 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Note on Stability for Orthogonalized Matrix Momentum with Client Sampling
Jun 01, 2026We study finite-sample generalization for a client-sampled distributed optimization scheme with matrix-valued parameters and orthogonalized momentum updates. The central quantity is the gap between the population and empirical objectives at the returned model when only a subset of clients participates in each round. Under independent heterogeneous client data, unequal local sample counts, and fixed aggregation weights, we derive a finite-round upper-tail guarantee from a coupled-neighbor stability recursion and a weighted concentration step. The bound keeps the client-selection counts through the amplification factor \(Y_i(\mathcal C)\); in the uniform full-participation full-batch regime, it yields \(\widetilde{\mathcal O}(n^{-1}+n^{-1/2})\) scaling whenever the horizon-dependent amplification terms are controlled. The matrix-orthogonalization rule is required to be Lipschitz along paired trajectories, a condition satisfied by regularized polar-type maps and normalized finite-step Newton--Schulz orthogonalizers. For the unregularized matrix sign, the same argument requires coupled spectral separation, whereas Gaussian smoothing gives a finite-round smoothed variant. A one-dimensional counterexample shows why a gap, smoothing, or regularity condition is necessary.
GRZO: Group-Relative Zeroth-Order Optimization for Large Language Model Fine-Tuning
Jun 01, 2026Zeroth-order (ZO) optimization is a memory-efficient alternative to backpropagation for fine-tuning large language models, but its deployment is limited by the high variance of gradient estimation. We propose GRZO, a Group-Relative Zeroth-Order optimizer that draws one pseudo-independent perturbation per mini-batch example and aggregates the per-example losses through group-relative normalization, raising the effective gradient-direction count from one to the batch size at no additional forward cost while preserving inference-level memory. We prove that GRZO is directionally unbiased with variance shrinking proportionally to the batch size, yielding a tighter nonconvex convergence bound than MeZO. Across RoBERTa-large, Llama3-8B, and OPT-13B over multiple tasks, GRZO improves average accuracy on Llama3-8B by $+3.0$ over MeZO at $23\%$ lower peak GPU memory; as a drop-in replacement for the MeZO core, it lifts sparse, low-rank, and quantized ZO variants by $+6.0$ on average.
MolRecBench-Wild: A Real-World Benchmark for Optical Chemical Structure Recognition
May 07, 2026Optical Chemical Structure Recognition (OCSR) aims to translate molecular diagrams in scientific literature into machine-readable formats, but current systems remain unreliable on real-world images due to substantial visual and chemical complexity. We introduce MOSAIC, a dual-dimensional difficulty framework with 37 fine-grained labels that jointly characterize visual interference and chemical semantic challenges in molecular diagrams. Based on this framework, we construct MolRecBench-Wild, a benchmark of 5,029 structures from 820 recent chemistry papers, covering the full difficulty spectrum observed in real publications. To enable faithful semantic evaluation beyond SMILES and MolFile, we propose CARBON, a representation language capable of expressing valence variations, icon-based groups, and other non-standard chemical semantics. We further adopt a dual-track evaluation protocol supporting both CARBON and SMILES outputs for broad model compatibility. Comprehensive experiments over 18 OCSR-capable models reveal severe performance degradation on MolRecBench-Wild, exposing a large gap between previous patent benchmarks and real-world academic scenarios.
Muon$^2$: Boosting Muon via Adaptive Second-Moment Preconditioning
Apr 11, 2026Muon has emerged as a promising optimizer for large-scale foundation model pre-training by exploiting the matrix structure of neural network updates through iterative orthogonalization. However, its practical efficiency is limited by the need for multiple Newton--Schulz (NS) iterations per optimization step, which introduces non-trivial computation and communication overhead. We propose Muon$^2$, an extension of Muon that applies Adam-style adaptive second-moment preconditioning before orthogonalization. Our key insight is that the core challenge of polar approximation in Muon lies in the ill-conditioned momentum matrix, of which the spectrum is substantially improved by Muon$^2$, leading to faster convergence toward a practically sufficient orthogonalization. We further characterize the practical orthogonalization quality via directional alignment, under which Muon$^2$ demonstrates dramatic improvement over Muon at each polar step. Across GPT and LLaMA pre-training experiments from 60M to 1.3B parameters, Muon$^2$ consistently outperforms Muon and recent Muon variants while reducing NS iterations by 40\%. We further introduce Muon$^2$-F, a memory-efficient factorized variant that preserves most of the gains of Muon$^2$ with negligible memory overhead.
MuonEq: Balancing Before Orthogonalization with Lightweight Equilibration
Mar 30, 2026Orthogonalized-update optimizers such as Muon improve training of matrix-valued parameters, but existing extensions mostly act either after orthogonalization by rescaling updates or before it with heavier whitening-based preconditioners. We introduce {\method}, a lightweight family of pre-orthogonalization equilibration schemes for Muon in three forms: two-sided row/column normalization (RC), row normalization (R), and column normalization (C). These variants rebalance the momentum matrix before finite-step Newton--Schulz using row/column squared-norm statistics and only $\mathcal{O}(m+n)$ auxiliary state. We show that finite-step orthogonalization is governed by input spectral properties, especially stable rank and condition number, and that row/column normalization is a zeroth-order whitening surrogate that removes marginal scale mismatch. For the hidden matrix weights targeted by {\method}, the row-normalized variant R is the natural default and preserves the $\widetilde{\mathcal{O}}(T^{-1/4})$ stationarity guarantee of Muon-type methods. In LLaMA2 pretraining on C4, the default R variant consistently outperforms Muon on 130M and 350M models, yielding faster convergence and lower validation perplexity.
Rényi Entropy: A New Token Pruning Metric for Vision Transformers
Mar 29, 2026Vision Transformers (ViTs) achieve state-of-the-art performance but suffer from the $O(N^2)$ complexity of self-attention, making inference costly for high-resolution inputs. To address this bottleneck, token pruning has emerged as a critical technique to accelerate inference. Most existing methods rely on the [CLS] token to estimate patch importance. However, we argue that the [CLS] token can be unreliable in early layers where semantic representations are still immature. As a result, pruning in the early layer often leads to inaccurate importance estimation and unnecessary information loss. In this work, we propose a training-free token importance metric, namely Col-Ln, which is derived from Rényi entropy that enables the identification of informative tokens from the first layer of the network, thereby enabling more reliable pruning in token reduction. Extensive experiments on ViTs and Large Vision-Language Models (LVLMs) demonstrate that our approach consistently outperforms state-of-the-art pruning methods across diverse benchmarks.
Muon+: Towards Better Muon via One Additional Normalization Step
Feb 26, 2026The Muon optimizer has demonstrated promising performance in pre-training large language models through gradient (or momentum) orthogonalization. In this work, we propose a simple yet effective enhancement to Muon, namely Muon+, which introduces an additional normalization step after orthogonalization. We demonstrate the effectiveness of Muon+ through extensive pre-training experiments across a wide range of model scales and architectures. Our evaluation includes GPT-style models ranging from 130M to 774M parameters and LLaMA-style models ranging from 60M to 1B parameters. We comprehensively evaluate the effectiveness of Muon+ in the compute-optimal training regime and further extend the token-to-parameter (T2P) ratio to an industrial level of $\approx 200$. Experimental results show that Muon+ provides a consistent boost on training and validation perplexity over Muon. We provide our code here: https://github.com/K1seki221/MuonPlus.
TEON: Tensorized Orthonormalization Beyond Layer-Wise Muon for Large Language Model Pre-Training
Jan 30, 2026The Muon optimizer has demonstrated strong empirical performance in pre-training large language models by performing matrix-level gradient (or momentum) orthogonalization in each layer independently. In this work, we propose TEON, a principled generalization of Muon that extends orthogonalization beyond individual layers by modeling the gradients of a neural network as a structured higher-order tensor. We present TEON's improved convergence guarantee over layer-wise Muon, and further develop a practical instantiation of TEON based on the theoretical analysis with corresponding ablation. We evaluate our approach on two widely adopted architectures: GPT-style models, ranging from 130M to 774M parameters, and LLaMA-style models, ranging from 60M to 1B parameters. Experimental results show that TEON consistently improves training and validation perplexity across model scales and exhibits strong robustness under various approximate SVD schemes.
BOOST: BOttleneck-Optimized Scalable Training Framework for Low-Rank Large Language Models
Dec 13, 2025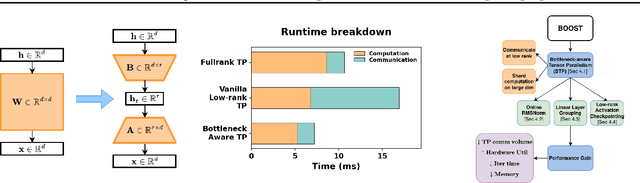

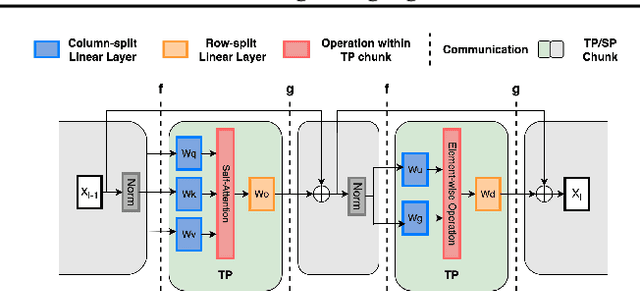
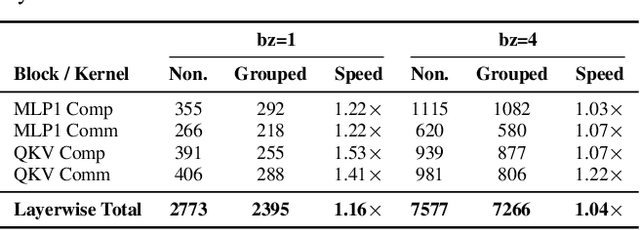
The scale of transformer model pre-training is constrained by the increasing computation and communication cost. Low-rank bottleneck architectures offer a promising solution to significantly reduce the training time and memory footprint with minimum impact on accuracy. Despite algorithmic efficiency, bottleneck architectures scale poorly under standard tensor parallelism. Simply applying 3D parallelism designed for full-rank methods leads to excessive communication and poor GPU utilization. To address this limitation, we propose BOOST, an efficient training framework tailored for large-scale low-rank bottleneck architectures. BOOST introduces a novel Bottleneck-aware Tensor Parallelism, and combines optimizations such as online-RMSNorm, linear layer grouping, and low-rank activation checkpointing to achieve end-to-end training speedup. Evaluations on different low-rank bottleneck architectures demonstrate that BOOST achieves 1.46-1.91$\times$ speedup over full-rank model baselines and 1.87-2.27$\times$ speedup over low-rank model with naively integrated 3D parallelism, with improved GPU utilization and reduced communication overhead.
RaLD: Generating High-Resolution 3D Radar Point Clouds with Latent Diffusion
Nov 10, 2025



Millimeter-wave radar offers a promising sensing modality for autonomous systems thanks to its robustness in adverse conditions and low cost. However, its utility is significantly limited by the sparsity and low resolution of radar point clouds, which poses challenges for tasks requiring dense and accurate 3D perception. Despite that recent efforts have shown great potential by exploring generative approaches to address this issue, they often rely on dense voxel representations that are inefficient and struggle to preserve structural detail. To fill this gap, we make the key observation that latent diffusion models (LDMs), though successful in other modalities, have not been effectively leveraged for radar-based 3D generation due to a lack of compatible representations and conditioning strategies. We introduce RaLD, a framework that bridges this gap by integrating scene-level frustum-based LiDAR autoencoding, order-invariant latent representations, and direct radar spectrum conditioning. These insights lead to a more compact and expressive generation process. Experiments show that RaLD produces dense and accurate 3D point clouds from raw radar spectrums, offering a promising solution for robust perception in challenging environments.