 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterInject: Indirect Prompt Injection Against LLM Agents via Feedback-Guided Iterative Optimization
May 23, 2026LLM-based agents are increasingly deployed for complex tasks requiring planning, tool use, and interaction with external services. Their reliance on untrusted external content exposes them to indirect prompt injection (IPI), in which adversarial instructions embedded in retrieved data hijack agent behavior. Existing attacks rely on static payloads that cannot adapt to agent-specific defenses; even recent adaptive methods lack structured feedback to guide optimization. We introduce \oursys, a feedback-guided iterative framework that closes the loop between injection, diagnosis, and refinement: a rule-based diagnoser produces structured outcome labels with behavioral descriptions, and an LLM-based optimizer refines payloads conditioned on the full optimization history. A synthesis step generates new disguise seeds from failure patterns, enabling the strategy space to self-evolve. On AgentDojo and InjectAgent, \oursys substantially outperforms static baselines and existing adaptive methods across four victim models. Extension experiments on Claude Code, a production-grade coding agent with layered defenses, show that optimized payloads achieve full success on 5 of 9 targets; even those that resist full exploitation exhibit measurable improvement from iterative refinement. We further present a mechanistic analysis of IPI, identifying an attention-mediated threshold mechanism in mid-to-late layers; three causal interventions validate this finding and point to concrete defense directions.
OS-SPEAR: A Toolkit for the Safety, Performance,Efficiency, and Robustness Analysis of OS Agents
Apr 27, 2026The evolution of Multimodal Large Language Models (MLLMs) has shifted the focus from text generation to active behavioral execution, particularly via OS agents navigating complex GUIs. However, the transition of these agents into trustworthy daily partners is hindered by a lack of rigorous evaluation regarding safety, efficiency, and multi-modal robustness. Current benchmarks suffer from narrow safety scenarios, noisy trajectory labeling, and limited robustness metrics. To bridge this gap, we propose OS-SPEAR, a comprehensive toolkit for the systematic analysis of OS agents across four dimensions: Safety, Performance, Efficiency, and Robustness. OS-SPEAR introduces four specialized subsets: (1) a S(afety)-subset encompassing diverse environment- and human-induced hazards; (2) a P(erformance)-subset curated via trajectory value estimation and stratified sampling; (3) an E(fficiency)-subset quantifying performance through the dual lenses of temporal latency and token consumption; and (4) a R(obustness)-subset that applies cross-modal disturbances to both visual and textual inputs. Additionally, we provide an automated analysis tool to generate human-readable diagnostic reports. We conduct an extensive evaluation of 22 popular OS agents using OS-SPEAR. Our empirical results reveal critical insights into the current landscape: notably, a prevalent trade-off between efficiency and safety or robustness, the performance superiority of specialized agents over general-purpose models, and varying robustness vulnerabilities across different modalities. By providing a multidimensional ranking and a standardized evaluation framework, OS-SPEAR offers a foundational resource for developing the next generation of reliable and efficient OS agents. The dataset and codes are available at https://github.com/Wuzheng02/OS-SPEAR.
SAKED: Mitigating Hallucination in Large Vision-Language Models via Stability-Aware Knowledge Enhanced Decoding
Feb 10, 2026Hallucinations in Large Vision-Language Models (LVLMs) pose significant security and reliability risks in real-world applications. Inspired by the observation that humans are more error-prone when uncertain or hesitant, we investigate how instability in a model 's internal knowledge contributes to LVLM hallucinations. We conduct extensive empirical analyses from three perspectives, namely attention heads, model layers, and decoding tokens, and identify three key hallucination patterns: (i) visual activation drift across attention heads, (ii) pronounced knowledge fluctuations across layers, and (iii) visual focus distraction between neighboring output tokens. Building on these findings, we propose Stability-Aware Knowledge-Enhanced Decoding (SAKED), which introduces a layer-wise Knowledge Stability Score (KSS) to quantify knowledge stability throughout the model. By contrasting the most stability-aware and stability-agnostic layers, SAKED suppresses decoding noise and dynamically leverages the most reliable internal knowledge for faithful token generation. Moreover, SAKED is training-free and can be seamlessly integrated into different architectures. Extensive experiments demonstrate that SAKED achieves state-of-the-art performance for hallucination mitigation on various models, tasks, and benchmarks.
Propose and Rectify: A Forensics-Driven MLLM Framework for Image Manipulation Localization
Aug 25, 2025The increasing sophistication of image manipulation techniques demands robust forensic solutions that can both reliably detect alterations and precisely localize tampered regions. Recent Multimodal Large Language Models (MLLMs) show promise by leveraging world knowledge and semantic understanding for context-aware detection, yet they struggle with perceiving subtle, low-level forensic artifacts crucial for accurate manipulation localization. This paper presents a novel Propose-Rectify framework that effectively bridges semantic reasoning with forensic-specific analysis. In the proposal stage, our approach utilizes a forensic-adapted LLaVA model to generate initial manipulation analysis and preliminary localization of suspicious regions based on semantic understanding and contextual reasoning. In the rectification stage, we introduce a Forensics Rectification Module that systematically validates and refines these initial proposals through multi-scale forensic feature analysis, integrating technical evidence from several specialized filters. Additionally, we present an Enhanced Segmentation Module that incorporates critical forensic cues into SAM's encoded image embeddings, thereby overcoming inherent semantic biases to achieve precise delineation of manipulated regions. By synergistically combining advanced multimodal reasoning with established forensic methodologies, our framework ensures that initial semantic proposals are systematically validated and enhanced through concrete technical evidence, resulting in comprehensive detection accuracy and localization precision. Extensive experimental validation demonstrates state-of-the-art performance across diverse datasets with exceptional robustness and generalization capabilities.
FGS-Audio: Fixed-Decoder Framework for Audio Steganography with Adversarial Perturbation Generation
May 28, 2025



The rapid development of Artificial Intelligence Generated Content (AIGC) has made high-fidelity generated audio widely available across the Internet, offering an abundant and versatile source of cover signals for covert communication. Driven by advances in deep learning, current audio steganography frameworks are mainly based on encoding-decoding network architectures. While these methods greatly improve the security of audio steganography, they typically employ elaborate training workflows and rely on extensive pre-trained models. To address the aforementioned issues, this paper pioneers a Fixed-Decoder Framework for Audio Steganography with Adversarial Perturbation Generation (FGS-Audio). The adversarial perturbations that carry secret information are embedded into cover audio to generate stego audio. The receiver only needs to share the structure and weights of the fixed decoding network to accurately extract the secret information from the stego audio, thus eliminating the reliance on large pre-trained models. In FGS-Audio, we propose an audio Adversarial Perturbation Generation (APG) strategy and design a lightweight fixed decoder. The fixed decoder guarantees reliable extraction of the hidden message, while the adversarial perturbations are optimized to keep the stego audio perceptually and statistically close to the cover audio, thereby improving resistance to steganalysis. The experimental results show that the method exhibits excellent anti-steganalysis performance under different relative payloads, outperforming existing SOTA approaches. In terms of stego audio quality, FGS-Audio achieves an average PSNR improvement of over 10 dB compared to SOTA method.
GhostPrompt: Jailbreaking Text-to-image Generative Models based on Dynamic Optimization
May 25, 2025Text-to-image (T2I) generation models can inadvertently produce not-safe-for-work (NSFW) content, prompting the integration of text and image safety filters. Recent advances employ large language models (LLMs) for semantic-level detection, rendering traditional token-level perturbation attacks largely ineffective. However, our evaluation shows that existing jailbreak methods are ineffective against these modern filters. We introduce GhostPrompt, the first automated jailbreak framework that combines dynamic prompt optimization with multimodal feedback. It consists of two key components: (i) Dynamic Optimization, an iterative process that guides a large language model (LLM) using feedback from text safety filters and CLIP similarity scores to generate semantically aligned adversarial prompts; and (ii) Adaptive Safety Indicator Injection, which formulates the injection of benign visual cues as a reinforcement learning problem to bypass image-level filters. GhostPrompt achieves state-of-the-art performance, increasing the ShieldLM-7B bypass rate from 12.5\% (Sneakyprompt) to 99.0\%, improving CLIP score from 0.2637 to 0.2762, and reducing the time cost by $4.2 \times$. Moreover, it generalizes to unseen filters including GPT-4.1 and successfully jailbreaks DALLE 3 to generate NSFW images in our evaluation, revealing systemic vulnerabilities in current multimodal defenses. To support further research on AI safety and red-teaming, we will release code and adversarial prompts under a controlled-access protocol.
Enhancing Zero-Shot Image Recognition in Vision-Language Models through Human-like Concept Guidance
Mar 21, 2025
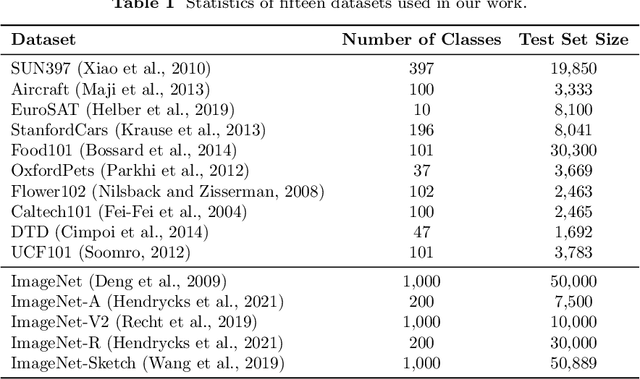


In zero-shot image recognition tasks, humans demonstrate remarkable flexibility in classifying unseen categories by composing known simpler concepts. However, existing vision-language models (VLMs), despite achieving significant progress through large-scale natural language supervision, often underperform in real-world applications because of sub-optimal prompt engineering and the inability to adapt effectively to target classes. To address these issues, we propose a Concept-guided Human-like Bayesian Reasoning (CHBR) framework. Grounded in Bayes' theorem, CHBR models the concept used in human image recognition as latent variables and formulates this task by summing across potential concepts, weighted by a prior distribution and a likelihood function. To tackle the intractable computation over an infinite concept space, we introduce an importance sampling algorithm that iteratively prompts large language models (LLMs) to generate discriminative concepts, emphasizing inter-class differences. We further propose three heuristic approaches involving Average Likelihood, Confidence Likelihood, and Test Time Augmentation (TTA) Likelihood, which dynamically refine the combination of concepts based on the test image. Extensive evaluations across fifteen datasets demonstrate that CHBR consistently outperforms existing state-of-the-art zero-shot generalization methods.
Joint Learning of Deep Texture and High-Frequency Features for Computer-Generated Image Detection
Sep 07, 2022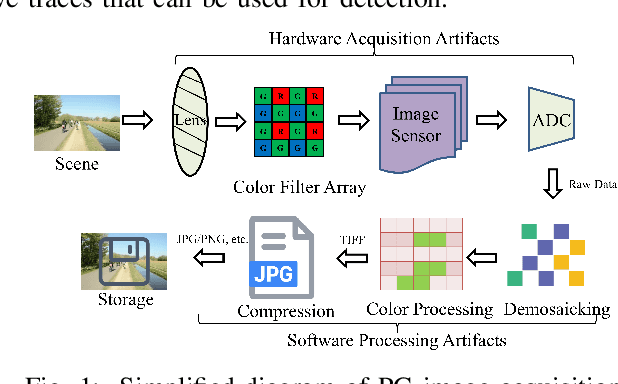

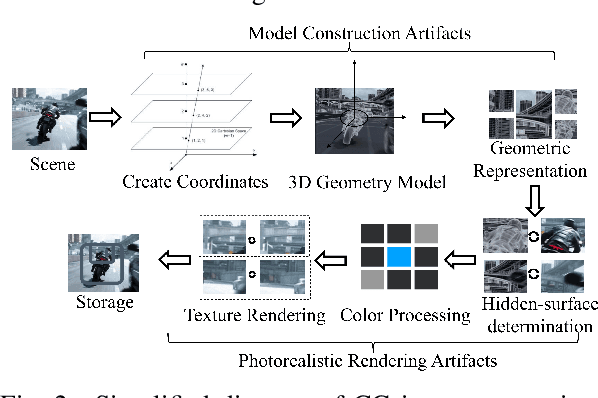
Distinguishing between computer-generated (CG) and natural photographic (PG) images is of great importance to verify the authenticity and originality of digital images. However, the recent cutting-edge generation methods enable high qualities of synthesis in CG images, which makes this challenging task even trickier. To address this issue, a joint learning strategy with deep texture and high-frequency features for CG image detection is proposed. We first formulate and deeply analyze the different acquisition processes of CG and PG images. Based on the finding that multiple different modules in image acquisition will lead to different sensitivity inconsistencies to the convolutional neural network (CNN)-based rendering in images, we propose a deep texture rendering module for texture difference enhancement and discriminative texture representation. Specifically, the semantic segmentation map is generated to guide the affine transformation operation, which is used to recover the texture in different regions of the input image. Then, the combination of the original image and the high-frequency components of the original and rendered images are fed into a multi-branch neural network equipped with attention mechanisms, which refines intermediate features and facilitates trace exploration in spatial and channel dimensions respectively. Extensive experiments on two public datasets and a newly constructed dataset with more realistic and diverse images show that the proposed approach outperforms existing methods in the field by a clear margin. Besides, results also demonstrate the detection robustness and generalization ability of the proposed approach to postprocessing operations and generative adversarial network (GAN) generated images.
Gait Identification under Surveillance Environment based on Human Skeleton
Nov 24, 2021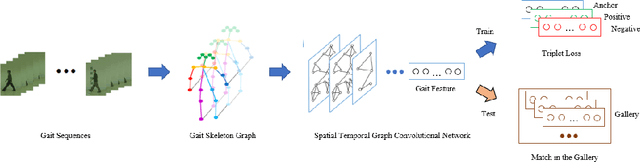
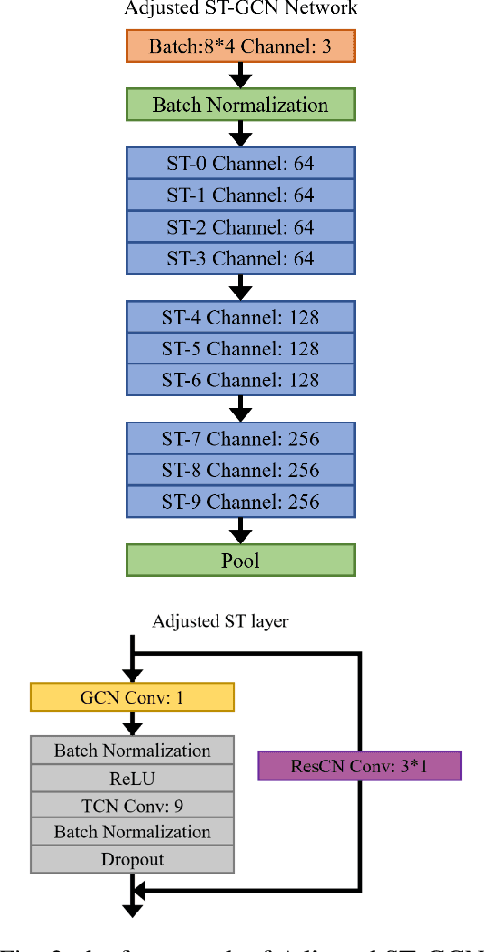
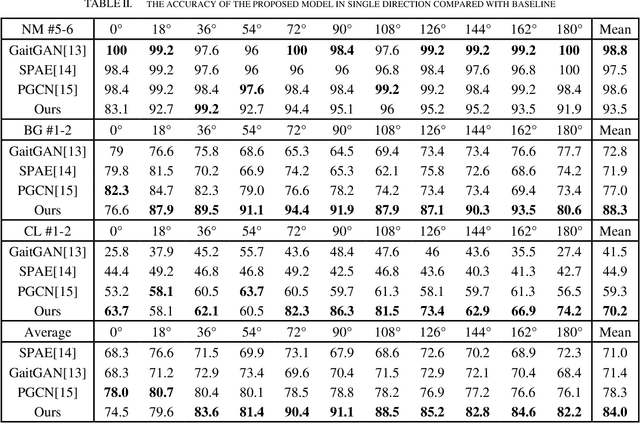
As an emerging biological identification technology, vision-based gait identification is an important research content in biometrics. Most existing gait identification methods extract features from gait videos and identify a probe sample by a query in the gallery. However, video data contains redundant information and can be easily influenced by bagging (BG) and clothing (CL). Since human body skeletons convey essential information about human gaits, a skeleton-based gait identification network is proposed in our project. First, extract skeleton sequences from the video and map them into a gait graph. Then a feature extraction network based on Spatio-Temporal Graph Convolutional Network (ST-GCN) is constructed to learn gait representations. Finally, the probe sample is identified by matching with the most similar piece in the gallery. We tested our method on the CASIA-B dataset. The result shows that our approach is highly adaptive and gets the advanced result in BG, CL conditions, and average.