 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperator SVD with Neural Networks via Nested Low-Rank Approximation
Paper and Code
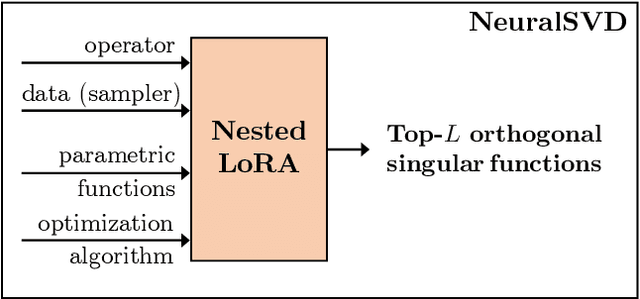
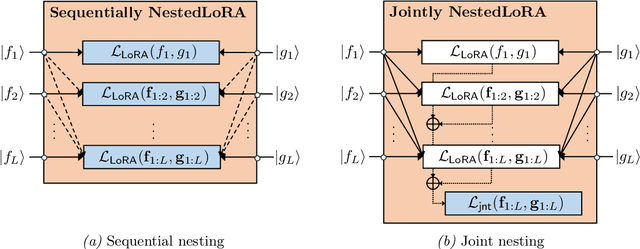

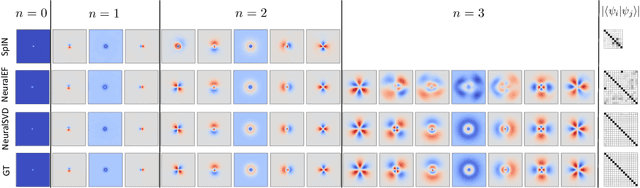
Computing eigenvalue decomposition (EVD) of a given linear operator, or finding its leading eigenvalues and eigenfunctions, is a fundamental task in many machine learning and scientific computing problems. For high-dimensional eigenvalue problems, training neural networks to parameterize the eigenfunctions is considered as a promising alternative to the classical numerical linear algebra techniques. This paper proposes a new optimization framework based on the low-rank approximation characterization of a truncated singular value decomposition, accompanied by new techniques called nesting for learning the top-$L$ singular values and singular functions in the correct order. The proposed method promotes the desired orthogonality in the learned functions implicitly and efficiently via an unconstrained optimization formulation, which is easy to solve with off-the-shelf gradient-based optimization algorithms. We demonstrate the effectiveness of the proposed optimization framework for use cases in computational physics and machine learning.