 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion from Decomposition: A Self-Supervised Approach for Image Fusion and Beyond
Oct 16, 2024



Image fusion is famous as an alternative solution to generate one high-quality image from multiple images in addition to image restoration from a single degraded image. The essence of image fusion is to integrate complementary information from source images. Existing fusion methods struggle with generalization across various tasks and often require labor-intensive designs, in which it is difficult to identify and extract useful information from source images due to the diverse requirements of each fusion task. Additionally, these methods develop highly specialized features for different downstream applications, hindering the adaptation to new and diverse downstream tasks. To address these limitations, we introduce DeFusion++, a novel framework that leverages self-supervised learning (SSL) to enhance the versatility of feature representation for different image fusion tasks. DeFusion++ captures the image fusion task-friendly representations from large-scale data in a self-supervised way, overcoming the constraints of limited fusion datasets. Specifically, we introduce two innovative pretext tasks: common and unique decomposition (CUD) and masked feature modeling (MFM). CUD decomposes source images into abstract common and unique components, while MFM refines these components into robust fused features. Jointly training of these tasks enables DeFusion++ to produce adaptable representations that can effectively extract useful information from various source images, regardless of the fusion task. The resulting fused representations are also highly adaptable for a wide range of downstream tasks, including image segmentation and object detection. DeFusion++ stands out by producing versatile fused representations that can enhance both the quality of image fusion and the effectiveness of downstream high-level vision tasks, simplifying the process with the elegant fusion framework.
MaeFuse: Transferring Omni Features with Pretrained Masked Autoencoders for Infrared and Visible Image Fusion via Guided Training
Apr 17, 2024In this research, we introduce MaeFuse, a novel autoencoder model designed for infrared and visible image fusion (IVIF). The existing approaches for image fusion often rely on training combined with downstream tasks to obtain high-level visual information, which is effective in emphasizing target objects and delivering impressive results in visual quality and task-specific applications. MaeFuse, however, deviates from the norm. Instead of being driven by downstream tasks, our model utilizes a pretrained encoder from Masked Autoencoders (MAE), which facilities the omni features extraction for low-level reconstruction and high-level vision tasks, to obtain perception friendly features with a low cost. In order to eliminate the domain gap of different modal features and the block effect caused by the MAE encoder, we further develop a guided training strategy. This strategy is meticulously crafted to ensure that the fusion layer seamlessly adjusts to the feature space of the encoder, gradually enhancing the fusion effect. It facilitates the comprehensive integration of feature vectors from both infrared and visible modalities, preserving the rich details inherent in each. MaeFuse not only introduces a novel perspective in the realm of fusion techniques but also stands out with impressive performance across various public datasets.
Image Deblurring by Exploring In-depth Properties of Transformer
Mar 24, 2023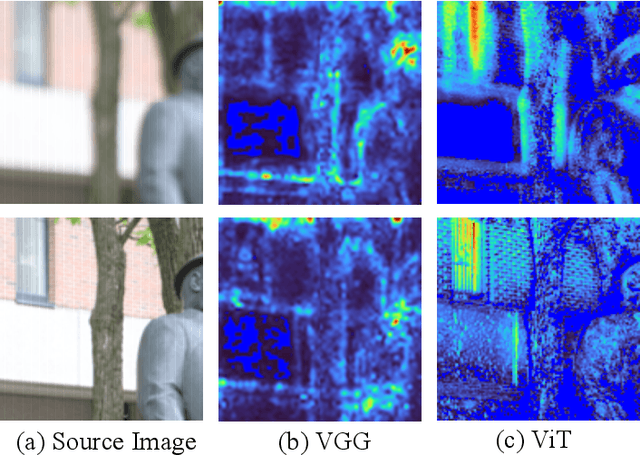

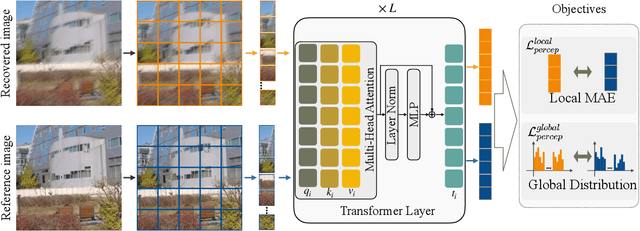

Image deblurring continues to achieve impressive performance with the development of generative models. Nonetheless, there still remains a displeasing problem if one wants to improve perceptual quality and quantitative scores of recovered image at the same time. In this study, drawing inspiration from the research of transformer properties, we introduce the pretrained transformers to address this problem. In particular, we leverage deep features extracted from a pretrained vision transformer (ViT) to encourage recovered images to be sharp without sacrificing the performance measured by the quantitative metrics. The pretrained transformer can capture the global topological relations (i.e., self-similarity) of image, and we observe that the captured topological relations about the sharp image will change when blur occurs. By comparing the transformer features between recovered image and target one, the pretrained transformer provides high-resolution blur-sensitive semantic information, which is critical in measuring the sharpness of the deblurred image. On the basis of the advantages, we present two types of novel perceptual losses to guide image deblurring. One regards the features as vectors and computes the discrepancy between representations extracted from recovered image and target one in Euclidean space. The other type considers the features extracted from an image as a distribution and compares the distribution discrepancy between recovered image and target one. We demonstrate the effectiveness of transformer properties in improving the perceptual quality while not sacrificing the quantitative scores (PSNR) over the most competitive models, such as Uformer, Restormer, and NAFNet, on defocus deblurring and motion deblurring tasks.
BaMBNet: A Blur-aware Multi-branch Network for Defocus Deblurring
May 31, 2021
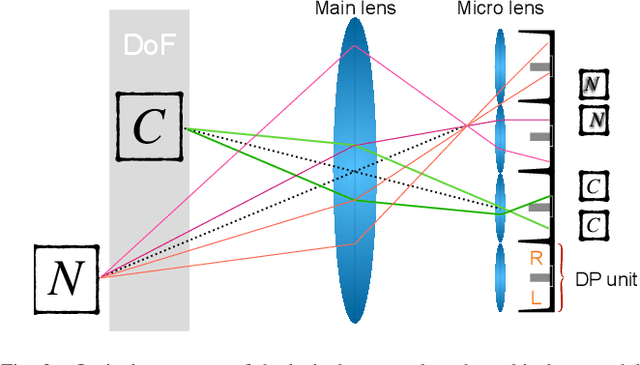
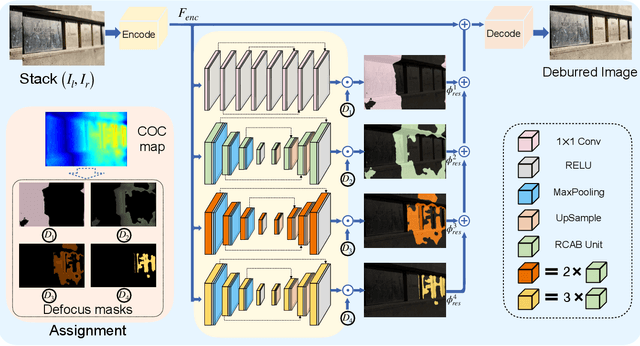

The defocus deblurring raised from the finite aperture size and exposure time is an essential problem in the computational photography. It is very challenging because the blur kernel is spatially varying and difficult to estimate by traditional methods. Due to its great breakthrough in low-level tasks, convolutional neural networks (CNNs) have been introduced to the defocus deblurring problem and achieved significant progress. However, they apply the same kernel for different regions of the defocus blurred images, thus it is difficult to handle these nonuniform blurred images. To this end, this study designs a novel blur-aware multi-branch network (BaMBNet), in which different regions (with different blur amounts) should be treated differentially. In particular, we estimate the blur amounts of different regions by the internal geometric constraint of the DP data, which measures the defocus disparity between the left and right views. Based on the assumption that different image regions with different blur amounts have different deblurring difficulties, we leverage different networks with different capacities (\emph{i.e.} parameters) to process different image regions. Moreover, we introduce a meta-learning defocus mask generation algorithm to assign each pixel to a proper branch. In this way, we can expect to well maintain the information of the clear regions while recovering the missing details of the blurred regions. Both quantitative and qualitative experiments demonstrate that our BaMBNet outperforms the state-of-the-art methods. Source code will be available at https://github.com/junjun-jiang/BaMBNet.