 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Like a Pilot: Fine-Grained Long-Horizon UAV Navigation
Jun 05, 2026Language-guided UAV agents must execute long-horizon semantic instructions while producing smooth, physically feasible continuous flight commands, yet existing Vision-Language Navigation (VLN) benchmarks typically use discrete or coarse actions and existing UAV Vision-Language-Action (VLA) tasks focus on short, atomic maneuvers. To address this gap in UAV task settings, we introduce \textbf{FLIGHT}, a \textbf{F}ine-grained \textbf{L}ong-horizon \textbf{I}nstruction-\textbf{G}uided benchmark for \textbf{H}ybrid UAV navigation and reasoning \textbf{T}asks, which combines multi-stage instructions with dense 6-DoF trajectory annotations across two dataset splits: Fine-grained VLN and Long-horizon Flow. To endow the UAV agent with the capability of real-time in-flight reasoning over task execution status and mission planning, while simultaneously accommodating high-frequency, real-time precise control, we further propose \textbf{FLIGHT VLA}, an asynchronous architecture that decouples a low-frequency Streaming Pilot Vision-Language Model (VLM) for task-state reasoning from a high-frequency diffusion action model for continuous control, supervised by explicit \textbf{Pilot Reasoning} texts that summarize the current flight state and anticipate the next subgoal. In closed-loop evaluation, FLIGHT VLA consistently surpasses representative VLN and VLA baselines on our FLIGHT benchmarks, achieving stronger multi-stage completion, subgoal adherence, and terminal control. Its trained Streaming Pilot Reasoning VLM further improves UAV video reasoning, validating the effectiveness of our design.
RadioFormer3D: Weakly Supervised 3D Radio Map Estimation in Low-Altitude Airspace via Generative Modeling
May 28, 2026With the emergence of wireless applications in three-dimensional environments, such as the low-altitude airspace and 3D heterogeneous networks, radio map estimation is increasingly required to characterize signal propagation across both horizontal and vertical dimensions. However, extending radio map estimation from 2D to 3D remains challenging due to increased spatial sparsity and limited supervision across continuous altitudes. In this paper, we propose \textbf{\textit{RadioFormer3D}}, a specialized model for volumetric spectrum reconstruction under weak supervision. Building on the dual-stream, multi-granularity fusion architecture of \textit{RadioFormer}, \textit{RadioFormer3D} introduces a Fourier-based sampling encoder and a volumetric decoder to efficiently process sparse measurements in 3D space. To alleviate the lack of vertical supervision, we propose the \textbf{\textit{Joint Spectrum Integrity Loss}}, which integrates volume-level pseudo-label supervision, map-level geometry-aware radio rendering, and pixel-level localized constraints within a unified optimization scheme. This design enables the model to capture complex vertical structural relationships more effectively under sparse supervision. Extensive experiments across several radio map datasets show that \textit{RadioFormer3D} achieves superior overall performance compared to representative existing methods. In particular, it demonstrates improved reconstruction quality at unlabeled altitudes while maintaining a favorable trade-off between accuracy and inference efficiency, positioning it as a highly promising solution for future 3D environment-aware wireless networks.
GTF: Omnidirectional EPI Transformer for Light Field Super-Resolution
May 06, 2026Light field (LF) image super-resolution benefits from Epipolar Plane Images (EPIs), whose line slopes explicitly encode disparity. However, existing Transformer-based LF SR methods mainly attend to horizontal and vertical EPIs, leaving diagonal epipolar geometry underexplored. We present GTF, an omnidirectional EPI Transformer that explicitly models horizontal, vertical, 45-degree, and 135-degree EPIs within a unified reconstruction framework. GTF combines directional EPI processing, MacPI-based prior injection, adaptive directional fusion, and a topology-preserving feed-forward network to better exploit LF geometry. For the NTIRE 2026 fidelity tracks, we use GTF as the main model, while a lightweight GTF-Tiny variant targets the efficiency track. On five standard LF SR benchmarks covering both real-captured and synthetic scenes, GTF reaches 32.78 dB without inference-time enhancement, and stronger inference settings with EPSW and test-time augmentation further improve performance. Under the NTIRE 2026 efficiency constraint, GTF-Tiny attains 32.57 dB with only 0.915M parameters and 19.81 GFLOPs. In the NTIRE 2026 Light Field Image Super-Resolution Challenge, our submissions rank 3rd on Track 1 and Track 3 and 4th on Track 2. Architecture-evolution, channel-width, and inference analyses further support the effectiveness of diagonal EPI modeling, directional fusion, and the lightweight design.
The Second Challenge on Cross-Domain Few-Shot Object Detection at NTIRE 2026: Methods and Results
Apr 13, 2026Cross-domain few-shot object detection (CD-FSOD) remains a challenging problem for existing object detectors and few-shot learning approaches, particularly when generalizing across distinct domains. As part of NTIRE 2026, we hosted the second CD-FSOD Challenge to systematically evaluate and promote progress in detecting objects in unseen target domains under limited annotation conditions. The challenge received strong community interest, with 128 registered participants and a total of 696 submissions. Among them, 31 teams actively participated, and 19 teams submitted valid final results. Participants explored a wide range of strategies, introducing innovative methods that push the performance frontier under both open-source and closed-source tracks. This report presents a detailed overview of the NTIRE 2026 CD-FSOD Challenge, including a summary of the submitted approaches and an analysis of the final results across all participating teams. Challenge Codes: https://github.com/ohMargin/NTIRE2026_CDFSOD.
Dynamic Whole-Body Dancing with Humanoid Robots -- A Model-Based Control Approach
Apr 05, 2026This paper presents an integrated model-based framework for generating and executing dynamic whole-body dance motions on humanoid robots. The framework operates in two stages: offline motion generation and online motion execution, both leveraging future state prediction to enable robust and dynamic dance motions in real-world environments. In the offline motion generation stage, human dance demonstrations are captured via a motion capture (MoCap) system, retargeted to the robot by solving a Quadratic Programming (QP) problem, and further refined using Trajectory Optimization (TO) to ensure dynamic feasibility. In the online motion execution stage, a centroidal dynamics-based Model Predictive Control (MPC) framework tracks the planned motions in real time and proactively adjusts swing foot placement to adapt to real world disturbances. We validate our framework on the full-size humanoid robot Kuavo 4Pro, demonstrating the dynamic dance motions both in simulation and in a four-minute live public performance with a team of four robots. Experimental results show that longer prediction horizons improve both motion expressiveness in planning and stability in execution.
Efficient RGB-D Scene Understanding via Multi-task Adaptive Learning and Cross-dimensional Feature Guidance
Mar 08, 2026Scene understanding plays a critical role in enabling intelligence and autonomy in robotic systems. Traditional approaches often face challenges, including occlusions, ambiguous boundaries, and the inability to adapt attention based on task-specific requirements and sample variations. To address these limitations, this paper presents an efficient RGB-D scene understanding model that performs a range of tasks, including semantic segmentation, instance segmentation, orientation estimation, panoptic segmentation, and scene classification. The proposed model incorporates an enhanced fusion encoder, which effectively leverages redundant information from both RGB and depth inputs. For semantic segmentation, we introduce normalized focus channel layers and a context feature interaction layer, designed to mitigate issues such as shallow feature misguidance and insufficient local-global feature representation. The instance segmentation task benefits from a non-bottleneck 1D structure, which achieves superior contour representation with fewer parameters. Additionally, we propose a multi-task adaptive loss function that dynamically adjusts the learning strategy for different tasks based on scene variations. Extensive experiments on the NYUv2, SUN RGB-D, and Cityscapes datasets demonstrate that our approach outperforms existing methods in both segmentation accuracy and processing speed.
Seeking Necessary and Sufficient Information from Multimodal Medical Data
Feb 27, 2026Learning multimodal representations from medical images and other data sources can provide richer information for decision-making. While various multimodal models have been developed for this, they overlook learning features that are both necessary (must be present for the outcome to occur) and sufficient (enough to determine the outcome). We argue learning such features is crucial as they can improve model performance by capturing essential predictive information, and enhance model robustness to missing modalities as each modality can provide adequate predictive signals. Such features can be learned by leveraging the Probability of Necessity and Sufficiency (PNS) as a learning objective, an approach that has proven effective in unimodal settings. However, extending PNS to multimodal scenarios remains underexplored and is non-trivial as key conditions of PNS estimation are violated. We address this by decomposing multimodal representations into modality-invariant and modality-specific components, then deriving tractable PNS objectives for each. Experiments on synthetic and real-world medical datasets demonstrate our method's effectiveness. Code will be available on GitHub.
LIBERO-X: Robustness Litmus for Vision-Language-Action Models
Feb 06, 2026Reliable benchmarking is critical for advancing Vision-Language-Action (VLA) models, as it reveals their generalization, robustness, and alignment of perception with language-driven manipulation tasks. However, existing benchmarks often provide limited or misleading assessments due to insufficient evaluation protocols that inadequately capture real-world distribution shifts. This work systematically rethinks VLA benchmarking from both evaluation and data perspectives, introducing LIBERO-X, a benchmark featuring: 1) A hierarchical evaluation protocol with progressive difficulty levels targeting three core capabilities: spatial generalization, object recognition, and task instruction understanding. This design enables fine-grained analysis of performance degradation under increasing environmental and task complexity; 2) A high-diversity training dataset collected via human teleoperation, where each scene supports multiple fine-grained manipulation objectives to bridge the train-evaluation distribution gap. Experiments with representative VLA models reveal significant performance drops under cumulative perturbations, exposing persistent limitations in scene comprehension and instruction grounding. By integrating hierarchical evaluation with diverse training data, LIBERO-X offers a more reliable foundation for assessing and advancing VLA development.
TCFormer: A 5M-Parameter Transformer with Density-Guided Aggregation for Weakly-Supervised Crowd Counting
Dec 21, 2025Crowd counting typically relies on labor-intensive point-level annotations and computationally intensive backbones, restricting its scalability and deployment in resource-constrained environments. To address these challenges, this paper proposes the TCFormer, a tiny, ultra-lightweight, weakly-supervised transformer-based crowd counting framework with only 5 million parameters that achieves competitive performance. Firstly, a powerful yet efficient vision transformer is adopted as the feature extractor, the global context-aware capabilities of which provides semantic meaningful crowd features with a minimal memory footprint. Secondly, to compensate for the lack of spatial supervision, we design a feature aggregation mechanism termed the Learnable Density-Weighted Averaging module. This module dynamically re-weights local tokens according to predicted density scores, enabling the network to adaptively modulate regional features based on their specific density characteristics without the need for additional annotations. Furthermore, this paper introduces a density-level classification loss, which discretizes crowd density into distinct grades, thereby regularizing the training process and enhancing the model's classification power across varying levels of crowd density. Therefore, although TCformer is trained under a weakly-supervised paradigm utilizing only image-level global counts, the joint optimization of count and density-level losses enables the framework to achieve high estimation accuracy. Extensive experiments on four benchmarks including ShanghaiTech A/B, UCF-QNRF, and NWPU datasets demonstrate that our approach strikes a superior trade-off between parameter efficiency and counting accuracy and can be a good solution for crowd counting tasks in edge devices.
Frustratingly Easy Task-aware Pruning for Large Language Models
Oct 26, 2025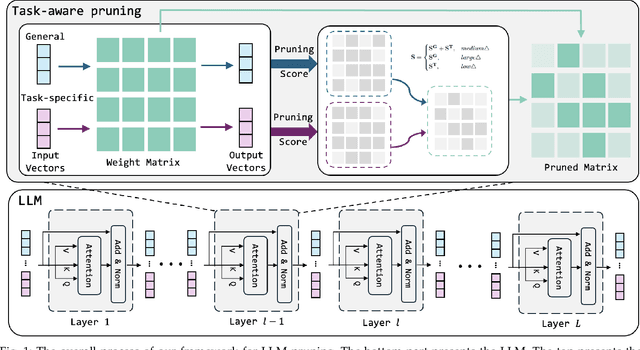
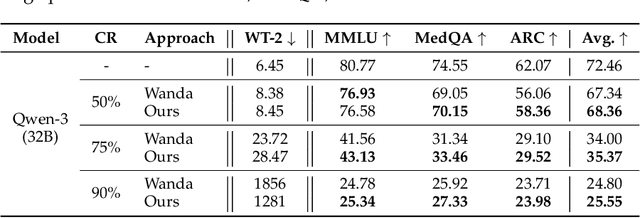
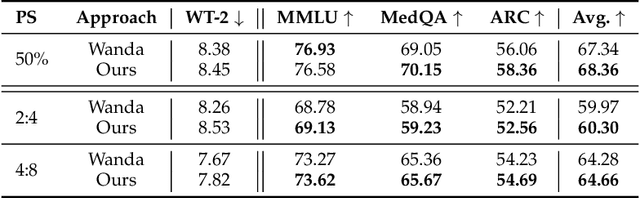
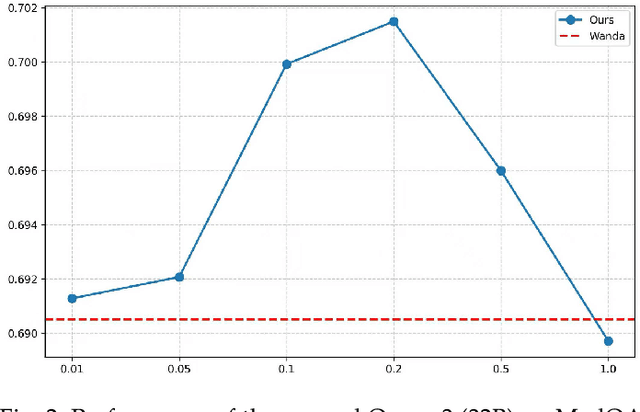
Pruning provides a practical solution to reduce the resources required to run large language models (LLMs) to benefit from their effective capabilities as well as control their cost for training and inference. Research on LLM pruning often ranks the importance of LLM parameters using their magnitudes and calibration-data activations and removes (or masks) the less important ones, accordingly reducing LLMs' size. However, these approaches primarily focus on preserving the LLM's ability to generate fluent sentences, while neglecting performance on specific domains and tasks. In this paper, we propose a simple yet effective pruning approach for LLMs that preserves task-specific capabilities while shrinking their parameter space. We first analyze how conventional pruning minimizes loss perturbation under general-domain calibration and extend this formulation by incorporating task-specific feature distributions into the importance computation of existing pruning algorithms. Thus, our framework computes separate importance scores using both general and task-specific calibration data, partitions parameters into shared and exclusive groups based on activation-norm differences, and then fuses their scores to guide the pruning process. This design enables our method to integrate seamlessly with various foundation pruning techniques and preserve the LLM's specialized abilities under compression. Experiments on widely used benchmarks demonstrate that our approach is effective and consistently outperforms the baselines with identical pruning ratios and different settings.