 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Eye to Eye: Enabling Cognitive Alignment Through Shared First-Person Perspective in Human-AI Collaboration
Mar 13, 2026Despite advances in multimodal AI, current vision-based assistants often remain inefficient in collaborative tasks. We identify two key gulfs: a communication gulf, where users must translate rich parallel intentions into verbal commands due to the channel mismatch , and an understanding gulf, where AI struggles to interpret subtle embodied cues. To address these, we propose Eye2Eye, a framework that leverages first-person perspective as a channel for human-AI cognitive alignment. It integrates three components: (1) joint attention coordination for fluid focus alignment, (2) revisable memory to maintain evolving common ground, and (3) reflective feedback allowing users to clarify and refine AI's understanding. We implement this framework in an AR prototype and evaluate it through a user study and a post-hoc pipeline evaluation. Results show that Eye2Eye significantly reduces task completion time and interaction load while increasing trust, demonstrating its components work in concert to improve collaboration.
Evolving Prompt Adaptation for Vision-Language Models
Mar 10, 2026The adaptation of large-scale vision-language models (VLMs) to downstream tasks with limited labeled data remains a significant challenge. While parameter-efficient prompt learning methods offer a promising path, they often suffer from catastrophic forgetting of pre-trained knowledge. Toward addressing this limitation, our work is grounded in the insight that governing the evolutionary path of prompts is essential for forgetting-free adaptation. To this end, we propose EvoPrompt, a novel framework designed to explicitly steer the prompt trajectory for stable, knowledge-preserving fine-tuning. Specifically, our approach employs a Modality-Shared Prompt Projector (MPP) to generate hierarchical prompts from a unified embedding space. Critically, an evolutionary training strategy decouples low-rank updates into directional and magnitude components, preserving early-learned semantic directions while only adapting their magnitude, thus enabling prompts to evolve without discarding foundational knowledge. This process is further stabilized by Feature Geometric Regularization (FGR), which enforces feature decorrelation to prevent representation collapse. Extensive experiments demonstrate that EvoPrompt achieves state-of-the-art performance in few-shot learning while robustly preserving the original zero-shot capabilities of pre-trained VLMs.
Accelerating Masked Image Generation by Learning Latent Controlled Dynamics
Feb 27, 2026Masked Image Generation Models (MIGMs) have achieved great success, yet their efficiency is hampered by the multiple steps of bi-directional attention. In fact, there exists notable redundancy in their computation: when sampling discrete tokens, the rich semantics contained in the continuous features are lost. Some existing works attempt to cache the features to approximate future features. However, they exhibit considerable approximation error under aggressive acceleration rates. We attribute this to their limited expressivity and the failure to account for sampling information. To fill this gap, we propose to learn a lightweight model that incorporates both previous features and sampled tokens, and regresses the average velocity field of feature evolution. The model has moderate complexity that suffices to capture the subtle dynamics while keeping lightweight compared to the original base model. We apply our method, MIGM-Shortcut, to two representative MIGM architectures and tasks. In particular, on the state-of-the-art Lumina-DiMOO, it achieves over 4x acceleration of text-to-image generation while maintaining quality, significantly pushing the Pareto frontier of masked image generation. The code and model weights are available at https://github.com/Kaiwen-Zhu/MIGM-Shortcut.
Democratizing planetary-scale analysis: An ultra-lightweight Earth embedding database for accurate and flexible global land monitoring
Jan 16, 2026The rapid evolution of satellite-borne Earth Observation (EO) systems has revolutionized terrestrial monitoring, yielding petabyte-scale archives. However, the immense computational and storage requirements for global-scale analysis often preclude widespread use, hindering planetary-scale studies. To address these barriers, we present Embedded Seamless Data (ESD), an ultra-lightweight, 30-m global Earth embedding database spanning the 25-year period from 2000 to 2024. By transforming high-dimensional, multi-sensor observations from the Landsat series (5, 7, 8, and 9) and MODIS Terra into information-dense, quantized latent vectors, ESD distills essential geophysical and semantic features into a unified latent space. Utilizing the ESDNet architecture and Finite Scalar Quantization (FSQ), the dataset achieves a transformative ~340-fold reduction in data volume compared to raw archives. This compression allows the entire global land surface for a single year to be encapsulated within approximately 2.4 TB, enabling decadal-scale global analysis on standard local workstations. Rigorous validation demonstrates high reconstructive fidelity (MAE: 0.0130; RMSE: 0.0179; CC: 0.8543). By condensing the annual phenological cycle into 12 temporal steps, the embeddings provide inherent denoising and a semantically organized space that outperforms raw reflectance in land-cover classification, achieving 79.74% accuracy (vs. 76.92% for raw fusion). With robust few-shot learning capabilities and longitudinal consistency, ESD provides a versatile foundation for democratizing planetary-scale research and advancing next-generation geospatial artificial intelligence.
UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture
Dec 25, 2025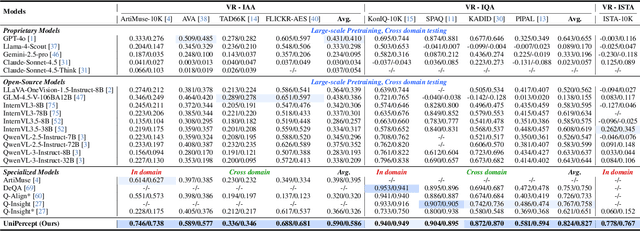

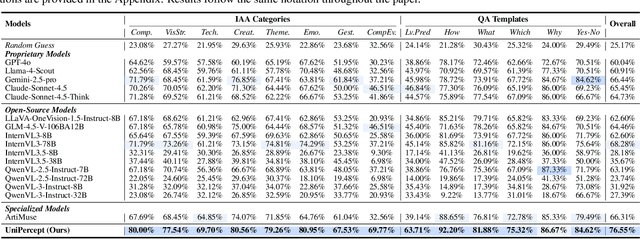
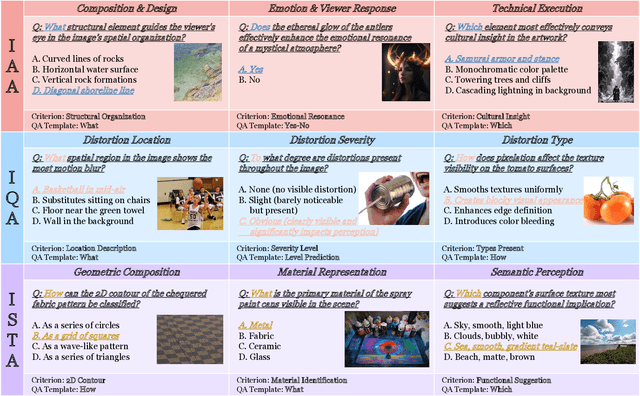
Multimodal large language models (MLLMs) have achieved remarkable progress in visual understanding tasks such as visual grounding, segmentation, and captioning. However, their ability to perceive perceptual-level image features remains limited. In this work, we present UniPercept-Bench, a unified framework for perceptual-level image understanding across three key domains: Aesthetics, Quality, Structure and Texture. We establish a hierarchical definition system and construct large-scale datasets to evaluate perceptual-level image understanding. Based on this foundation, we develop a strong baseline UniPercept trained via Domain-Adaptive Pre-Training and Task-Aligned RL, enabling robust generalization across both Visual Rating (VR) and Visual Question Answering (VQA) tasks. UniPercept outperforms existing MLLMs on perceptual-level image understanding and can serve as a plug-and-play reward model for text-to-image generation. This work defines Perceptual-Level Image Understanding in the era of MLLMs and, through the introduction of a comprehensive benchmark together with a strong baseline, provides a solid foundation for advancing perceptual-level multimodal image understanding.
LLM-Guided Reinforcement Learning with Representative Agents for Traffic Modeling
Nov 09, 2025Large language models (LLMs) are increasingly used as behavioral proxies for self-interested travelers in agent-based traffic models. Although more flexible and generalizable than conventional models, the practical use of these approaches remains limited by scalability due to the cost of calling one LLM for every traveler. Moreover, it has been found that LLM agents often make opaque choices and produce unstable day-to-day dynamics. To address these challenges, we propose to model each homogeneous traveler group facing the same decision context with a single representative LLM agent who behaves like the population's average, maintaining and updating a mixed strategy over routes that coincides with the group's aggregate flow proportions. Each day, the LLM reviews the travel experience and flags routes with positive reinforcement that they hope to use more often, and an interpretable update rule then converts this judgment into strategy adjustments using a tunable (progressively decaying) step size. The representative-agent design improves scalability, while the separation of reasoning from updating clarifies the decision logic while stabilizing learning. In classic traffic assignment settings, we find that the proposed approach converges rapidly to the user equilibrium. In richer settings with income heterogeneity, multi-criteria costs, and multi-modal choices, the generated dynamics remain stable and interpretable, reproducing plausible behavioral patterns well-documented in psychology and economics, for example, the decoy effect in toll versus non-toll road selection, and higher willingness-to-pay for convenience among higher-income travelers when choosing between driving, transit, and park-and-ride options.
Data Duplication: A Novel Multi-Purpose Attack Paradigm in Machine Unlearning
Jan 28, 2025



Duplication is a prevalent issue within datasets. Existing research has demonstrated that the presence of duplicated data in training datasets can significantly influence both model performance and data privacy. However, the impact of data duplication on the unlearning process remains largely unexplored. This paper addresses this gap by pioneering a comprehensive investigation into the role of data duplication, not only in standard machine unlearning but also in federated and reinforcement unlearning paradigms. Specifically, we propose an adversary who duplicates a subset of the target model's training set and incorporates it into the training set. After training, the adversary requests the model owner to unlearn this duplicated subset, and analyzes the impact on the unlearned model. For example, the adversary can challenge the model owner by revealing that, despite efforts to unlearn it, the influence of the duplicated subset remains in the model. Moreover, to circumvent detection by de-duplication techniques, we propose three novel near-duplication methods for the adversary, each tailored to a specific unlearning paradigm. We then examine their impacts on the unlearning process when de-duplication techniques are applied. Our findings reveal several crucial insights: 1) the gold standard unlearning method, retraining from scratch, fails to effectively conduct unlearning under certain conditions; 2) unlearning duplicated data can lead to significant model degradation in specific scenarios; and 3) meticulously crafted duplicates can evade detection by de-duplication methods.
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
Jan 24, 2025



This paper introduces the open-source dataset WanJuanSiLu, designed to provide high-quality training corpora for low-resource languages, thereby advancing the research and development of multilingual models. To achieve this, we have developed a systematic data processing framework tailored for low-resource languages. This framework encompasses key stages such as data extraction, corpus cleaning, content deduplication, security filtering, quality evaluation, and theme classification. Through the implementation of this framework, we have significantly improved both the quality and security of the dataset, while maintaining its linguistic diversity. As of now, data for all five languages have been fully open-sourced. The dataset can be accessed at https://opendatalab.com/applyMultilingualCorpus, and GitHub repository is available at https://github.com/opendatalab/WanJuan3.0
MaeFuse: Transferring Omni Features with Pretrained Masked Autoencoders for Infrared and Visible Image Fusion via Guided Training
Apr 17, 2024In this research, we introduce MaeFuse, a novel autoencoder model designed for infrared and visible image fusion (IVIF). The existing approaches for image fusion often rely on training combined with downstream tasks to obtain high-level visual information, which is effective in emphasizing target objects and delivering impressive results in visual quality and task-specific applications. MaeFuse, however, deviates from the norm. Instead of being driven by downstream tasks, our model utilizes a pretrained encoder from Masked Autoencoders (MAE), which facilities the omni features extraction for low-level reconstruction and high-level vision tasks, to obtain perception friendly features with a low cost. In order to eliminate the domain gap of different modal features and the block effect caused by the MAE encoder, we further develop a guided training strategy. This strategy is meticulously crafted to ensure that the fusion layer seamlessly adjusts to the feature space of the encoder, gradually enhancing the fusion effect. It facilitates the comprehensive integration of feature vectors from both infrared and visible modalities, preserving the rich details inherent in each. MaeFuse not only introduces a novel perspective in the realm of fusion techniques but also stands out with impressive performance across various public datasets.
Dual-Teacher De-biasing Distillation Framework for Multi-domain Fake News Detection
Dec 02, 2023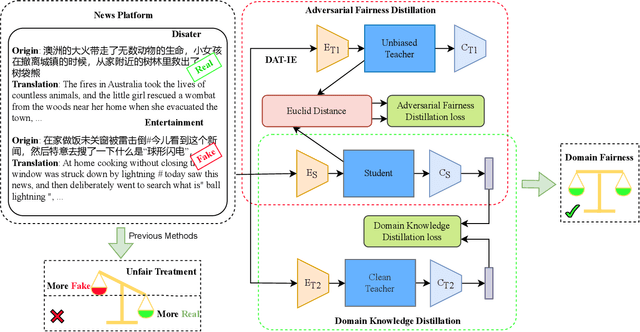
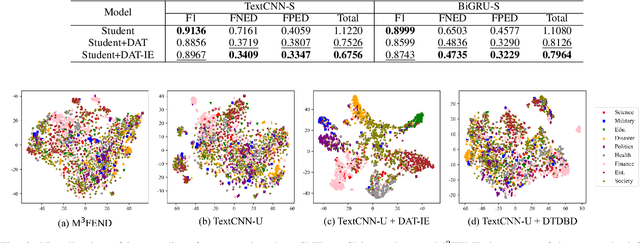

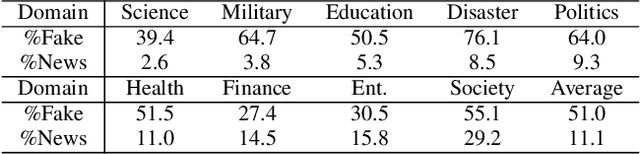
Multi-domain fake news detection aims to identify whether various news from different domains is real or fake and has become urgent and important. However, existing methods are dedicated to improving the overall performance of fake news detection, ignoring the fact that unbalanced data leads to disparate treatment for different domains, i.e., the domain bias problem. To solve this problem, we propose the Dual-Teacher De-biasing Distillation framework (DTDBD) to mitigate bias across different domains. Following the knowledge distillation methods, DTDBD adopts a teacher-student structure, where pre-trained large teachers instruct a student model. In particular, the DTDBD consists of an unbiased teacher and a clean teacher that jointly guide the student model in mitigating domain bias and maintaining performance. For the unbiased teacher, we introduce an adversarial de-biasing distillation loss to instruct the student model in learning unbiased domain knowledge. For the clean teacher, we design domain knowledge distillation loss, which effectively incentivizes the student model to focus on representing domain features while maintaining performance. Moreover, we present a momentum-based dynamic adjustment algorithm to trade off the effects of two teachers. Extensive experiments on Chinese and English datasets show that the proposed method substantially outperforms the state-of-the-art baseline methods in terms of bias metrics while guaranteeing competitive performance.