 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle or Content? Evaluating Style Classifiers with Controlled Content Overlap
Jun 05, 2026Style classifiers can use content cues that correlate with style labels in naturally collected data, yet we lack a systematic way to measure this reliance. We study this problem with a controlled content overlap setup built on parallel Bible translations. Specifically, we define the overlap parameter $α$ as the normalized residual of mutual information between content identity and style label, so that it measures how much content is shared across style classes: from no shared content ($α=0$) to fully shared content ($α=1$). Cross-overlap evaluation of RoBERTa-based classifiers shows that low-overlap models degrade when content cues are removed, while high-overlap models transfer more robustly. A cross-style content retrieval probe further shows that content becomes less recoverable as $α$ increases, with training dynamics showing this removal occurs gradually. Together, these results suggest that controlled overlap provides a simple diagnostic for separating style learning from content shortcuts.
Contrastive Predictive Coding Done Right for Mutual Information Estimation
Oct 29, 2025The InfoNCE objective, originally introduced for contrastive representation learning, has become a popular choice for mutual information (MI) estimation, despite its indirect connection to MI. In this paper, we demonstrate why InfoNCE should not be regarded as a valid MI estimator, and we introduce a simple modification, which we refer to as InfoNCE-anchor, for accurate MI estimation. Our modification introduces an auxiliary anchor class, enabling consistent density ratio estimation and yielding a plug-in MI estimator with significantly reduced bias. Beyond this, we generalize our framework using proper scoring rules, which recover InfoNCE-anchor as a special case when the log score is employed. This formulation unifies a broad spectrum of contrastive objectives, including NCE, InfoNCE, and $f$-divergence variants, under a single principled framework. Empirically, we find that InfoNCE-anchor with the log score achieves the most accurate MI estimates; however, in self-supervised representation learning experiments, we find that the anchor does not improve the downstream task performance. These findings corroborate that contrastive representation learning benefits not from accurate MI estimation per se, but from the learning of structured density ratios.
Separable Computation of Information Measures
Jan 25, 2025
We study a separable design for computing information measures, where the information measure is computed from learned feature representations instead of raw data. Under mild assumptions on the feature representations, we demonstrate that a class of information measures admit such separable computation, including mutual information, $f$-information, Wyner's common information, G{\'a}cs--K{\"o}rner common information, and Tishby's information bottleneck. Our development establishes several new connections between information measures and the statistical dependence structure. The characterizations also provide theoretical guarantees of practical designs for estimating information measures through representation learning.
Dependence Induced Representations
Nov 22, 2024We study the problem of learning feature representations from a pair of random variables, where we focus on the representations that are induced by their dependence. We provide sufficient and necessary conditions for such dependence induced representations, and illustrate their connections to Hirschfeld--Gebelein--R\'{e}nyi (HGR) maximal correlation functions and minimal sufficient statistics. We characterize a large family of loss functions that can learn dependence induced representations, including cross entropy, hinge loss, and their regularized variants. In particular, we show that the features learned from this family can be expressed as the composition of a loss-dependent function and the maximal correlation function, which reveals a key connection between representations learned from different losses. Our development also gives a statistical interpretation of the neural collapse phenomenon observed in deep classifiers. Finally, we present the learning design based on the feature separation, which allows hyperparameter tuning during inference.
Jet Expansions of Residual Computation
Oct 08, 2024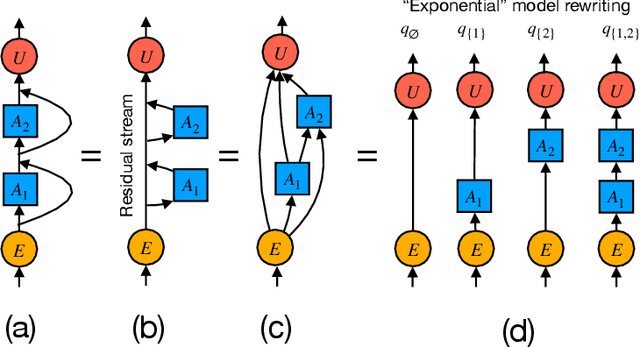

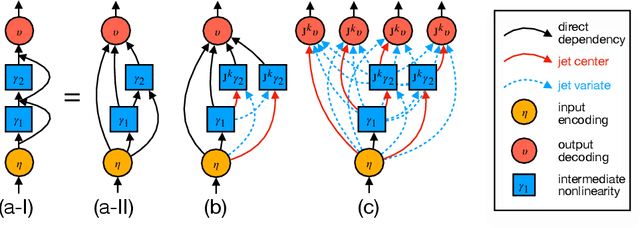
We introduce a framework for expanding residual computational graphs using jets, operators that generalize truncated Taylor series. Our method provides a systematic approach to disentangle contributions of different computational paths to model predictions. In contrast to existing techniques such as distillation, probing, or early decoding, our expansions rely solely on the model itself and requires no data, training, or sampling from the model. We demonstrate how our framework grounds and subsumes logit lens, reveals a (super-)exponential path structure in the recursive residual depth and opens up several applications. These include sketching a transformer large language model with $n$-gram statistics extracted from its computations, and indexing the models' levels of toxicity knowledge. Our approach enables data-free analysis of residual computation for model interpretability, development, and evaluation.
Operator SVD with Neural Networks via Nested Low-Rank Approximation
Feb 06, 2024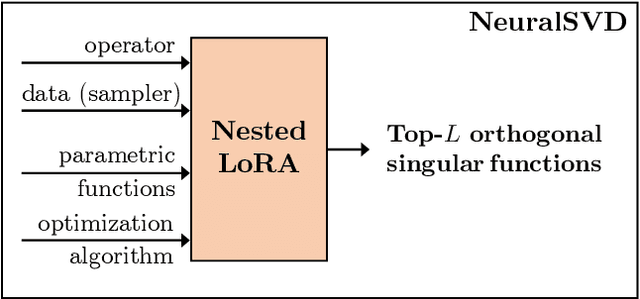
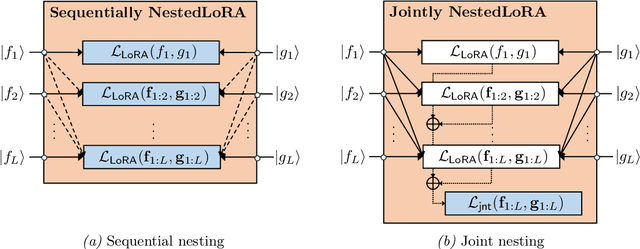

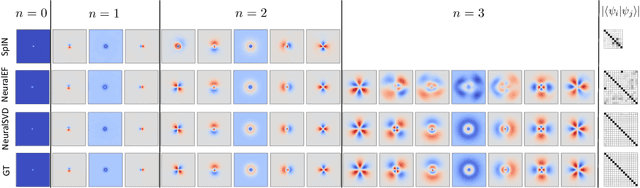
Computing eigenvalue decomposition (EVD) of a given linear operator, or finding its leading eigenvalues and eigenfunctions, is a fundamental task in many machine learning and scientific computing problems. For high-dimensional eigenvalue problems, training neural networks to parameterize the eigenfunctions is considered as a promising alternative to the classical numerical linear algebra techniques. This paper proposes a new optimization framework based on the low-rank approximation characterization of a truncated singular value decomposition, accompanied by new techniques called nesting for learning the top-$L$ singular values and singular functions in the correct order. The proposed method promotes the desired orthogonality in the learned functions implicitly and efficiently via an unconstrained optimization formulation, which is easy to solve with off-the-shelf gradient-based optimization algorithms. We demonstrate the effectiveness of the proposed optimization framework for use cases in computational physics and machine learning.
A Geometric Framework for Neural Feature Learning
Sep 18, 2023



We present a novel framework for learning system design based on neural feature extractors by exploiting geometric structures in feature spaces. First, we introduce the feature geometry, which unifies statistical dependence and features in the same functional space with geometric structures. By applying the feature geometry, we formulate each learning problem as solving the optimal feature approximation of the dependence component specified by the learning setting. We propose a nesting technique for designing learning algorithms to learn the optimal features from data samples, which can be applied to off-the-shelf network architectures and optimizers. To demonstrate the application of the nesting technique, we further discuss multivariate learning problems, including conditioned inference and multimodal learning, where we present the optimal features and reveal their connections to classical approaches.
Kernel Subspace and Feature Extraction
Jan 04, 2023We study kernel methods in machine learning from the perspective of feature subspace. We establish a one-to-one correspondence between feature subspaces and kernels and propose an information-theoretic measure for kernels. In particular, we construct a kernel from Hirschfeld--Gebelein--R\'{e}nyi maximal correlation functions, coined the maximal correlation kernel, and demonstrate its information-theoretic optimality. We use the support vector machine (SVM) as an example to illustrate a connection between kernel methods and feature extraction approaches. We show that the kernel SVM on maximal correlation kernel achieves minimum prediction error. Finally, we interpret the Fisher kernel as a special maximal correlation kernel and establish its optimality.
On Distributed Learning with Constant Communication Bits
Sep 14, 2021
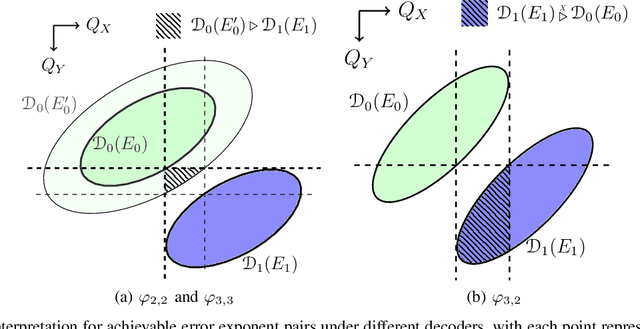
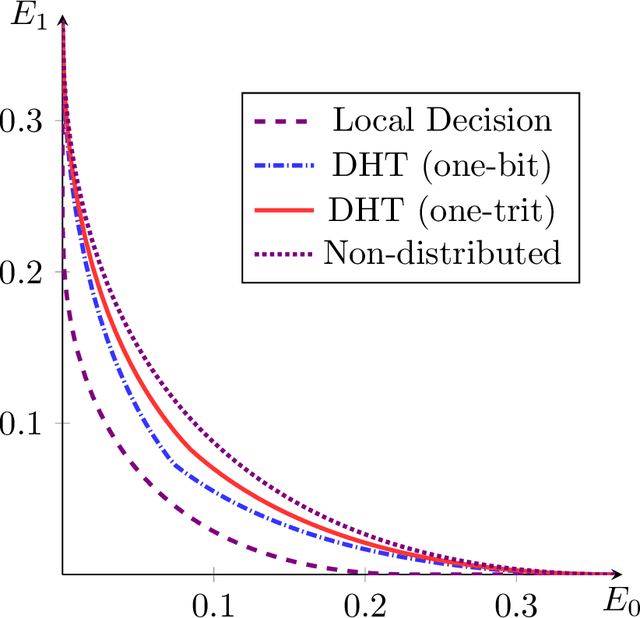

In this paper, we study a distributed learning problem constrained by constant communication bits. Specifically, we consider the distributed hypothesis testing (DHT) problem where two distributed nodes are constrained to transmit a constant number of bits to a central decoder. In such cases, we show that in order to achieve the optimal error exponents, it suffices to consider the empirical distributions of observed data sequences and encode them to the transmission bits. With such a coding strategy, we develop a geometric approach in the distribution spaces and characterize the optimal schemes. In particular, we show the optimal achievable error exponents and coding schemes for the following cases: (i) both nodes can transmit $\log_23$ bits; (ii) one of the nodes can transmit $1$ bit, and the other node is not constrained; (iii) the joint distribution of the nodes are conditionally independent given one hypothesis. Furthermore, we provide several numerical examples for illustrating the theoretical results. Our results provide theoretical guidance for designing practical distributed learning rules, and the developed approach also reveals new potentials for establishing error exponents for DHT with more general communication constraints.
Maximum Likelihood Estimation for Multimodal Learning with Missing Modality
Aug 24, 2021
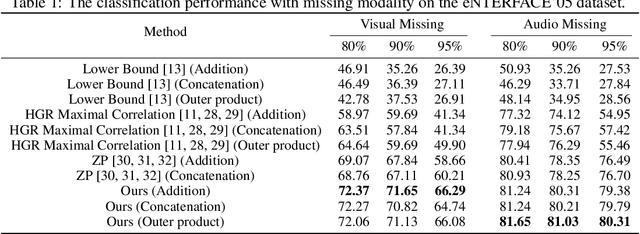
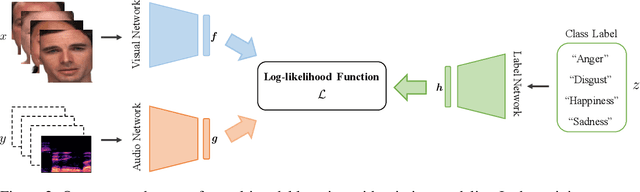
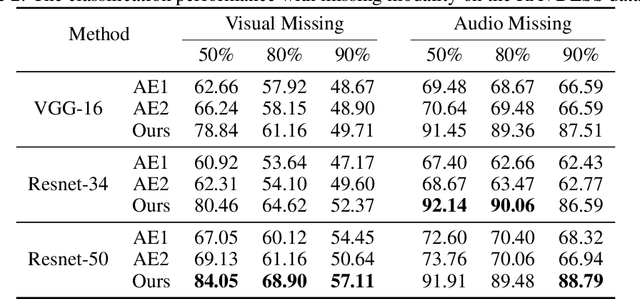
Multimodal learning has achieved great successes in many scenarios. Compared with unimodal learning, it can effectively combine the information from different modalities to improve the performance of learning tasks. In reality, the multimodal data may have missing modalities due to various reasons, such as sensor failure and data transmission error. In previous works, the information of the modality-missing data has not been well exploited. To address this problem, we propose an efficient approach based on maximum likelihood estimation to incorporate the knowledge in the modality-missing data. Specifically, we design a likelihood function to characterize the conditional distribution of the modality-complete data and the modality-missing data, which is theoretically optimal. Moreover, we develop a generalized form of the softmax function to effectively implement maximum likelihood estimation in an end-to-end manner. Such training strategy guarantees the computability of our algorithm capably. Finally, we conduct a series of experiments on real-world multimodal datasets. Our results demonstrate the effectiveness of the proposed approach, even when 95% of the training data has missing modality.