statistical fluctuations of the involved loss functions. We show that, in typical situations, the simultaneous GSIB compression requires qualitatively less data to achieve the same errors compared to compressing variables one at a time. We suggest that this is an example of a more general principle that simultaneous compression is more data efficient than independent compression of each of the input variables.
Inferring Local Structure from Pairwise Correlations
May 07, 2023



To construct models of large, multivariate complex systems, such as those in biology, one needs to constrain which variables are allowed to interact. This can be viewed as detecting ``local'' structures among the variables. In the context of a simple toy model of 2D natural and synthetic images, we show that pairwise correlations between the variables -- even when severely undersampled -- provide enough information to recover local relations, including the dimensionality of the data, and to reconstruct arrangement of pixels in fully scrambled images. This proves to be successful even though higher order interaction structures are present in our data. We build intuition behind the success, which we hope might contribute to modeling complex, multivariate systems and to explaining the success of modern attention-based machine learning approaches.