 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRényi Sharpness: A Novel Sharpness that Strongly Correlates with Generalization
Oct 09, 2025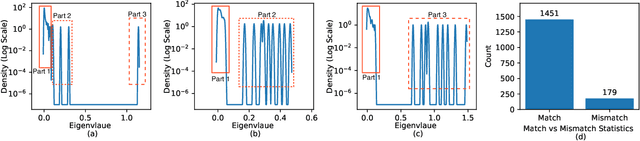
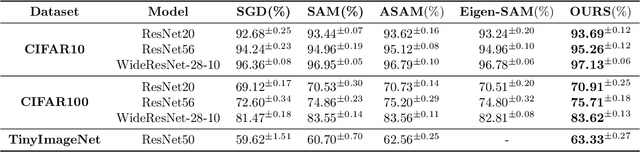
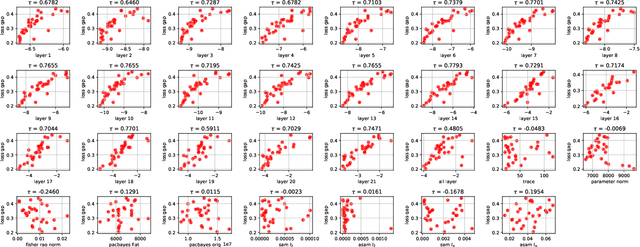
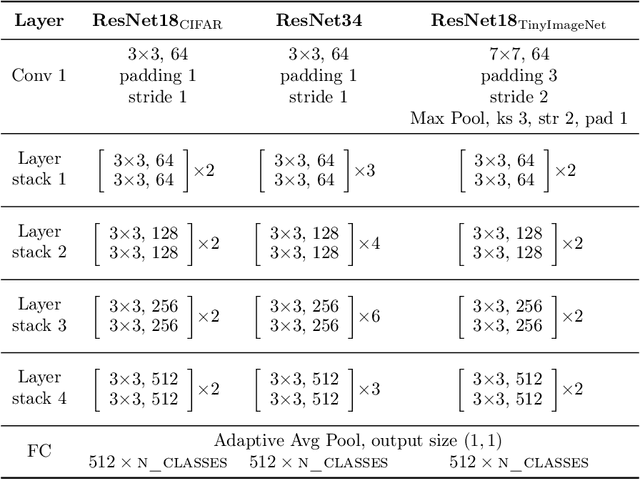
Sharpness (of the loss minima) is a common measure to investigate the generalization of neural networks. Intuitively speaking, the flatter the landscape near the minima is, the better generalization might be. Unfortunately, the correlation between many existing sharpness measures and the generalization is usually not strong, sometimes even weak. To close the gap between the intuition and the reality, we propose a novel sharpness measure, i.e., \textit{R\'enyi sharpness}, which is defined as the negative R\'enyi entropy (a generalization of the classical Shannon entropy) of the loss Hessian. The main ideas are as follows: 1) we realize that \textit{uniform} (identical) eigenvalues of the loss Hessian is most desirable (while keeping the sum constant) to achieve good generalization; 2) we employ the \textit{R\'enyi entropy} to concisely characterize the extent of the spread of the eigenvalues of loss Hessian. Normally, the larger the spread, the smaller the (R\'enyi) entropy. To rigorously establish the relationship between generalization and (R\'enyi) sharpness, we provide several generalization bounds in terms of R\'enyi sharpness, by taking advantage of the reparametrization invariance property of R\'enyi sharpness, as well as the trick of translating the data discrepancy to the weight perturbation. Furthermore, extensive experiments are conducted to verify the strong correlation (in specific, Kendall rank correlation) between the R\'enyi sharpness and generalization. Moreover, we propose to use a variant of R\'enyi Sharpness as regularizer during training, i.e., R\'enyi Sharpness Aware Minimization (RSAM), which turns out to outperform all existing sharpness-aware minimization methods. It is worthy noting that the test accuracy gain of our proposed RSAM method could be as high as nearly 2.5\%, compared against the classical SAM method.
How Sparse Can We Prune A Deep Network: A Geometric Viewpoint
Jun 09, 2023



Overparameterization constitutes one of the most significant hallmarks of deep neural networks. Though it can offer the advantage of outstanding generalization performance, it meanwhile imposes substantial storage burden, thus necessitating the study of network pruning. A natural and fundamental question is: How sparse can we prune a deep network (with almost no hurt on the performance)? To address this problem, in this work we take a first principles approach, specifically, by merely enforcing the sparsity constraint on the original loss function, we're able to characterize the sharp phase transition point of pruning ratio, which corresponds to the boundary between the feasible and the infeasible, from the perspective of high-dimensional geometry. It turns out that the phase transition point of pruning ratio equals the squared Gaussian width of some convex body resulting from the $l_1$-regularized loss function, normalized by the original dimension of parameters. As a byproduct, we provide a novel network pruning algorithm which is essentially a global one-shot pruning one. Furthermore, we provide efficient countermeasures to address the challenges in computing the involved Gaussian width, including the spectrum estimation of a large-scale Hessian matrix and dealing with the non-definite positiveness of a Hessian matrix. It is demonstrated that the predicted pruning ratio threshold coincides very well with the actual value obtained from the experiments and our proposed pruning algorithm can achieve competitive or even better performance than the existing pruning algorithms. All codes are available at: https://github.com/QiaozheZhang/Global-One-shot-Pruning
Multi-level Multiple Instance Learning with Transformer for Whole Slide Image Classification
Jun 08, 2023



Whole slide image (WSI) refers to a type of high-resolution scanned tissue image, which is extensively employed in computer-assisted diagnosis (CAD). The extremely high resolution and limited availability of region-level annotations make it challenging to employ deep learning methods for WSI-based digital diagnosis. Multiple instance learning (MIL) is a powerful tool to address the weak annotation problem, while Transformer has shown great success in the field of visual tasks. The combination of both should provide new insights for deep learning based image diagnosis. However, due to the limitations of single-level MIL and the attention mechanism's constraints on sequence length, directly applying Transformer to WSI-based MIL tasks is not practical. To tackle this issue, we propose a Multi-level MIL with Transformer (MMIL-Transformer) approach. By introducing a hierarchical structure to MIL, this approach enables efficient handling of MIL tasks that involve a large number of instances. To validate its effectiveness, we conducted a set of experiments on WSIs classification task, where MMIL-Transformer demonstrate superior performance compared to existing state-of-the-art methods. Our proposed approach achieves test AUC 94.74% and test accuracy 93.41% on CAMELYON16 dataset, test AUC 99.04% and test accuracy 94.37% on TCGA-NSCLC dataset, respectively. All code and pre-trained models are available at: https://github.com/hustvl/MMIL-Transformer