 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Knowledge from Pre-trained Language Models via Text Smoothing
Paper and Code
May 08, 2020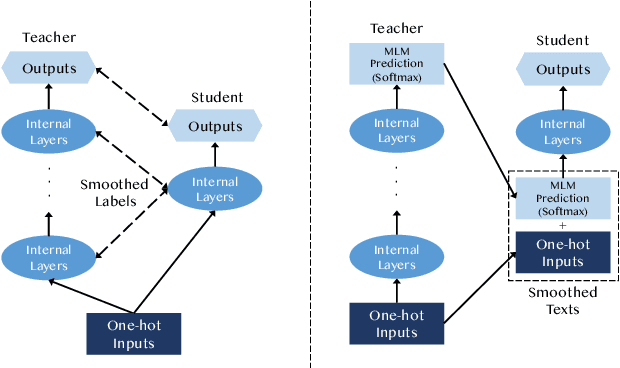
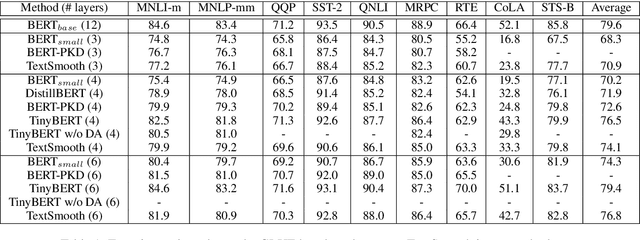
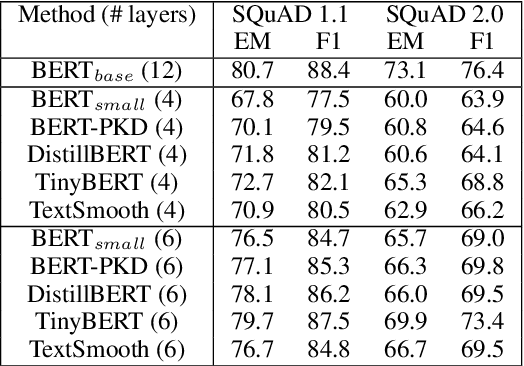

This paper studies compressing pre-trained language models, like BERT (Devlin et al.,2019), via teacher-student knowledge distillation. Previous works usually force the student model to strictly mimic the smoothed labels predicted by the teacher BERT. As an alternative, we propose a new method for BERT distillation, i.e., asking the teacher to generate smoothed word ids, rather than labels, for teaching the student model in knowledge distillation. We call this kind of methodTextSmoothing. Practically, we use the softmax prediction of the Masked Language Model(MLM) in BERT to generate word distributions for given texts and smooth those input texts using that predicted soft word ids. We assume that both the smoothed labels and the smoothed texts can implicitly augment the input corpus, while text smoothing is intuitively more efficient since it can generate more instances in one neural network forward step.Experimental results on GLUE and SQuAD demonstrate that our solution can achieve competitive results compared with existing BERT distillation methods.