 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Fine-Grained Prototype Distribution for Boosting Unsupervised Class Incremental Learning
Aug 19, 2024The dynamic nature of open-world scenarios has attracted more attention to class incremental learning (CIL). However, existing CIL methods typically presume the availability of complete ground-truth labels throughout the training process, an assumption rarely met in practical applications. Consequently, this paper explores a more challenging problem of unsupervised class incremental learning (UCIL). The essence of addressing this problem lies in effectively capturing comprehensive feature representations and discovering unknown novel classes. To achieve this, we first model the knowledge of class distribution by exploiting fine-grained prototypes. Subsequently, a granularity alignment technique is introduced to enhance the unsupervised class discovery. Additionally, we proposed a strategy to minimize overlap between novel and existing classes, thereby preserving historical knowledge and mitigating the phenomenon of catastrophic forgetting. Extensive experiments on the five datasets demonstrate that our approach significantly outperforms current state-of-the-art methods, indicating the effectiveness of the proposed method.
Seeing Is Not Always Believing: Invisible Collision Attack and Defence on Pre-Trained Models
Sep 24, 2023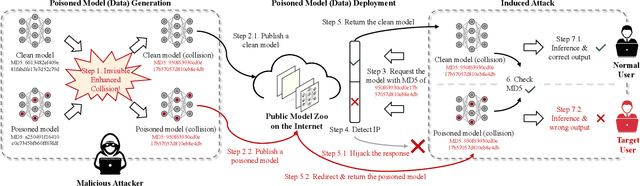
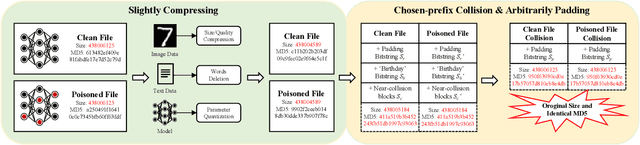
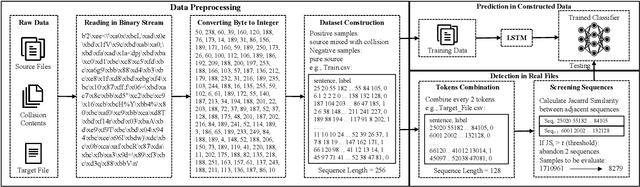
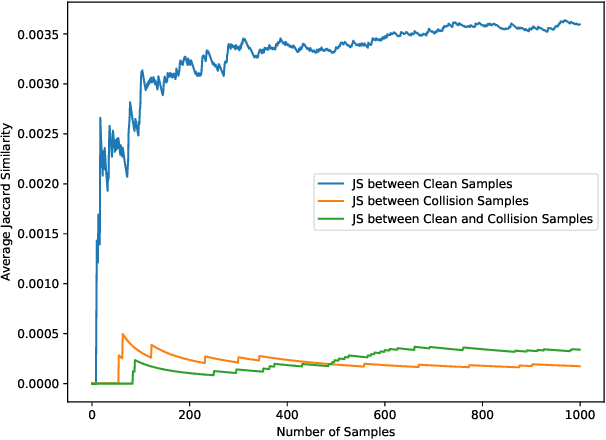
Large-scale pre-trained models (PTMs) such as BERT and GPT have achieved great success in diverse fields. The typical paradigm is to pre-train a big deep learning model on large-scale data sets, and then fine-tune the model on small task-specific data sets for downstream tasks. Although PTMs have rapidly progressed with wide real-world applications, they also pose significant risks of potential attacks. Existing backdoor attacks or data poisoning methods often build up the assumption that the attacker invades the computers of victims or accesses the target data, which is challenging in real-world scenarios. In this paper, we propose a novel framework for an invisible attack on PTMs with enhanced MD5 collision. The key idea is to generate two equal-size models with the same MD5 checksum by leveraging the MD5 chosen-prefix collision. Afterwards, the two ``same" models will be deployed on public websites to induce victims to download the poisoned model. Unlike conventional attacks on deep learning models, this new attack is flexible, covert, and model-independent. Additionally, we propose a simple defensive strategy for recognizing the MD5 chosen-prefix collision and provide a theoretical justification for its feasibility. We extensively validate the effectiveness and stealthiness of our proposed attack and defensive method on different models and data sets.
Fine-tuning Happens in Tiny Subspaces: Exploring Intrinsic Task-specific Subspaces of Pre-trained Language Models
May 27, 2023



Pre-trained language models (PLMs) are known to be overly parameterized and have significant redundancy, indicating a small degree of freedom of the PLMs. Motivated by the observation, in this paper, we study the problem of re-parameterizing and fine-tuning PLMs from a new perspective: Discovery of intrinsic task-specific subspace. Specifically, by exploiting the dynamics of the fine-tuning process for a given task, the parameter optimization trajectory is learned to uncover its intrinsic task-specific subspace. A key finding is that PLMs can be effectively fine-tuned in the subspace with a small number of free parameters. Beyond, we observe some outlier dimensions emerging during fine-tuning in the subspace. Disabling these dimensions degrades the model performance significantly. This suggests that these dimensions are crucial to induce task-specific knowledge to downstream tasks.
Open-world Semi-supervised Novel Class Discovery
May 22, 2023Traditional semi-supervised learning tasks assume that both labeled and unlabeled data follow the same class distribution, but the realistic open-world scenarios are of more complexity with unknown novel classes mixed in the unlabeled set. Therefore, it is of great challenge to not only recognize samples from known classes but also discover the unknown number of novel classes within the unlabeled data. In this paper, we introduce a new open-world semi-supervised novel class discovery approach named OpenNCD, a progressive bi-level contrastive learning method over multiple prototypes. The proposed method is composed of two reciprocally enhanced parts. First, a bi-level contrastive learning method is introduced, which maintains the pair-wise similarity of the prototypes and the prototype group levels for better representation learning. Then, a reliable prototype similarity metric is proposed based on the common representing instances. Prototypes with high similarities will be grouped progressively for known class recognition and novel class discovery. Extensive experiments on three image datasets are conducted and the results show the effectiveness of the proposed method in open-world scenarios, especially with scarce known classes and labels.
An Interpretable Neuron Embedding for Static Knowledge Distillation
Nov 14, 2022



Although deep neural networks have shown well-performance in various tasks, the poor interpretability of the models is always criticized. In the paper, we propose a new interpretable neural network method, by embedding neurons into the semantic space to extract their intrinsic global semantics. In contrast to previous methods that probe latent knowledge inside the model, the proposed semantic vector externalizes the latent knowledge to static knowledge, which is easy to exploit. Specifically, we assume that neurons with similar activation are of similar semantic information. Afterwards, semantic vectors are optimized by continuously aligning activation similarity and semantic vector similarity during the training of the neural network. The visualization of semantic vectors allows for a qualitative explanation of the neural network. Moreover, we assess the static knowledge quantitatively by knowledge distillation tasks. Empirical experiments of visualization show that semantic vectors describe neuron activation semantics well. Without the sample-by-sample guidance from the teacher model, static knowledge distillation exhibit comparable or even superior performance with existing relation-based knowledge distillation methods.
A Subword Guided Neural Word Segmentation Model for Sindhi
Dec 30, 2020
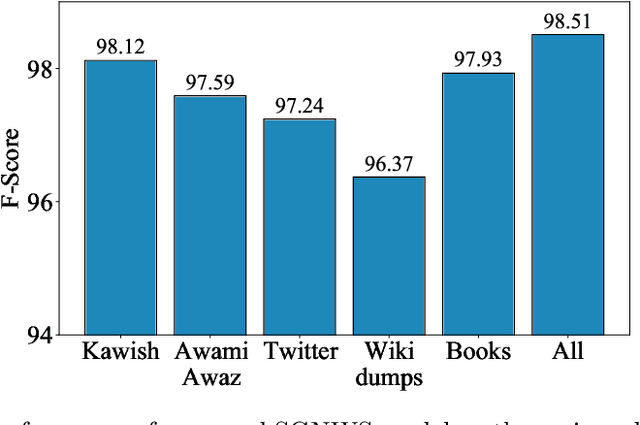

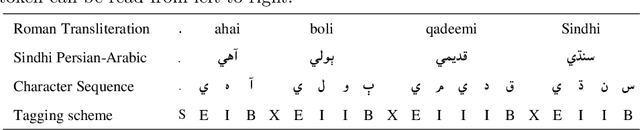
Deep neural networks employ multiple processing layers for learning text representations to alleviate the burden of manual feature engineering in Natural Language Processing (NLP). Such text representations are widely used to extract features from unlabeled data. The word segmentation is a fundamental and inevitable prerequisite for many languages. Sindhi is an under-resourced language, whose segmentation is challenging as it exhibits space omission, space insertion issues, and lacks the labeled corpus for segmentation. In this paper, we investigate supervised Sindhi Word Segmentation (SWS) using unlabeled data with a Subword Guided Neural Word Segmenter (SGNWS) for Sindhi. In order to learn text representations, we incorporate subword representations to recurrent neural architecture to capture word information at morphemic-level, which takes advantage of Bidirectional Long-Short Term Memory (BiLSTM), self-attention mechanism, and Conditional Random Field (CRF). Our proposed SGNWS model achieves an F1 value of 98.51% without relying on feature engineering. The empirical results demonstrate the benefits of the proposed model over the existing Sindhi word segmenters.
Large-scale Multi-view Subspace Clustering in Linear Time
Nov 21, 2019


A plethora of multi-view subspace clustering (MVSC) methods have been proposed over the past few years. Researchers manage to boost clustering accuracy from different points of view. However, many state-of-the-art MVSC algorithms, typically have a quadratic or even cubic complexity, are inefficient and inherently difficult to apply at large scales. In the era of big data, the computational issue becomes critical. To fill this gap, we propose a large-scale MVSC (LMVSC) algorithm with linear order complexity. Inspired by the idea of anchor graph, we first learn a smaller graph for each view. Then, a novel approach is designed to integrate those graphs so that we can implement spectral clustering on a smaller graph. Interestingly, it turns out that our model also applies to single-view scenario. Extensive experiments on various large-scale benchmark data sets validate the effectiveness and efficiency of our approach with respect to state-of-the-art clustering methods.
Learning in High-Dimensional Multimedia Data: The State of the Art
Jul 10, 2017
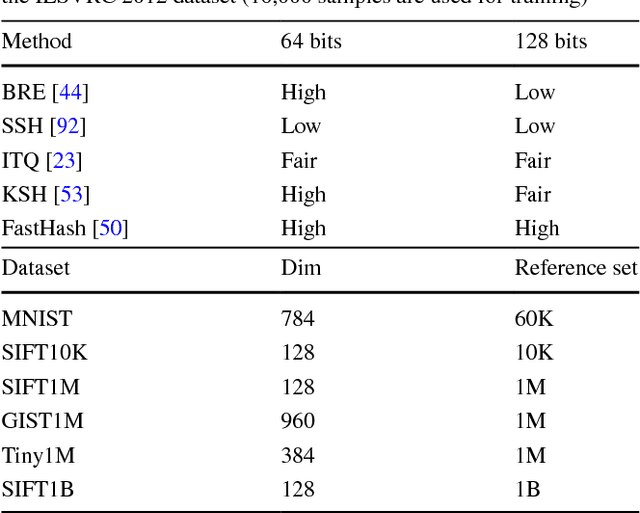
During the last decade, the deluge of multimedia data has impacted a wide range of research areas, including multimedia retrieval, 3D tracking, database management, data mining, machine learning, social media analysis, medical imaging, and so on. Machine learning is largely involved in multimedia applications of building models for classification and regression tasks etc., and the learning principle consists in designing the models based on the information contained in the multimedia dataset. While many paradigms exist and are widely used in the context of machine learning, most of them suffer from the `curse of dimensionality', which means that some strange phenomena appears when data are represented in a high-dimensional space. Given the high dimensionality and the high complexity of multimedia data, it is important to investigate new machine learning algorithms to facilitate multimedia data analysis. To deal with the impact of high dimensionality, an intuitive way is to reduce the dimensionality. On the other hand, some researchers devoted themselves to designing some effective learning schemes for high-dimensional data. In this survey, we cover feature transformation, feature selection and feature encoding, three approaches fighting the consequences of the curse of dimensionality. Next, we briefly introduce some recent progress of effective learning algorithms. Finally, promising future trends on multimedia learning are envisaged.