 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Can Frontier LLMs Pass a Standardized Office Proficiency Exam?
Jun 09, 2026The deployment of Large Language Model (LLM) agents for computer automation is accelerating, yet their ability to navigate complex, professional-grade productivity software is largely untested. We argue that Office automation is an ideal environment for benchmarking document-automation capability, as it requires long-horizon planning and reasoning, precise parameter configuration, and multi-application integration. To quantify this capability, we introduce an evaluation based on China's National Computer Rank Examination (NCRE), featuring 200 comprehensive practical-operation tasks across Word, Excel, and PowerPoint. Each task is scored on a 100-point rubric scale using 7,118 machine-gradable criteria, and Score Rate (SR) denotes the mean percentage of rubric points earned across these tasks. We benchmark 7 frontier LLMs and observe stark limitations: single-turn models score a maximum of 36.6%. A stronger agentic system with execution feedback, iterative repair, and broader Office automation access reaches 68.8%, but remains below the 95.5% community-reference score used as a scoring sanity check. Ultimately, our experiments demonstrate that despite recent advancements in code generation, achieving reliable fine-grained Office document automation remains a significant challenge for current code-generating LLM and agent systems.
Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
Jun 04, 2026AI agents rely on a harness of skills, tools, and workflows to solve complex problems. Continually improving this harness is essential for adapting to new tasks. However, existing optimization methods typically require ground-truth validation sets, yet such labeled data is difficult to acquire in practical deployment settings. To address this problem, we introduce Retrospective Harness Optimization (RHO), a self-supervised method that optimizes the agent harness using only past trajectories. Specifically, RHO selects a diverse coreset of challenging tasks from past trajectories and re-solves them in parallel. The agent analyzes these rollouts using self-validation and self-consistency, then generates candidate harness updates and selects the most effective one by its own pairwise self-preference. We evaluate RHO across three diverse domains, spanning software engineering, technical work, and knowledge work. Notably, a single optimization round improves the pass rate on SWE-Bench Pro from 59% to 78% without any external grading. Furthermore, our analysis demonstrates that RHO effectively targets prior failure modes. As a result, the optimized harness alters the agent's behavior patterns and sustains higher accuracy during long-horizon sessions.
M$^\star$: Every Task Deserves Its Own Memory Harness
Apr 10, 2026Large language model agents rely on specialized memory systems to accumulate and reuse knowledge during extended interactions. Recent architectures typically adopt a fixed memory design tailored to specific domains, such as semantic retrieval for conversations or skills reused for coding. However, a memory system optimized for one purpose frequently fails to transfer to others. To address this limitation, we introduce M$^\star$, a method that automatically discovers task-optimized memory harnesses through executable program evolution. Specifically, M$^\star$ models an agent memory system as a memory program written in Python. This program encapsulates the data Schema, the storage Logic, and the agent workflow Instructions. We optimize these components jointly using a reflective code evolution method; this approach employs a population-based search strategy and analyzes evaluation failures to iteratively refine the candidate programs. We evaluate M$^\star$ on four distinct benchmarks spanning conversation, embodied planning, and expert reasoning. Our results demonstrate that M$^\star$ improves performance over existing fixed-memory baselines robustly across all evaluated tasks. Furthermore, the evolved memory programs exhibit structurally distinct processing mechanisms for each domain. This finding indicates that specializing the memory mechanism for a given task explores a broad design space and provides a superior solution compared to general-purpose memory paradigms.
Distilling Knowledge from Pre-trained Language Models via Text Smoothing
May 08, 2020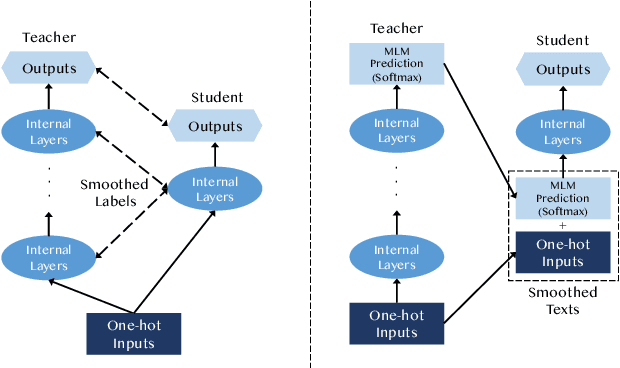
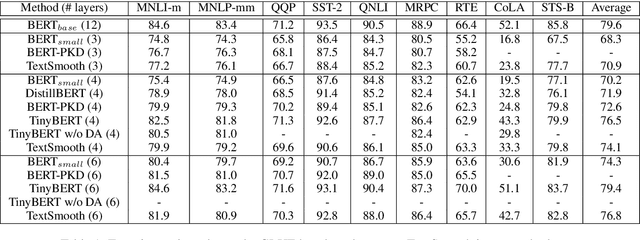
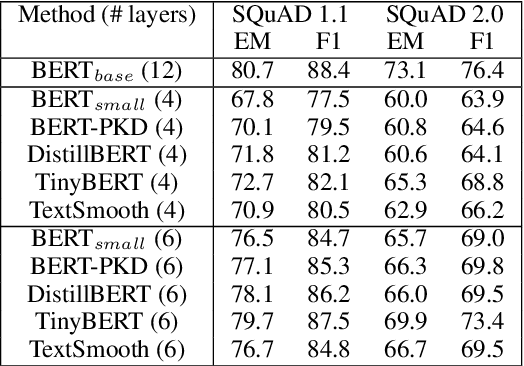

This paper studies compressing pre-trained language models, like BERT (Devlin et al.,2019), via teacher-student knowledge distillation. Previous works usually force the student model to strictly mimic the smoothed labels predicted by the teacher BERT. As an alternative, we propose a new method for BERT distillation, i.e., asking the teacher to generate smoothed word ids, rather than labels, for teaching the student model in knowledge distillation. We call this kind of methodTextSmoothing. Practically, we use the softmax prediction of the Masked Language Model(MLM) in BERT to generate word distributions for given texts and smooth those input texts using that predicted soft word ids. We assume that both the smoothed labels and the smoothed texts can implicitly augment the input corpus, while text smoothing is intuitively more efficient since it can generate more instances in one neural network forward step.Experimental results on GLUE and SQuAD demonstrate that our solution can achieve competitive results compared with existing BERT distillation methods.
How to Evaluate the Next System: Automatic Dialogue Evaluation from the Perspective of Continual Learning
Dec 10, 2019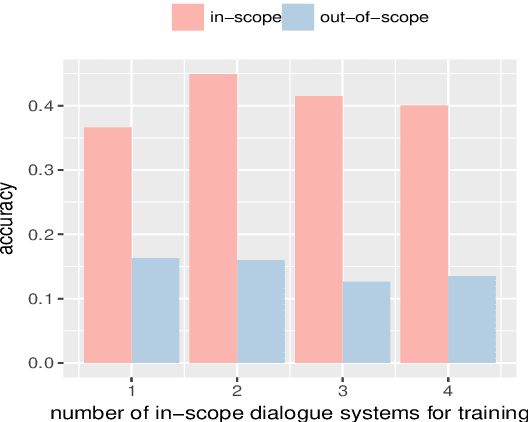
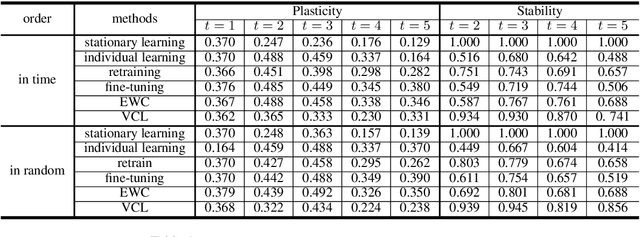
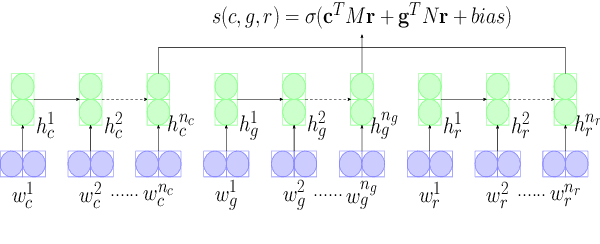
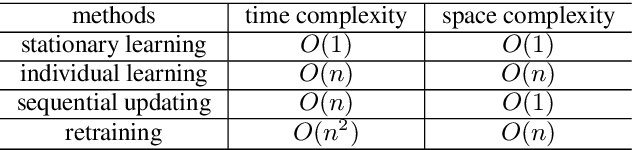
Automatic dialogue evaluation plays a crucial role in open-domain dialogue research. Previous works train neural networks with limited annotation for conducting automatic dialogue evaluation, which would naturally affect the evaluation fairness as dialogue systems close to the scope of training corpus would have more preference than the other ones. In this paper, we study alleviating this problem from the perspective of continual learning: given an existing neural dialogue evaluator and the next system to be evaluated, we fine-tune the learned neural evaluator by selectively forgetting/updating its parameters, to jointly fit dialogue systems have been and will be evaluated. Our motivation is to seek for a lifelong and low-cost automatic evaluation for dialogue systems, rather than to reconstruct the evaluator over and over again. Experimental results show that our continual evaluator achieves comparable performance with reconstructing new evaluators, while requires significantly lower resources.
Proactive Human-Machine Conversation with Explicit Conversation Goals
Jun 13, 2019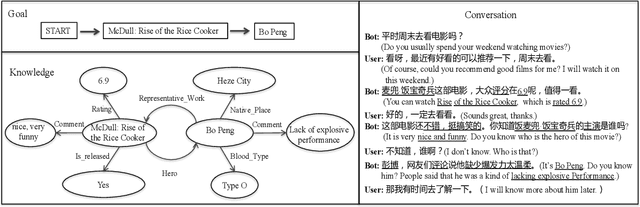
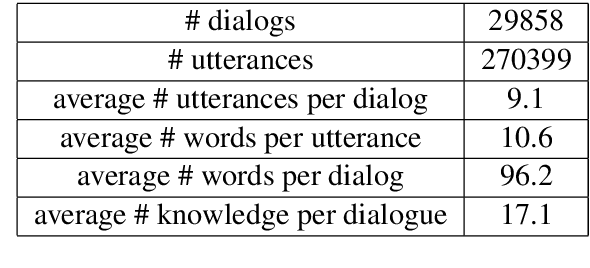
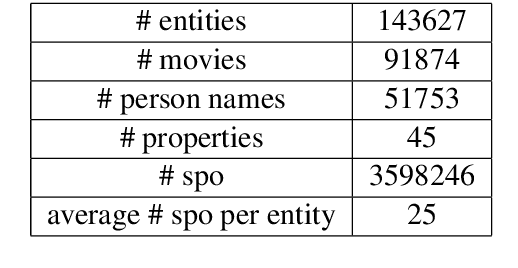
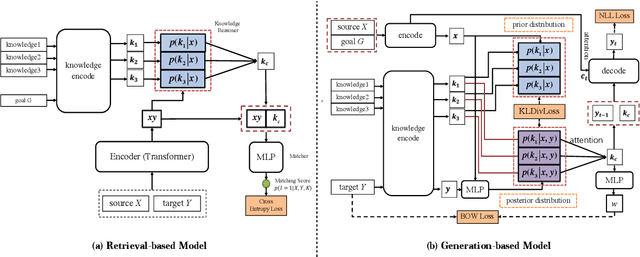
Though great progress has been made for human-machine conversation, current dialogue system is still in its infancy: it usually converses passively and utters words more as a matter of response, rather than on its own initiatives. In this paper, we take a radical step towards building a human-like conversational agent: endowing it with the ability of proactively leading the conversation (introducing a new topic or maintaining the current topic). To facilitate the development of such conversation systems, we create a new dataset named DuConv where one acts as a conversation leader and the other acts as the follower. The leader is provided with a knowledge graph and asked to sequentially change the discussion topics, following the given conversation goal, and meanwhile keep the dialogue as natural and engaging as possible. DuConv enables a very challenging task as the model needs to both understand dialogue and plan over the given knowledge graph. We establish baseline results on this dataset (about 270K utterances and 30k dialogues) using several state-of-the-art models. Experimental results show that dialogue models that plan over the knowledge graph can make full use of related knowledge to generate more diverse multi-turn conversations. The baseline systems along with the dataset are publicly available
Power-Law Graph Cuts
Nov 25, 2014
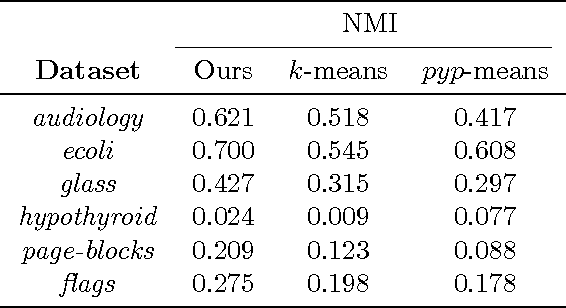

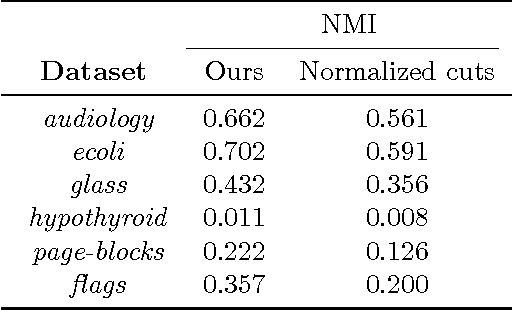
Algorithms based on spectral graph cut objectives such as normalized cuts, ratio cuts and ratio association have become popular in recent years because they are widely applicable and simple to implement via standard eigenvector computations. Despite strong performance for a number of clustering tasks, spectral graph cut algorithms still suffer from several limitations: first, they require the number of clusters to be known in advance, but this information is often unknown a priori; second, they tend to produce clusters with uniform sizes. In some cases, the true clusters exhibit a known size distribution; in image segmentation, for instance, human-segmented images tend to yield segment sizes that follow a power-law distribution. In this paper, we propose a general framework of power-law graph cut algorithms that produce clusters whose sizes are power-law distributed, and also does not fix the number of clusters upfront. To achieve our goals, we treat the Pitman-Yor exchangeable partition probability function (EPPF) as a regularizer to graph cut objectives. Because the resulting objectives cannot be solved by relaxing via eigenvectors, we derive a simple iterative algorithm to locally optimize the objectives. Moreover, we show that our proposed algorithm can be viewed as performing MAP inference on a particular Pitman-Yor mixture model. Our experiments on various data sets show the effectiveness of our algorithms.