 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Deblurring by Exploring In-depth Properties of Transformer
Paper and Code
Mar 24, 2023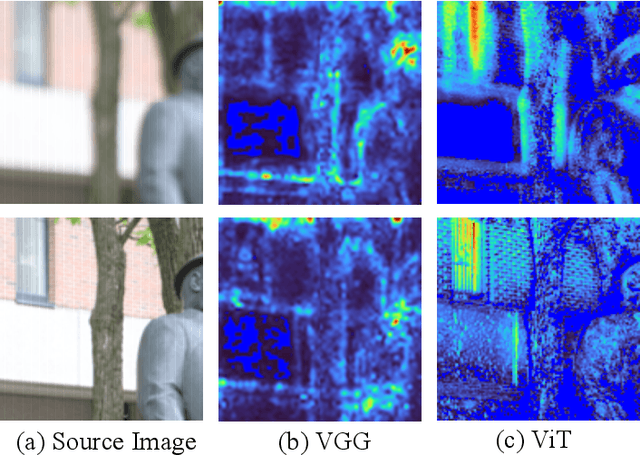

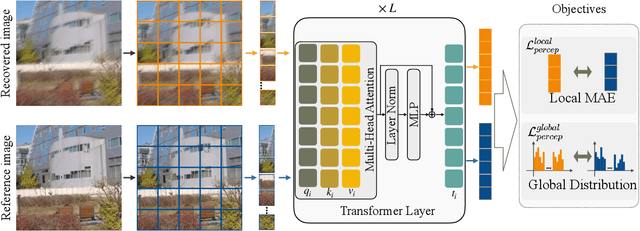

Image deblurring continues to achieve impressive performance with the development of generative models. Nonetheless, there still remains a displeasing problem if one wants to improve perceptual quality and quantitative scores of recovered image at the same time. In this study, drawing inspiration from the research of transformer properties, we introduce the pretrained transformers to address this problem. In particular, we leverage deep features extracted from a pretrained vision transformer (ViT) to encourage recovered images to be sharp without sacrificing the performance measured by the quantitative metrics. The pretrained transformer can capture the global topological relations (i.e., self-similarity) of image, and we observe that the captured topological relations about the sharp image will change when blur occurs. By comparing the transformer features between recovered image and target one, the pretrained transformer provides high-resolution blur-sensitive semantic information, which is critical in measuring the sharpness of the deblurred image. On the basis of the advantages, we present two types of novel perceptual losses to guide image deblurring. One regards the features as vectors and computes the discrepancy between representations extracted from recovered image and target one in Euclidean space. The other type considers the features extracted from an image as a distribution and compares the distribution discrepancy between recovered image and target one. We demonstrate the effectiveness of transformer properties in improving the perceptual quality while not sacrificing the quantitative scores (PSNR) over the most competitive models, such as Uformer, Restormer, and NAFNet, on defocus deblurring and motion deblurring tasks.