 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Debias: Self-correcting for Debiasing Large Language Models
Apr 09, 2026Although Large Language Models (LLMs) demonstrate remarkable reasoning capabilities, inherent social biases often cascade throughout the Chain-of-Thought (CoT) process, leading to continuous "Bias Propagation". Existing debiasing methods primarily focus on static constraints or external interventions, failing to identify and interrupt this propagation once triggered. To address this limitation, we introduce Self-Debias, a progressive framework designed to instill intrinsic self-correction capabilities. Specifically, we reformulate the debiasing process as a strategic resource redistribution problem, treating the model's output probability mass as a limited resource to be reallocated from biased heuristics to unbiased reasoning paths. Unlike standard preference optimization which applies broad penalties, Self-Debias employs a fine-grained trajectory-level objective subject to dynamic debiasing constraints. This enables the model to selectively revise biased reasoning suffixes while preserving valid contextual prefixes. Furthermore, we integrate an online self-improvement mechanism utilizing consistency filtering to autonomously synthesize supervision signals. With merely 20k annotated samples, Self-Debias activates efficient self-correction, achieving superior debiasing performance while preserving general reasoning capabilities without continuous external oversight.
C2PO: Diagnosing and Disentangling Bias Shortcuts in LLMs
Dec 29, 2025Bias in Large Language Models (LLMs) poses significant risks to trustworthiness, manifesting primarily as stereotypical biases (e.g., gender or racial stereotypes) and structural biases (e.g., lexical overlap or position preferences). However, prior paradigms typically address these in isolation, often mitigating one at the expense of exacerbating the other. To address this, we conduct a systematic exploration of these reasoning failures and identify a primary inducement: the latent spurious feature correlations within the input that drive these erroneous reasoning shortcuts. Driven by these findings, we introduce Causal-Contrastive Preference Optimization (C2PO), a unified alignment framework designed to tackle these specific failures by simultaneously discovering and suppressing these correlations directly within the optimization process. Specifically, C2PO leverages causal counterfactual signals to isolate bias-inducing features from valid reasoning paths, and employs a fairness-sensitive preference update mechanism to dynamically evaluate logit-level contributions and suppress shortcut features. Extensive experiments across multiple benchmarks covering stereotypical bias (BBQ, Unqover), structural bias (MNLI, HANS, Chatbot, MT-Bench), out-of-domain fairness (StereoSet, WinoBias), and general utility (MMLU, GSM8K) demonstrate that C2PO effectively mitigates stereotypical and structural biases while preserving robust general reasoning capabilities.
FairGSE: Fairness-Aware Graph Neural Network without High False Positive Rates
Nov 15, 2025Graph neural networks (GNNs) have emerged as the mainstream paradigm for graph representation learning due to their effective message aggregation. However, this advantage also amplifies biases inherent in graph topology, raising fairness concerns. Existing fairness-aware GNNs provide satisfactory performance on fairness metrics such as Statistical Parity and Equal Opportunity while maintaining acceptable accuracy trade-offs. Unfortunately, we observe that this pursuit of fairness metrics neglects the GNN's ability to predict negative labels, which renders their predictions with extremely high False Positive Rates (FPR), resulting in negative effects in high-risk scenarios. To this end, we advocate that classification performance should be carefully calibrated while improving fairness, rather than simply constraining accuracy loss. Furthermore, we propose Fair GNN via Structural Entropy (\textbf{FairGSE}), a novel framework that maximizes two-dimensional structural entropy (2D-SE) to improve fairness without neglecting false positives. Experiments on several real-world datasets show FairGSE reduces FPR by 39\% vs. state-of-the-art fairness-aware GNNs, with comparable fairness improvement.
Improving Recommendation Fairness via Graph Structure and Representation Augmentation
Aug 27, 2025Graph Convolutional Networks (GCNs) have become increasingly popular in recommendation systems. However, recent studies have shown that GCN-based models will cause sensitive information to disseminate widely in the graph structure, amplifying data bias and raising fairness concerns. While various fairness methods have been proposed, most of them neglect the impact of biased data on representation learning, which results in limited fairness improvement. Moreover, some studies have focused on constructing fair and balanced data distributions through data augmentation, but these methods significantly reduce utility due to disruption of user preferences. In this paper, we aim to design a fair recommendation method from the perspective of data augmentation to improve fairness while preserving recommendation utility. To achieve fairness-aware data augmentation with minimal disruption to user preferences, we propose two prior hypotheses. The first hypothesis identifies sensitive interactions by comparing outcomes of performance-oriented and fairness-aware recommendations, while the second one focuses on detecting sensitive features by analyzing feature similarities between biased and debiased representations. Then, we propose a dual data augmentation framework for fair recommendation, which includes two data augmentation strategies to generate fair augmented graphs and feature representations. Furthermore, we introduce a debiasing learning method that minimizes the dependence between the learned representations and sensitive information to eliminate bias. Extensive experiments on two real-world datasets demonstrate the superiority of our proposed framework.
Learning from Mistakes: Self-correct Adversarial Training for Chinese Unnatural Text Correction
Dec 23, 2024



Unnatural text correction aims to automatically detect and correct spelling errors or adversarial perturbation errors in sentences. Existing methods typically rely on fine-tuning or adversarial training to correct errors, which have achieved significant success. However, these methods exhibit poor generalization performance due to the difference in data distribution between training data and real-world scenarios, known as the exposure bias problem. In this paper, we propose a self-correct adversarial training framework for \textbf{L}earn\textbf{I}ng from \textbf{MI}s\textbf{T}akes (\textbf{LIMIT}), which is a task- and model-independent framework to correct unnatural errors or mistakes. Specifically, we fully utilize errors generated by the model that are actively exposed during the inference phase, i.e., predictions that are inconsistent with the target. This training method not only simulates potential errors in real application scenarios, but also mitigates the exposure bias of the traditional training process. Meanwhile, we design a novel decoding intervention strategy to maintain semantic consistency. Extensive experimental results on Chinese unnatural text error correction datasets show that our proposed method can correct multiple forms of errors and outperforms the state-of-the-art text correction methods. In addition, extensive results on Chinese and English datasets validate that LIMIT can serve as a plug-and-play defense module and can extend to new models and datasets without further training.
FairDD: Enhancing Fairness with domain-incremental learning in dermatological disease diagnosis
Dec 21, 2024



With the rapid advancement of deep learning technologies, artificial intelligence has become increasingly prevalent in the research and application of dermatological disease diagnosis. However, this data-driven approach often faces issues related to decision bias. Existing fairness enhancement techniques typically come at a substantial cost to accuracy. This study aims to achieve a better trade-off between accuracy and fairness in dermatological diagnostic models. To this end, we propose a novel fair dermatological diagnosis network, named FairDD, which leverages domain incremental learning to balance the learning of different groups by being sensitive to changes in data distribution. Additionally, we incorporate the mixup data augmentation technique and supervised contrastive learning to enhance the network's robustness and generalization. Experimental validation on two dermatological datasets demonstrates that our proposed method excels in both fairness criteria and the trade-off between fairness and performance.
Modeling Inter-Intra Heterogeneity for Graph Federated Learning
Dec 16, 2024



Heterogeneity is a fundamental and challenging issue in federated learning, especially for the graph data due to the complex relationships among the graph nodes. To deal with the heterogeneity, lots of existing methods perform the weighted federation based on their calculated similarities between pairwise clients (i.e., subgraphs). However, their inter-subgraph similarities estimated with the outputs of local models are less reliable, because the final outputs of local models may not comprehensively represent the real distribution of subgraph data. In addition, they ignore the critical intra-heterogeneity which usually exists within each subgraph itself. To address these issues, we propose a novel Federated learning method by integrally modeling the Inter-Intra Heterogeneity (FedIIH). For the inter-subgraph relationship, we propose a novel hierarchical variational model to infer the whole distribution of subgraph data in a multi-level form, so that we can accurately characterize the inter-subgraph similarities with the global perspective. For the intra-heterogeneity, we disentangle the subgraph into multiple latent factors and partition the model parameters into multiple parts, where each part corresponds to a single latent factor. Our FedIIH not only properly computes the distribution similarities between subgraphs, but also learns disentangled representations that are robust to irrelevant factors within subgraphs, so that it successfully considers the inter- and intra- heterogeneity simultaneously. Extensive experiments on six homophilic and five heterophilic graph datasets in both non-overlapping and overlapping settings demonstrate the effectiveness of our method when compared with nine state-of-the-art methods. Specifically, FedIIH averagely outperforms the second-best method by a large margin of 5.79% on all heterophilic datasets.
Towards Fair Graph Neural Networks via Graph Counterfactual without Sensitive Attributes
Dec 13, 2024


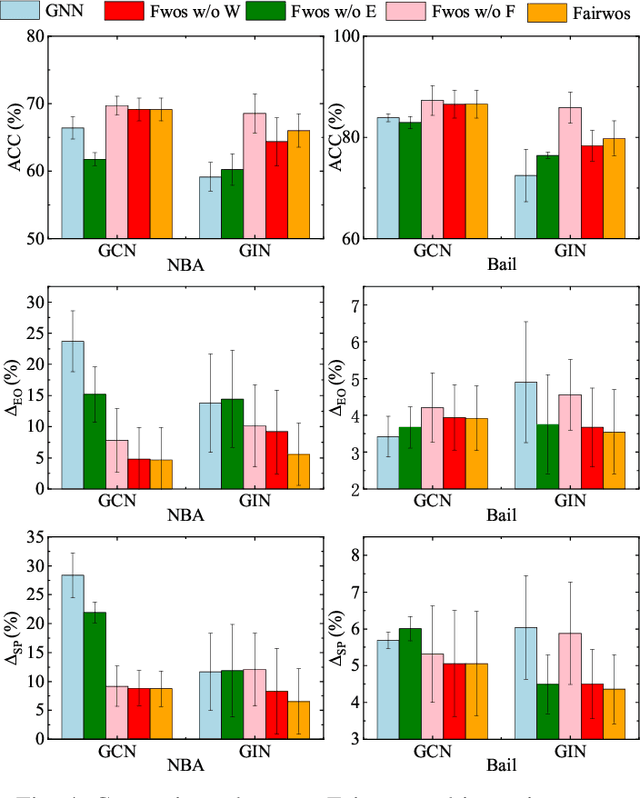
Graph-structured data is ubiquitous in today's connected world, driving extensive research in graph analysis. Graph Neural Networks (GNNs) have shown great success in this field, leading to growing interest in developing fair GNNs for critical applications. However, most existing fair GNNs focus on statistical fairness notions, which may be insufficient when dealing with statistical anomalies. Hence, motivated by causal theory, there has been growing attention to mitigating root causes of unfairness utilizing graph counterfactuals. Unfortunately, existing methods for generating graph counterfactuals invariably require the sensitive attribute. Nevertheless, in many real-world applications, it is usually infeasible to obtain sensitive attributes due to privacy or legal issues, which challenge existing methods. In this paper, we propose a framework named Fairwos (improving Fairness without sensitive attributes). In particular, we first propose a mechanism to generate pseudo-sensitive attributes to remedy the problem of missing sensitive attributes, and then design a strategy for finding graph counterfactuals from the real dataset. To train fair GNNs, we propose a method to ensure that the embeddings from the original data are consistent with those from the graph counterfactuals, and dynamically adjust the weight of each pseudo-sensitive attribute to balance its contribution to fairness and utility. Furthermore, we theoretically demonstrate that minimizing the relation between these pseudo-sensitive attributes and the prediction can enable the fairness of GNNs. Experimental results on six real-world datasets show that our approach outperforms state-of-the-art methods in balancing utility and fairness.
Dual-Teacher De-biasing Distillation Framework for Multi-domain Fake News Detection
Dec 02, 2023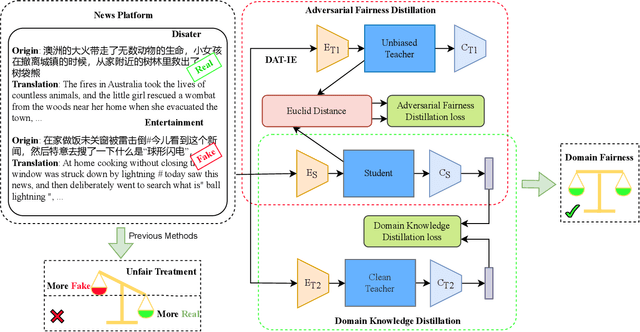
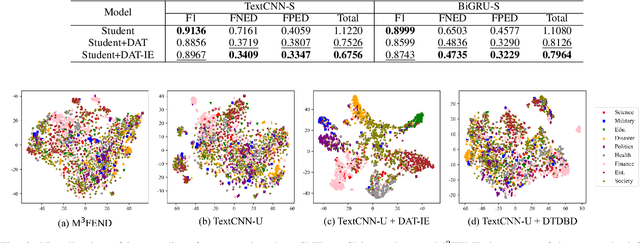

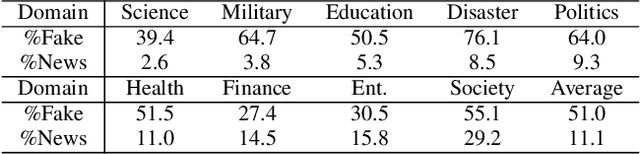
Multi-domain fake news detection aims to identify whether various news from different domains is real or fake and has become urgent and important. However, existing methods are dedicated to improving the overall performance of fake news detection, ignoring the fact that unbalanced data leads to disparate treatment for different domains, i.e., the domain bias problem. To solve this problem, we propose the Dual-Teacher De-biasing Distillation framework (DTDBD) to mitigate bias across different domains. Following the knowledge distillation methods, DTDBD adopts a teacher-student structure, where pre-trained large teachers instruct a student model. In particular, the DTDBD consists of an unbiased teacher and a clean teacher that jointly guide the student model in mitigating domain bias and maintaining performance. For the unbiased teacher, we introduce an adversarial de-biasing distillation loss to instruct the student model in learning unbiased domain knowledge. For the clean teacher, we design domain knowledge distillation loss, which effectively incentivizes the student model to focus on representing domain features while maintaining performance. Moreover, we present a momentum-based dynamic adjustment algorithm to trade off the effects of two teachers. Extensive experiments on Chinese and English datasets show that the proposed method substantially outperforms the state-of-the-art baseline methods in terms of bias metrics while guaranteeing competitive performance.
MDL-based Compressing Sequential Rules
Dec 20, 2022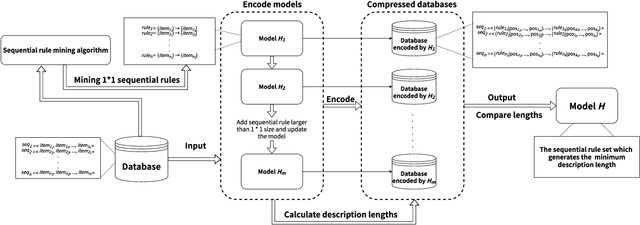
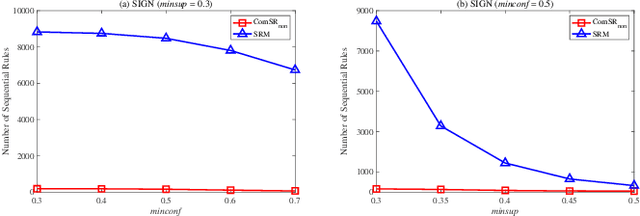

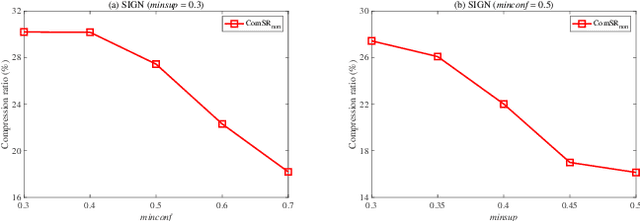
Nowadays, with the rapid development of the Internet, the era of big data has come. The Internet generates huge amounts of data every day. However, extracting meaningful information from massive data is like looking for a needle in a haystack. Data mining techniques can provide various feasible methods to solve this problem. At present, many sequential rule mining (SRM) algorithms are presented to find sequential rules in databases with sequential characteristics. These rules help people extract a lot of meaningful information from massive amounts of data. How can we achieve compression of mined results and reduce data size to save storage space and transmission time? Until now, there has been little research on the compression of SRM. In this paper, combined with the Minimum Description Length (MDL) principle and under the two metrics (support and confidence), we introduce the problem of compression of SRM and also propose a solution named ComSR for MDL-based compressing of sequential rules based on the designed sequential rule coding scheme. To our knowledge, we are the first to use sequential rules to encode an entire database. A heuristic method is proposed to find a set of compact and meaningful sequential rules as much as possible. ComSR has two trade-off algorithms, ComSR_non and ComSR_ful, based on whether the database can be completely compressed. Experiments done on a real dataset with different thresholds show that a set of compact and meaningful sequential rules can be found. This shows that the proposed method works.