 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransDex: Pre-training Visuo-Tactile Policy with Point Cloud Reconstruction for Dexterous Manipulation of Transparent Objects
Mar 14, 2026Dexterous manipulation enables complex tasks but suffers from self-occlusion, severe depth noise, and depth information loss when manipulating transparent objects. To solve this problem, this paper proposes TransDex, a 3D visuo-tactile fusion motor policy based on point cloud reconstruction pre-training. Specifically, we first propose a self-supervised point cloud reconstruction pre-training approach based on Transformer. This method accurately recovers the 3D structure of objects from interactive point clouds of dexterous hands, even when random noise and large-scale masking are added. Building on this, TransDex is constructed in which perceptual encoding adopts a fine-grained hierarchical scheme and multi-round attention mechanisms adaptively fuse features of the robotic arm and dexterous hand to enable differentiated motion prediction. Results from transparent object manipulation experiments conducted on a real robotic system demonstrate that TransDex outperforms existing baseline methods. Further analysis validates the generalization capabilities of TransDex and the effectiveness of its individual components.
Low-Complexity CSI Feedback for FDD Massive MIMO Systems via Learning to Optimize
Jun 24, 2024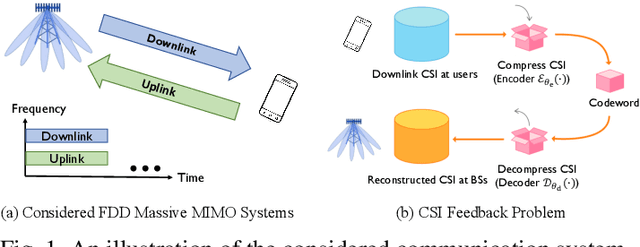
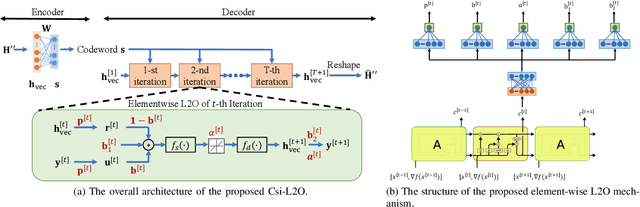
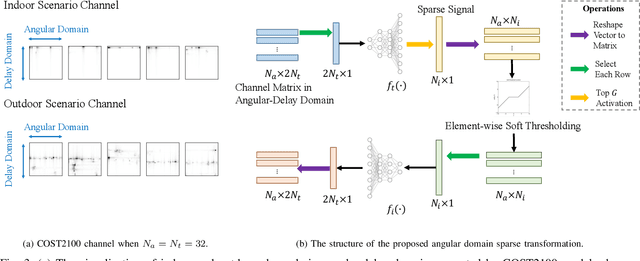
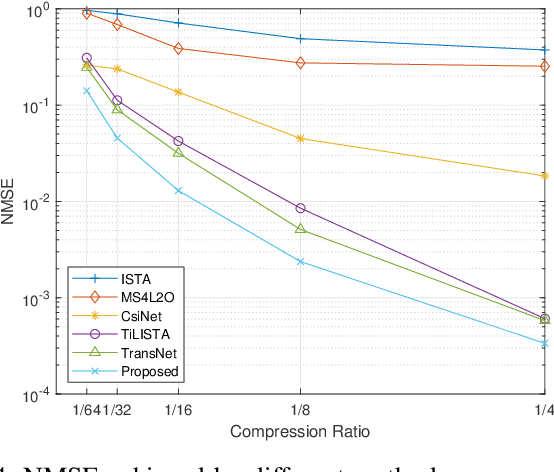
In frequency-division duplex (FDD) massive multiple-input multiple-output (MIMO) systems, the growing number of base station antennas leads to prohibitive feedback overhead for downlink channel state information (CSI). To address this challenge, state-of-the-art (SOTA) fully data-driven deep learning (DL)-based CSI feedback schemes have been proposed. However, the high computational complexity and memory requirements of these methods hinder their practical deployment on resource-constrained devices like mobile phones. To solve the problem, we propose a model-driven DL-based CSI feedback approach by integrating the wisdom of compressive sensing and learning to optimize (L2O). Specifically, only a linear learnable projection is adopted at the encoder side to compress the CSI matrix, thereby significantly cutting down the user-side complexity and memory expenditure. On the other hand, the decoder incorporates two specially designed components, i.e., a learnable sparse transformation and an element-wise L2O reconstruction module. The former is developed to learn a sparse basis for CSI within the angular domain, which explores channel sparsity effectively. The latter shares the same long short term memory (LSTM) network across all elements of the optimization variable, eliminating the retraining cost when problem scale changes. Simulation results show that the proposed method achieves a comparable performance with the SOTA CSI feedback scheme but with much-reduced complexity, and enables multiple-rate feedback.
AI-Native Transceiver Design for Near-Field Ultra-Massive MIMO: Principles and Techniques
Sep 18, 2023



Ultra-massive multiple-input multiple-output (UM-MIMO) is a cutting-edge technology that promises to revolutionize wireless networks by providing an unprecedentedly high spectral and energy efficiency. The enlarged array aperture of UM-MIMO facilitates the accessibility of the near-field region, thereby offering a novel degree of freedom for communications and sensing. Nevertheless, the transceiver design for such systems is challenging because of the enormous system scale, the complicated channel characteristics, and the uncertainties in propagation environments. Therefore, it is critical to study scalable, low-complexity, and robust algorithms that can efficiently characterize and leverage the properties of the near-field channel. In this article, we will advocate two general frameworks from an artificial intelligence (AI)-native perspective, which are tailored for the algorithmic design of near-field UM-MIMO transceivers. Specifically, the frameworks for both iterative and non-iterative algorithms are discussed. Near-field beam focusing and channel estimation are presented as two tutorial-style examples to demonstrate the significant advantages of the proposed AI-native frameworks in terms of various key performance indicators.
Lightweight and Adaptive FDD Massive MIMO CSI Feedback with Deep Equilibrium Learning
Nov 28, 2022



In frequency-division duplexing (FDD) massive multiple-input multiple-output (MIMO) systems, downlink channel state information (CSI) needs to be sent from users back to the base station (BS), which causes prohibitive feedback overhead. In this paper, we propose a lightweight and adaptive deep learning-based CSI feedback scheme by capitalizing on deep equilibrium models. Different from existing deep learning-based approaches that stack multiple explicit layers, we propose an implicit equilibrium block to mimic the process of an infinite-depth neural network. In particular, the implicit equilibrium block is defined by a fixed-point iteration and the trainable parameters in each iteration are shared, which results in a lightweight model. Furthermore, the number of forward iterations can be adjusted according to the users' computational capability, achieving an online accuracy-efficiency trade-off. Simulation results will show that the proposed method obtains a comparable performance as the existing benchmarks but with much-reduced complexity and permits an accuracy-efficiency trade-off at runtime.
Augmented Deep Unfolding for Downlink Beamforming in Multi-cell Massive MIMO With Limited Feedback
Sep 03, 2022
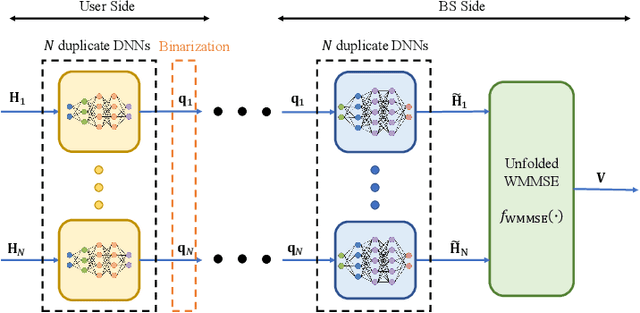
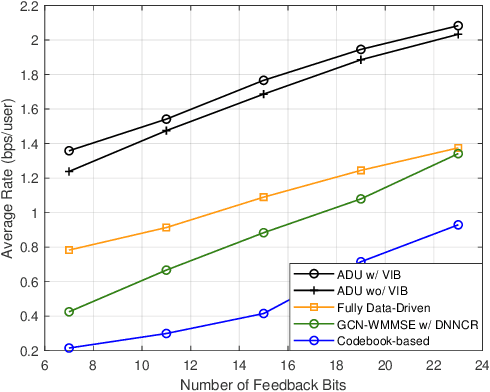
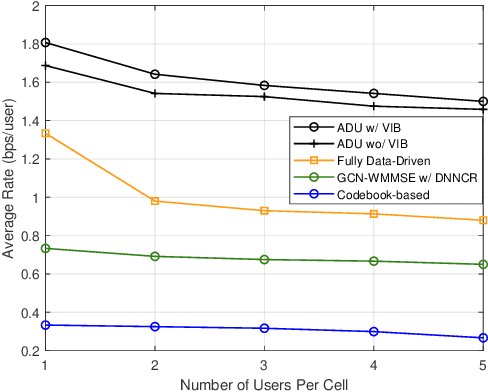
In limited feedback multi-user multiple-input multiple-output (MU-MIMO) cellular networks, users send quantized information about the channel conditions to the associated base station (BS) for downlink beamforming. However, channel quantization and beamforming have been treated as two separate tasks conventionally, which makes it difficult to achieve global system optimality. In this paper, we propose an augmented deep unfolding (ADU) approach that jointly optimizes the beamforming scheme at the BSs and the channel quantization scheme at the users. In particular, the classic WMMSE beamformer is unrolled and a deep neural network (DNN) is leveraged to pre-process its input to enhance the performance. The variational information bottleneck technique is adopted to further improve the performance when the feedback capacity is strictly restricted. Simulation results demonstrate that the proposed ADU method outperforms all the benchmark schemes in terms of the system average rate.
Learn to Communicate with Neural Calibration: Scalability and Generalization
Oct 01, 2021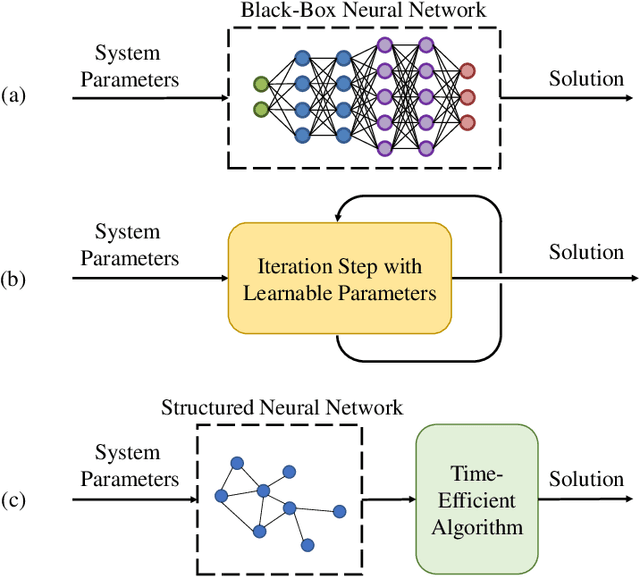
The conventional design of wireless communication systems typically relies on established mathematical models that capture the characteristics of different communication modules. Unfortunately, such design cannot be easily and directly applied to future wireless networks, which will be characterized by large-scale ultra-dense networks whose design complexity scales exponentially with the network size. Furthermore, such networks will vary dynamically in a significant way, which makes it intractable to develop comprehensive analytical models. Recently, deep learning-based approaches have emerged as potential alternatives for designing complex and dynamic wireless systems. However, existing learning-based methods have limited capabilities to scale with the problem size and to generalize with varying network settings. In this paper, we propose a scalable and generalizable neural calibration framework for future wireless system design, where a neural network is adopted to calibrate the input of conventional model-based algorithms. Specifically, the backbone of a traditional time-efficient algorithm is integrated with deep neural networks to achieve a high computational efficiency, while enjoying enhanced performance. The permutation equivariance property, carried out by the topological structure of wireless systems, is furthermore utilized to develop a generalizable neural network architecture. The proposed neural calibration framework is applied to solve challenging resource management problems in massive multiple-input multiple-output (MIMO) systems. Simulation results will show that the proposed neural calibration approach enjoys significantly improved scalability and generalization compared with the existing learning-based methods.
Neural Calibration for Scalable Beamforming in FDD Massive MIMO with Implicit Channel Estimation
Aug 03, 2021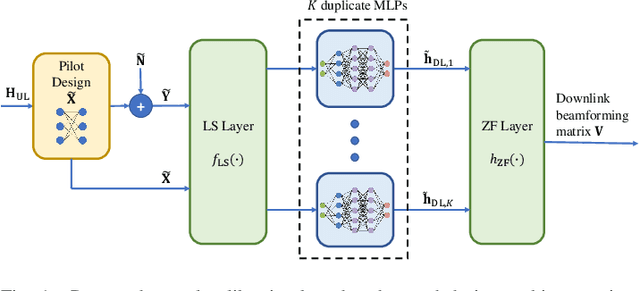
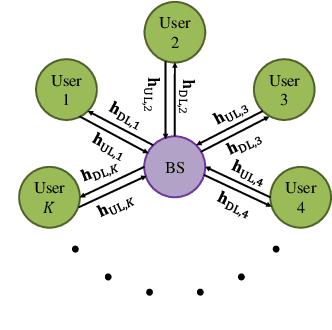
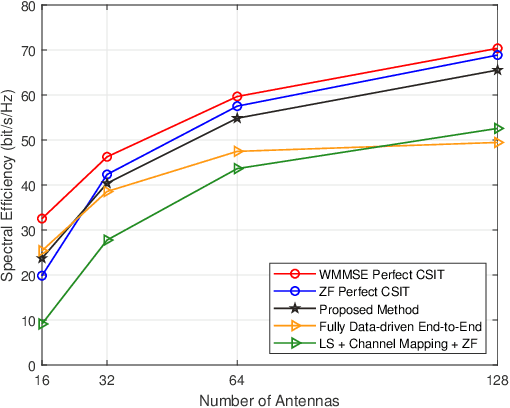
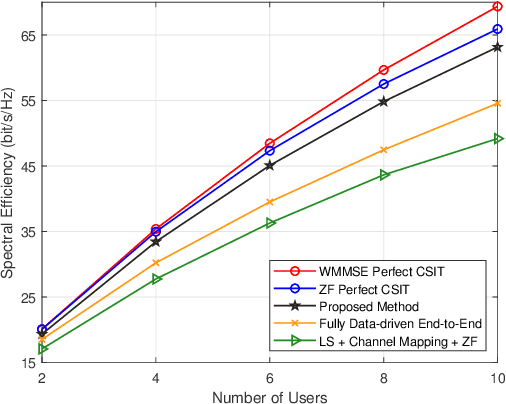
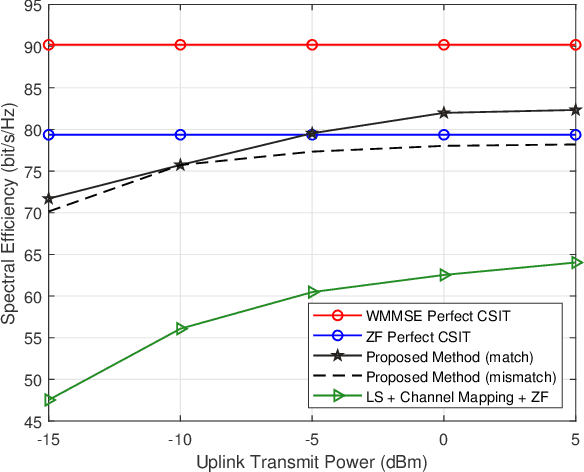
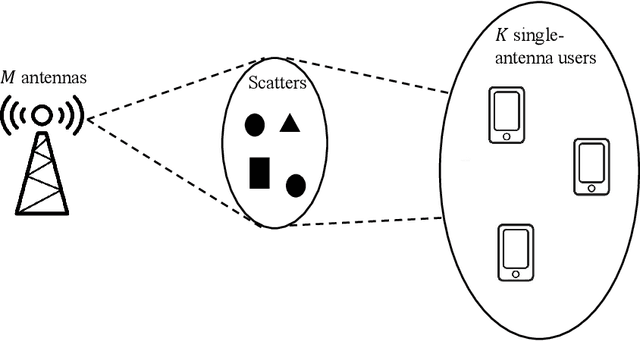
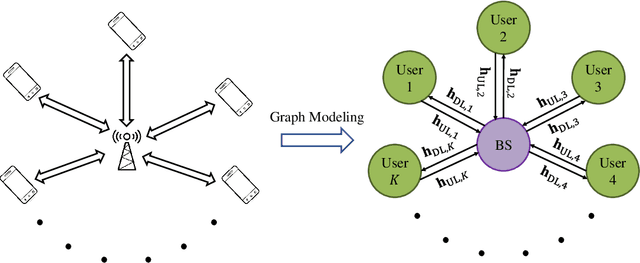
Channel estimation and beamforming play critical roles in frequency-division duplexing (FDD) massive multiple-input multiple-output (MIMO) systems. However, these two modules have been treated as two stand-alone components, which makes it difficult to achieve a global system optimality. In this paper, we propose a deep learning-based approach that directly optimizes the beamformers at the base station according to the received uplink pilots, thereby, bypassing the explicit channel estimation. Different from the existing fully data-driven approach where all the modules are replaced by deep neural networks (DNNs), a neural calibration method is proposed to improve the scalability of the end-to-end design. In particular, the backbone of conventional time-efficient algorithms, i.e., the least-squares (LS) channel estimator and the zero-forcing (ZF) beamformer, is preserved and DNNs are leveraged to calibrate their inputs for better performance. The permutation equivariance property of the formulated resource allocation problem is then identified to design a low-complexity neural network architecture. Simulation results will show the superiority of the proposed neural calibration method over benchmark schemes in terms of both the spectral efficiency and scalability in large-scale wireless networks.
Automated Prostate Cancer Diagnosis Based on Gleason Grading Using Convolutional Neural Network
Nov 29, 2020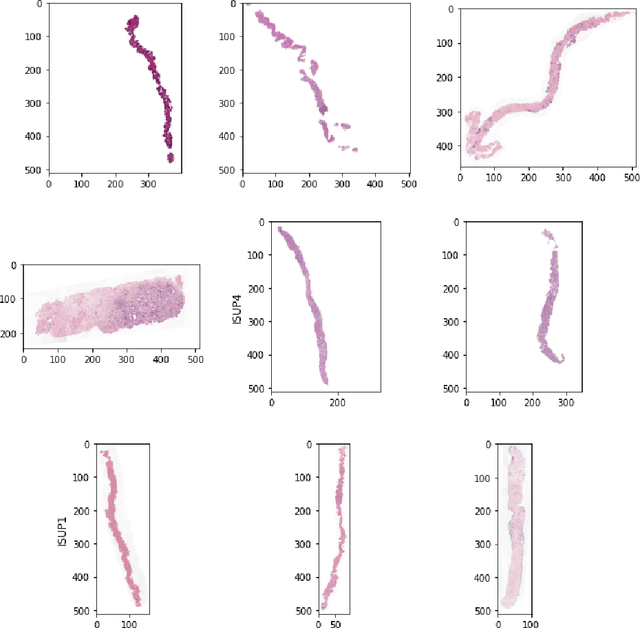
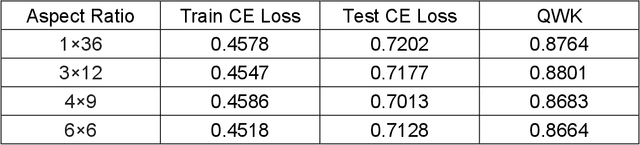
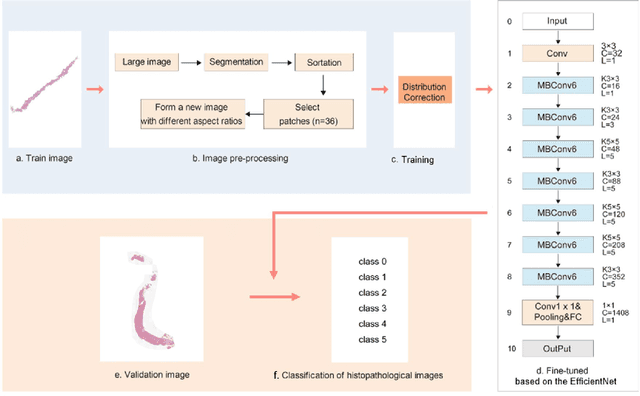
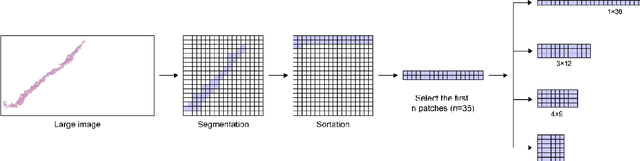
The Gleason grading system using histological images is the most powerful diagnostic and prognostic predictor of prostate cancer. The current standard inspection is evaluating Gleason H&E-stained histopathology images by pathologists. However, it is complicated, time-consuming, and subject to observers. Deep learning (DL) based-methods that automatically learn image features and achieve higher generalization ability have attracted significant attention. However, challenges remain especially using DL to train the whole slide image (WSI), a predominant clinical source in the current diagnostic setting, containing billions of pixels, morphological heterogeneity, and artifacts. Hence, we proposed a convolutional neural network (CNN)-based automatic classification method for accurate grading of PCa using whole slide histopathology images. In this paper, a data augmentation method named Patch-Based Image Reconstruction (PBIR) was proposed to reduce the high resolution and increase the diversity of WSIs. In addition, a distribution correction (DC) module was developed to enhance the adaption of pretrained model to the target dataset by adjusting the data distribution. Besides, a Quadratic Weighted Mean Square Error (QWMSE) function was presented to reduce the misdiagnosis caused by equal Euclidean distances. Our experiments indicated the combination of PBIR, DC, and QWMSE function was necessary for achieving superior expert-level performance, leading to the best results (0.8885 quadratic-weighted kappa coefficient).