 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Connection Based on Channel Attention for Differentiable Neural Architecture Search
Paper and Code
Aug 01, 2022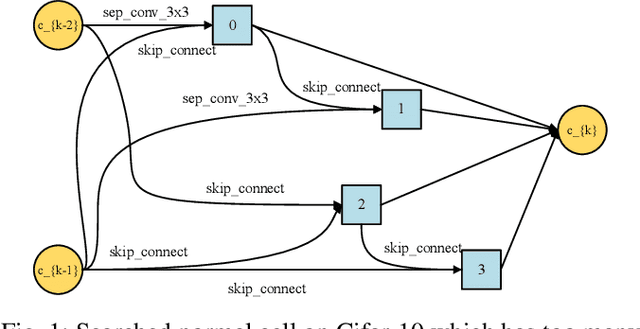
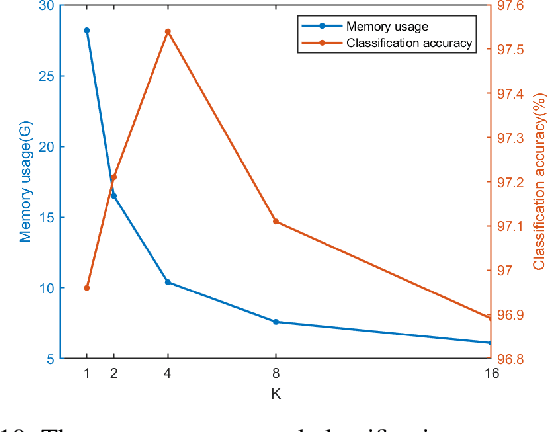
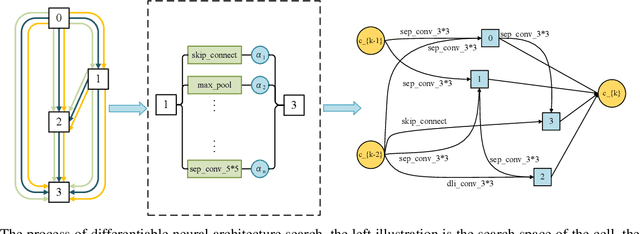
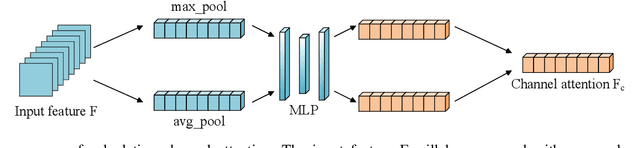
Differentiable neural architecture search (DARTS), as a gradient-guided search method, greatly reduces the cost of computation and speeds up the search. In DARTS, the architecture parameters are introduced to the candidate operations, but the parameters of some weight-equipped operations may not be trained well in the initial stage, which causes unfair competition between candidate operations. The weight-free operations appear in large numbers which results in the phenomenon of performance crash. Besides, a lot of memory will be occupied during training supernet which causes the memory utilization to be low. In this paper, a partial channel connection based on channel attention for differentiable neural architecture search (ADARTS) is proposed. Some channels with higher weights are selected through the attention mechanism and sent into the operation space while the other channels are directly contacted with the processed channels. Selecting a few channels with higher attention weights can better transmit important feature information into the search space and greatly improve search efficiency and memory utilization. The instability of network structure caused by random selection can also be avoided. The experimental results show that ADARTS achieved 2.46% and 17.06% classification error rates on CIFAR-10 and CIFAR-100, respectively. ADARTS can effectively solve the problem that too many skip connections appear in the search process and obtain network structures with better performance.