 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Distillation Network for Multi-Agent Reinforcement Learning
Feb 05, 2025



Multi-agent reinforcement learning typically employs a centralized training-decentralized execution (CTDE) framework to alleviate the non-stationarity in environment. However, the partial observability during execution may lead to cumulative gap errors gathered by agents, impairing the training of effective collaborative policies. To overcome this challenge, we introduce the Double Distillation Network (DDN), which incorporates two distillation modules aimed at enhancing robust coordination and facilitating the collaboration process under constrained information. The external distillation module uses a global guiding network and a local policy network, employing distillation to reconcile the gap between global training and local execution. In addition, the internal distillation module introduces intrinsic rewards, drawn from state information, to enhance the exploration capabilities of agents. Extensive experiments demonstrate that DDN significantly improves performance across multiple scenarios.
Optimistic ε-Greedy Exploration for Cooperative Multi-Agent Reinforcement Learning
Feb 05, 2025The Centralized Training with Decentralized Execution (CTDE) paradigm is widely used in cooperative multi-agent reinforcement learning. However, due to the representational limitations of traditional monotonic value decomposition methods, algorithms can underestimate optimal actions, leading policies to suboptimal solutions. To address this challenge, we propose Optimistic $\epsilon$-Greedy Exploration, focusing on enhancing exploration to correct value estimations. The underestimation arises from insufficient sampling of optimal actions during exploration, as our analysis indicated. We introduce an optimistic updating network to identify optimal actions and sample actions from its distribution with a probability of $\epsilon$ during exploration, increasing the selection frequency of optimal actions. Experimental results in various environments reveal that the Optimistic $\epsilon$-Greedy Exploration effectively prevents the algorithm from suboptimal solutions and significantly improves its performance compared to other algorithms.
Large-scale Multi-view Subspace Clustering in Linear Time
Nov 21, 2019


A plethora of multi-view subspace clustering (MVSC) methods have been proposed over the past few years. Researchers manage to boost clustering accuracy from different points of view. However, many state-of-the-art MVSC algorithms, typically have a quadratic or even cubic complexity, are inefficient and inherently difficult to apply at large scales. In the era of big data, the computational issue becomes critical. To fill this gap, we propose a large-scale MVSC (LMVSC) algorithm with linear order complexity. Inspired by the idea of anchor graph, we first learn a smaller graph for each view. Then, a novel approach is designed to integrate those graphs so that we can implement spectral clustering on a smaller graph. Interestingly, it turns out that our model also applies to single-view scenario. Extensive experiments on various large-scale benchmark data sets validate the effectiveness and efficiency of our approach with respect to state-of-the-art clustering methods.
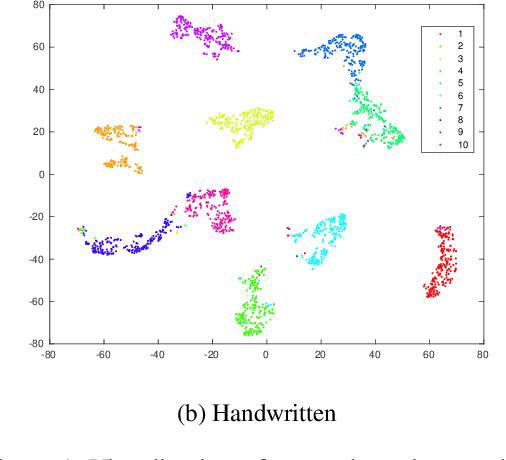
Latent Multi-view Semi-Supervised Classification
Sep 09, 2019
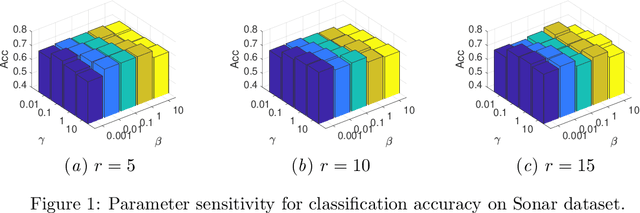
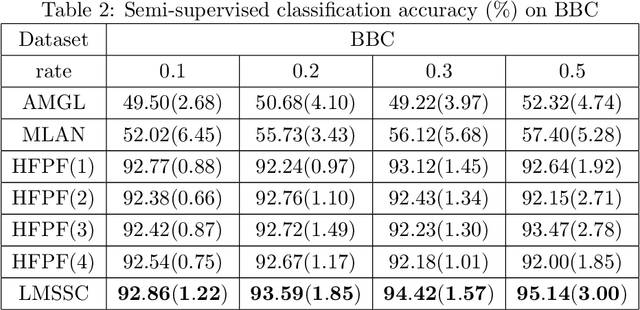
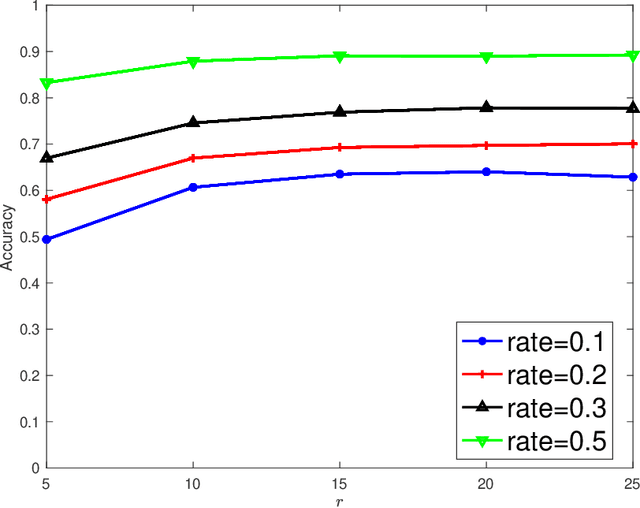
To explore underlying complementary information from multiple views, in this paper, we propose a novel Latent Multi-view Semi-Supervised Classification (LMSSC) method. Unlike most existing multi-view semi-supervised classification methods that learn the graph using original features, our method seeks an underlying latent representation and performs graph learning and label propagation based on the learned latent representation. With the complementarity of multiple views, the latent representation could depict the data more comprehensively than every single view individually, accordingly making the graph more accurate and robust as well. Finally, LMSSC integrates latent representation learning, graph construction, and label propagation into a unified framework, which makes each subtask optimized. Experimental results on real-world benchmark datasets validate the effectiveness of our proposed method.