 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified End-to-End Retriever-Reader Framework for Knowledge-based VQA
Paper and Code
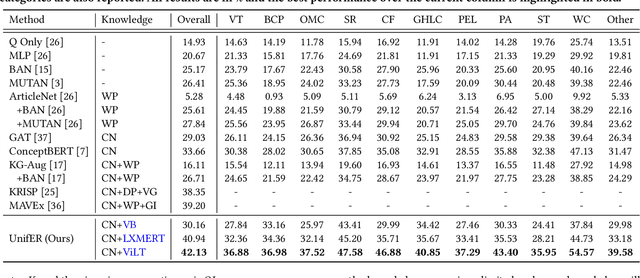
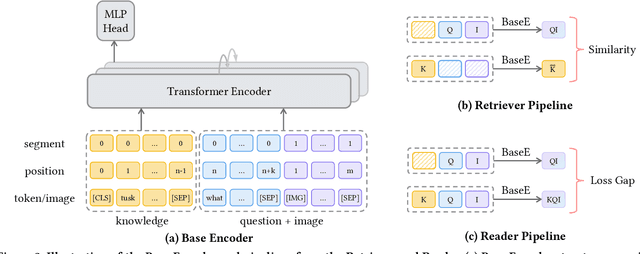
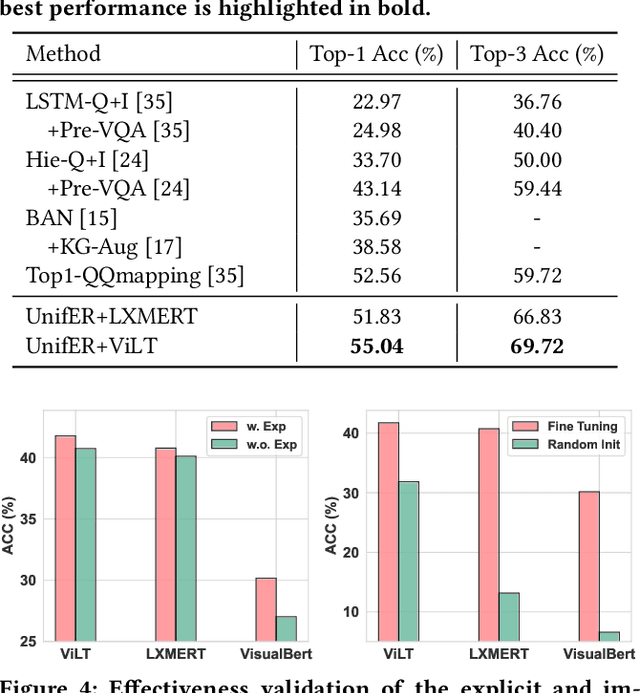
Knowledge-based Visual Question Answering (VQA) expects models to rely on external knowledge for robust answer prediction. Though significant it is, this paper discovers several leading factors impeding the advancement of current state-of-the-art methods. On the one hand, methods which exploit the explicit knowledge take the knowledge as a complement for the coarsely trained VQA model. Despite their effectiveness, these approaches often suffer from noise incorporation and error propagation. On the other hand, pertaining to the implicit knowledge, the multi-modal implicit knowledge for knowledge-based VQA still remains largely unexplored. This work presents a unified end-to-end retriever-reader framework towards knowledge-based VQA. In particular, we shed light on the multi-modal implicit knowledge from vision-language pre-training models to mine its potential in knowledge reasoning. As for the noise problem encountered by the retrieval operation on explicit knowledge, we design a novel scheme to create pseudo labels for effective knowledge supervision. This scheme is able to not only provide guidance for knowledge retrieval, but also drop these instances potentially error-prone towards question answering. To validate the effectiveness of the proposed method, we conduct extensive experiments on the benchmark dataset. The experimental results reveal that our method outperforms existing baselines by a noticeable margin. Beyond the reported numbers, this paper further spawns several insights on knowledge utilization for future research with some empirical findings.