 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWLR: Text-Guided Weakly-Supervised Lesion Localization and Severity Regression for Explainable Diabetic Retinopathy Grading
Dec 15, 2025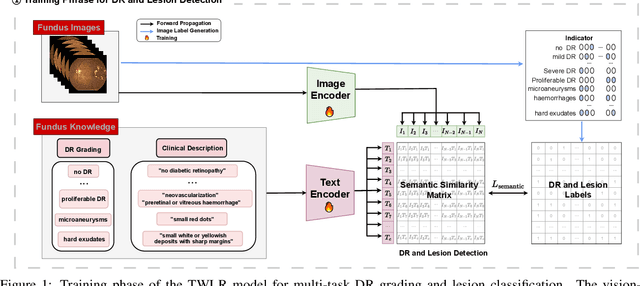

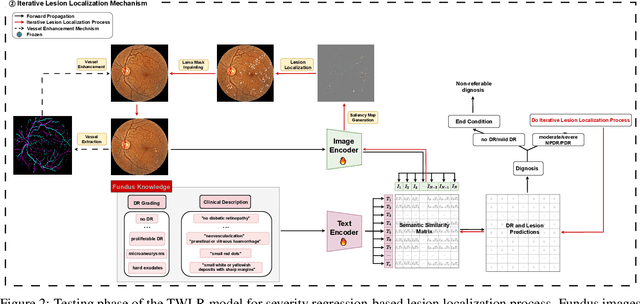
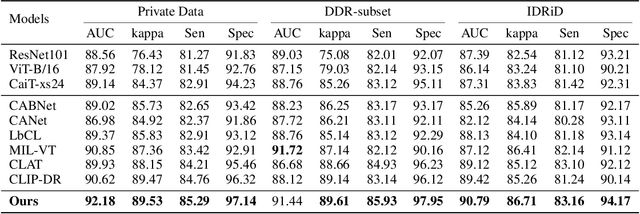
Accurate medical image analysis can greatly assist clinical diagnosis, but its effectiveness relies on high-quality expert annotations Obtaining pixel-level labels for medical images, particularly fundus images, remains costly and time-consuming. Meanwhile, despite the success of deep learning in medical imaging, the lack of interpretability limits its clinical adoption. To address these challenges, we propose TWLR, a two-stage framework for interpretable diabetic retinopathy (DR) assessment. In the first stage, a vision-language model integrates domain-specific ophthalmological knowledge into text embeddings to jointly perform DR grading and lesion classification, effectively linking semantic medical concepts with visual features. The second stage introduces an iterative severity regression framework based on weakly-supervised semantic segmentation. Lesion saliency maps generated through iterative refinement direct a progressive inpainting mechanism that systematically eliminates pathological features, effectively downgrading disease severity toward healthier fundus appearances. Critically, this severity regression approach achieves dual benefits: accurate lesion localization without pixel-level supervision and providing an interpretable visualization of disease-to-healthy transformations. Experimental results on the FGADR, DDR, and a private dataset demonstrate that TWLR achieves competitive performance in both DR classification and lesion segmentation, offering a more explainable and annotation-efficient solution for automated retinal image analysis.
Knowledge Distillation with Adapted Weight
Jan 06, 2025Although large models have shown a strong capacity to solve large-scale problems in many areas including natural language and computer vision, their voluminous parameters are hard to deploy in a real-time system due to computational and energy constraints. Addressing this, knowledge distillation through Teacher-Student architecture offers a sustainable pathway to compress the knowledge of large models into more manageable sizes without significantly compromising performance. To enhance the robustness and interpretability of this framework, it is critical to understand how individual training data impact model performance, which is an area that remains underexplored. We propose the \textbf{Knowledge Distillation with Adaptive Influence Weight (KD-AIF)} framework which leverages influence functions from robust statistics to assign weights to training data, grounded in the four key SAFE principles: Sustainability, Accuracy, Fairness, and Explainability. This novel approach not only optimizes distillation but also increases transparency by revealing the significance of different data. The exploration of various update mechanisms within the KD-AIF framework further elucidates its potential to significantly improve learning efficiency and generalization in student models, marking a step toward more explainable and deployable Large Models. KD-AIF is effective in knowledge distillation while also showing exceptional performance in semi-supervised learning with outperforms existing baselines and methods in multiple benchmarks (CIFAR-100, CIFAR-10-4k, SVHN-1k, and GLUE).
NeutraSum: A Language Model can help a Balanced Media Diet by Neutralizing News Summaries
Jan 02, 2025



Media bias in news articles arises from the political polarisation of media outlets, which can reinforce societal stereotypes and beliefs. Reporting on the same event often varies significantly between outlets, reflecting their political leanings through polarised language and focus. Although previous studies have attempted to generate bias-free summaries from multiperspective news articles, they have not effectively addressed the challenge of mitigating inherent media bias. To address this gap, we propose \textbf{NeutraSum}, a novel framework that integrates two neutrality losses to adjust the semantic space of generated summaries, thus minimising media bias. These losses, designed to balance the semantic distances across polarised inputs and ensure alignment with expert-written summaries, guide the generation of neutral and factually rich summaries. To evaluate media bias, we employ the political compass test, which maps political leanings based on economic and social dimensions. Experimental results on the Allsides dataset demonstrate that NeutraSum not only improves summarisation performance but also achieves significant reductions in media bias, offering a promising approach for neutral news summarisation.
Analysis and classification of main risk factors causing stroke in Shanxi Province
May 29, 2021
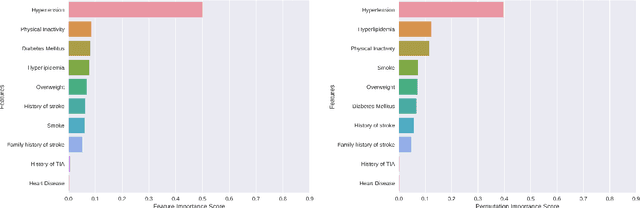
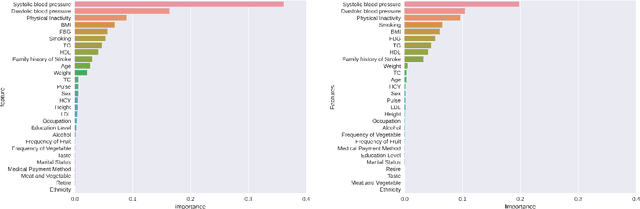
In China, stroke is the first leading cause of death in recent years. It is a major cause of long-term physical and cognitive impairment, which bring great pressure on the National Public Health System. Evaluation of the risk of getting stroke is important for the prevention and treatment of stroke in China. A data set with 2000 hospitalized stroke patients in 2018 and 27583 residents during the year 2017 to 2020 is analyzed in this study. Due to data incompleteness, inconsistency, and non-structured formats, missing values in the raw data are filled with -1 as an abnormal class. With the cleaned features, three models on risk levels of getting stroke are built by using machine learning methods. The importance of "8+2" factors from China National Stroke Prevention Project (CSPP) is evaluated via decision tree and random forest models. Except for "8+2" factors the importance of features and SHAP1 values for lifestyle information, demographic information, and medical measurement are evaluated and ranked via a random forest model. Furthermore, a logistic regression model is applied to evaluate the probability of getting stroke for different risk levels. Based on the census data in both communities and hospitals from Shanxi Province, we investigate different risk factors of getting stroke and their ranking with interpretable machine learning models. The results show that Hypertension (Systolic blood pressure, Diastolic blood pressure), Physical Inactivity (Lack of sports), and Overweight (BMI) are ranked as the top three high-risk factors of getting stroke in Shanxi province. The probability of getting stroke for a person can also be predicted via our machine learning model.