 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Dimensionality Reduction for Extracting Useful Representations of Large Empirical Multimodal Datasets
Oct 23, 2024The quest for simplification in physics drives the exploration of concise mathematical representations for complex systems. This Dissertation focuses on the concept of dimensionality reduction as a means to obtain low-dimensional descriptions from high-dimensional data, facilitating comprehension and analysis. We address the challenges posed by real-world data that defy conventional assumptions, such as complex interactions within neural systems or high-dimensional dynamical systems. Leveraging insights from both theoretical physics and machine learning, this work unifies diverse reduction methods under a comprehensive framework, the Deep Variational Multivariate Information Bottleneck. This framework enables the design of tailored reduction algorithms based on specific research questions. We explore and assert the efficacy of simultaneous reduction approaches over their independent reduction counterparts, demonstrating their superiority in capturing covariation between multiple modalities, while requiring less data. We also introduced novel techniques, such as the Deep Variational Symmetric Information Bottleneck, for general nonlinear simultaneous reduction. We show that the same principle of simultaneous reduction is the key to efficient estimation of mutual information. We show that our new method is able to discover the coordinates of high-dimensional observations of dynamical systems. Through analytical investigations and empirical validations, we shed light on the intricacies of dimensionality reduction methods, paving the way for enhanced data analysis across various domains. We underscore the potential of these methodologies to extract meaningful insights from complex datasets, driving advancements in fundamental research and applied sciences. As these methods evolve, they promise to deepen our understanding of complex systems and inform more effective data analysis strategies.
Learning force laws in many-body systems
Oct 08, 2023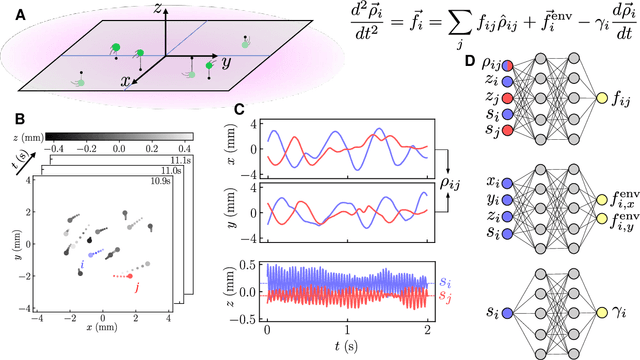
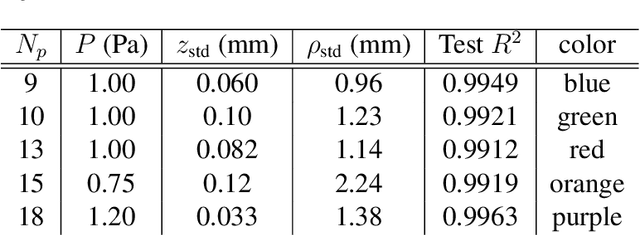
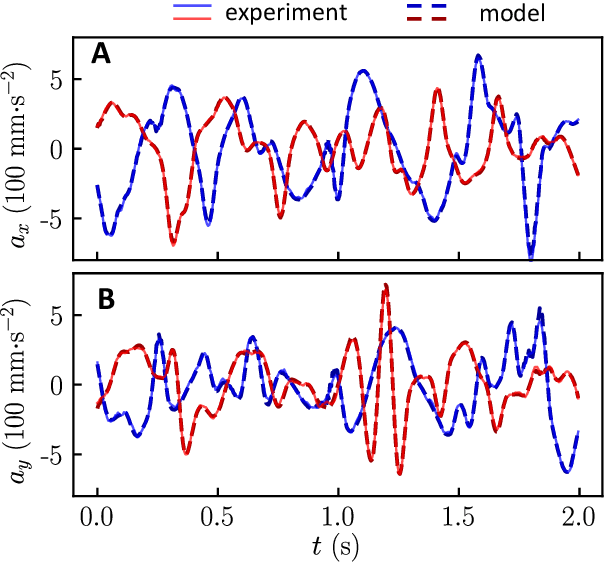
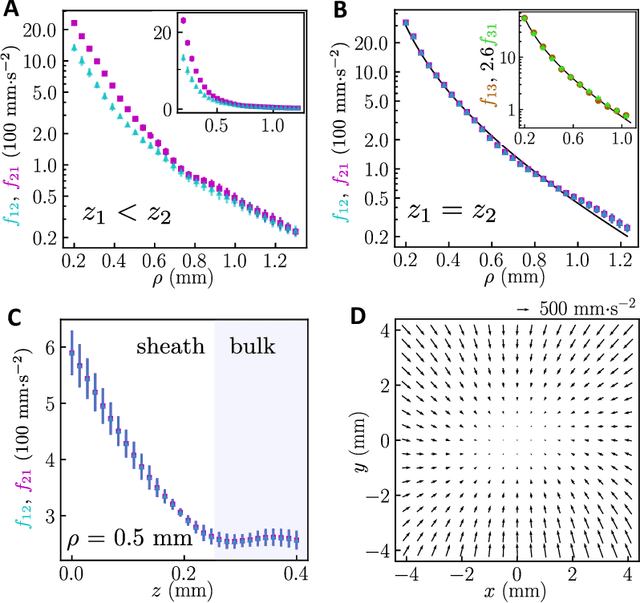
Scientific laws describing natural systems may be more complex than our intuition can handle, and thus how we discover laws must change. Machine learning (ML) models can analyze large quantities of data, but their structure should match the underlying physical constraints to provide useful insight. Here we demonstrate a ML approach that incorporates such physical intuition to infer force laws in dusty plasma experiments. Trained on 3D particle trajectories, the model accounts for inherent symmetries and non-identical particles, accurately learns the effective non-reciprocal forces between particles, and extracts each particle's mass and charge. The model's accuracy (R^2 > 0.99) points to new physics in dusty plasma beyond the resolution of current theories and demonstrates how ML-powered approaches can guide new routes of scientific discovery in many-body systems.
Deep Variational Multivariate Information Bottleneck -- A Framework for Variational Losses
Oct 05, 2023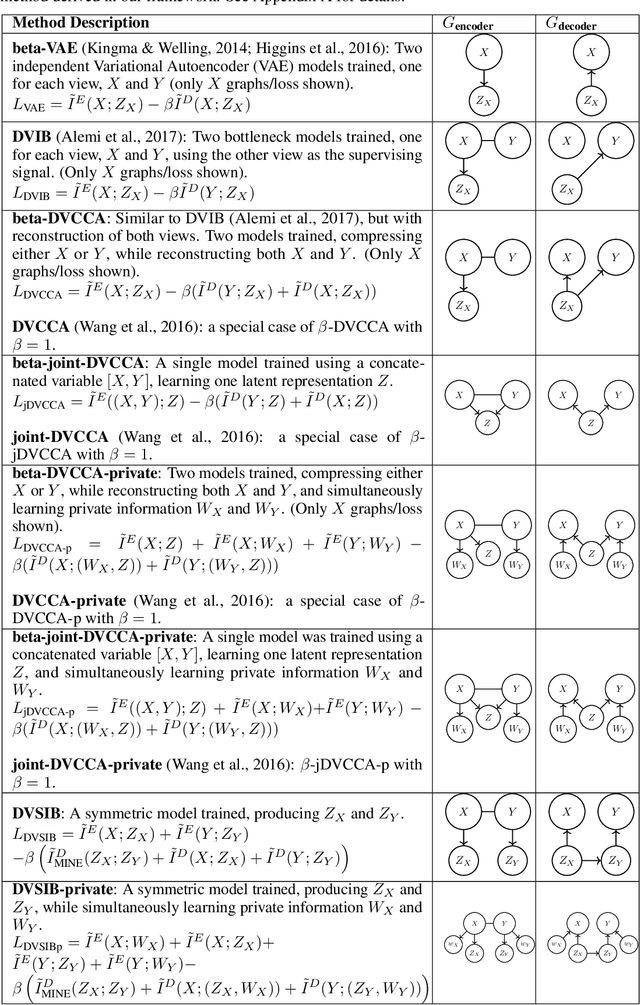

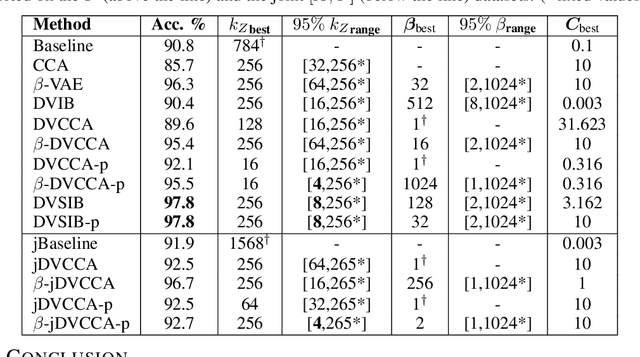
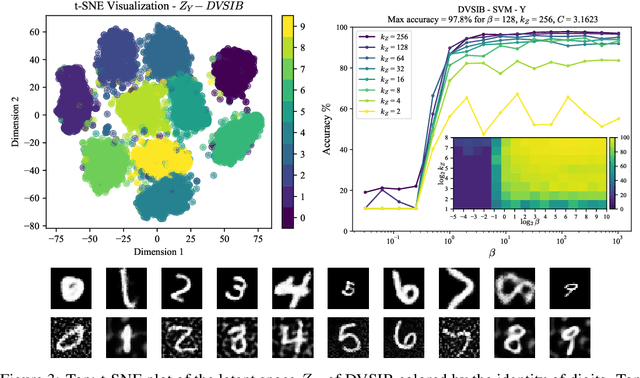
Variational dimensionality reduction methods are known for their high accuracy, generative abilities, and robustness. These methods have many theoretical justifications. Here we introduce a unifying principle rooted in information theory to rederive and generalize existing variational methods and design new ones. We base our framework on an interpretation of the multivariate information bottleneck, in which two Bayesian networks are traded off against one another. We interpret the first network as an encoder graph, which specifies what information to keep when compressing the data. We interpret the second network as a decoder graph, which specifies a generative model for the data. Using this framework, we rederive existing dimensionality reduction methods such as the deep variational information bottleneck (DVIB), beta variational auto-encoders (beta-VAE), and deep variational canonical correlation analysis (DVCCA). The framework naturally introduces a trade-off parameter between compression and reconstruction in the DVCCA family of algorithms, resulting in the new beta-DVCCA family. In addition, we derive a new variational dimensionality reduction method, deep variational symmetric informational bottleneck (DVSIB), which simultaneously compresses two variables to preserve information between their compressed representations. We implement all of these algorithms and evaluate their ability to produce shared low dimensional latent spaces on a modified noisy MNIST dataset. We show that algorithms that are better matched to the structure of the data (beta-DVCCA and DVSIB) produce better latent spaces as measured by classification accuracy and the dimensionality of the latent variables. We believe that this framework can be used to unify other multi-view representation learning algorithms. Additionally, it provides a straightforward framework for deriving problem-specific loss functions.
Simultaneous Dimensionality Reduction: A Data Efficient Approach for Multimodal Representations Learning
Oct 05, 2023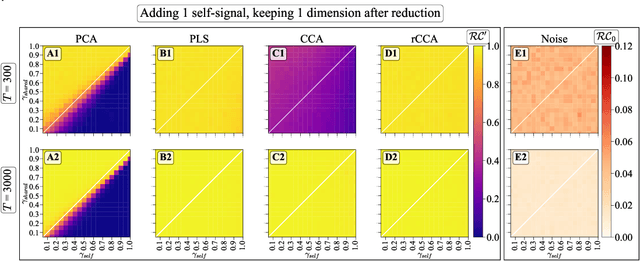
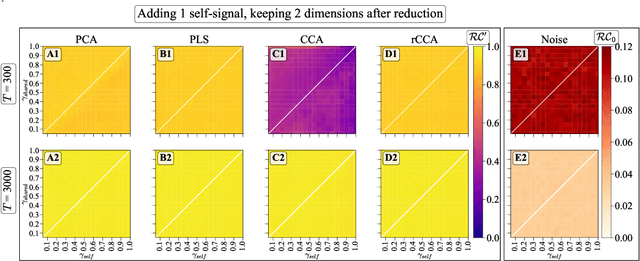
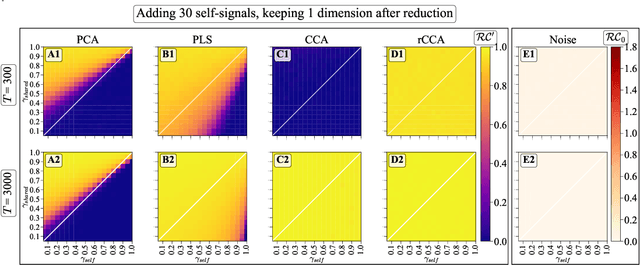
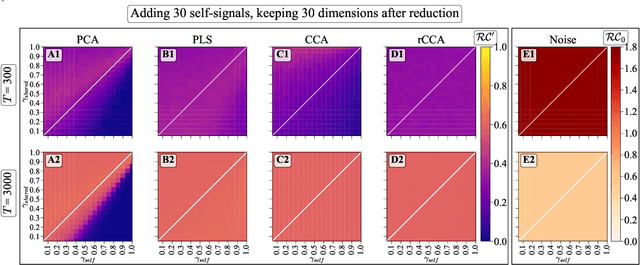
We explore two primary classes of approaches to dimensionality reduction (DR): Independent Dimensionality Reduction (IDR) and Simultaneous Dimensionality Reduction (SDR). In IDR methods, of which Principal Components Analysis is a paradigmatic example, each modality is compressed independently, striving to retain as much variation within each modality as possible. In contrast, in SDR, one simultaneously compresses the modalities to maximize the covariation between the reduced descriptions while paying less attention to how much individual variation is preserved. Paradigmatic examples include Partial Least Squares and Canonical Correlations Analysis. Even though these DR methods are a staple of statistics, their relative accuracy and data set size requirements are poorly understood. We introduce a generative linear model to synthesize multimodal data with known variance and covariance structures to examine these questions. We assess the accuracy of the reconstruction of the covariance structures as a function of the number of samples, signal-to-noise ratio, and the number of varying and covarying signals in the data. Using numerical experiments, we demonstrate that linear SDR methods consistently outperform linear IDR methods and yield higher-quality, more succinct reduced-dimensional representations with smaller datasets. Remarkably, regularized CCA can identify low-dimensional weak covarying structures even when the number of samples is much smaller than the dimensionality of the data, which is a regime challenging for all dimensionality reduction methods. Our work corroborates and explains previous observations in the literature that SDR can be more effective in detecting covariation patterns in data. These findings suggest that SDR should be preferred to IDR in real-world data analysis when detecting covariation is more important than preserving variation.