 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMap: A General Mapping Framework Integrating Optics, Geometry, and Semantics
Sep 09, 2025Robotic systems demand accurate and comprehensive 3D environment perception, requiring simultaneous capture of photo-realistic appearance (optical), precise layout shape (geometric), and open-vocabulary scene understanding (semantic). Existing methods typically achieve only partial fulfillment of these requirements while exhibiting optical blurring, geometric irregularities, and semantic ambiguities. To address these challenges, we propose OmniMap. Overall, OmniMap represents the first online mapping framework that simultaneously captures optical, geometric, and semantic scene attributes while maintaining real-time performance and model compactness. At the architectural level, OmniMap employs a tightly coupled 3DGS-Voxel hybrid representation that combines fine-grained modeling with structural stability. At the implementation level, OmniMap identifies key challenges across different modalities and introduces several innovations: adaptive camera modeling for motion blur and exposure compensation, hybrid incremental representation with normal constraints, and probabilistic fusion for robust instance-level understanding. Extensive experiments show OmniMap's superior performance in rendering fidelity, geometric accuracy, and zero-shot semantic segmentation compared to state-of-the-art methods across diverse scenes. The framework's versatility is further evidenced through a variety of downstream applications, including multi-domain scene Q&A, interactive editing, perception-guided manipulation, and map-assisted navigation.
Path Planning on Multi-level Point Cloud with a Weighted Traversability Graph
Apr 30, 2025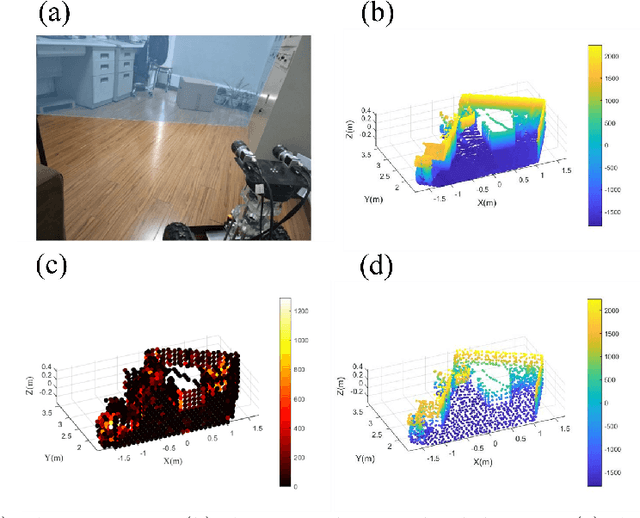

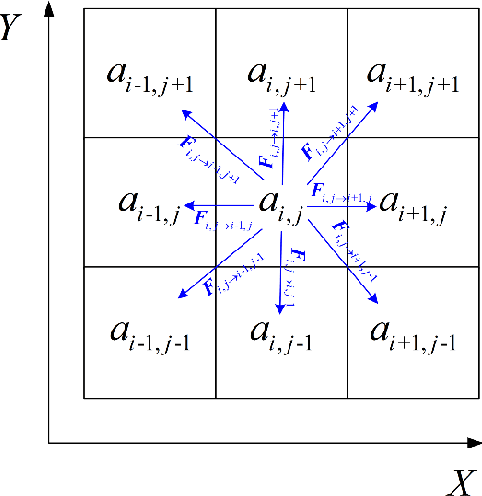
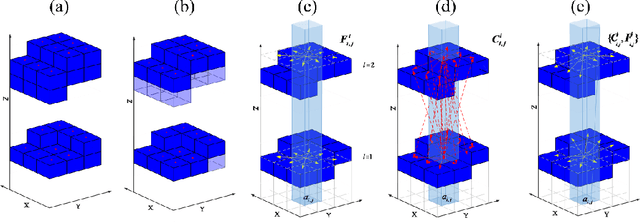
This article proposes a new path planning method for addressing multi-level terrain situations. The proposed method includes innovations in three aspects: 1) the pre-processing of point cloud maps with a multi-level skip-list structure and data-slimming algorithm for well-organized and simplified map formalization and management, 2) the direct acquisition of local traversability indexes through vehicle and point cloud interaction analysis, which saves work in surface fitting, and 3) the assignment of traversability indexes on a multi-level connectivity graph to generate a weighted traversability graph for generally search-based path planning. The A* algorithm is modified to utilize the traversability graph to generate a short and safe path. The effectiveness and reliability of the proposed method are verified through indoor and outdoor experiments conducted in various environments, including multi-floor buildings, woodland, and rugged mountainous regions. The results demonstrate that the proposed method can properly address 3D path planning problems for ground vehicles in a wide range of situations.
OpenIN: Open-Vocabulary Instance-Oriented Navigation in Dynamic Domestic Environments
Jan 08, 2025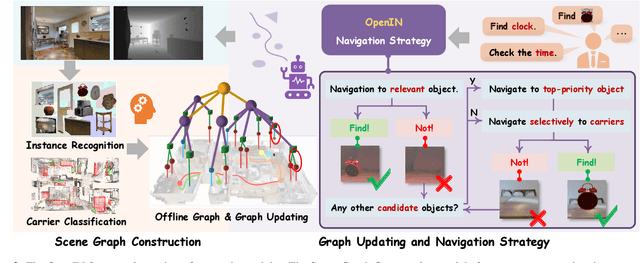
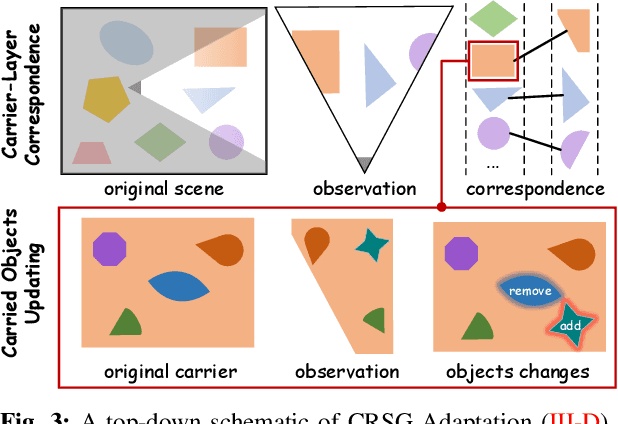
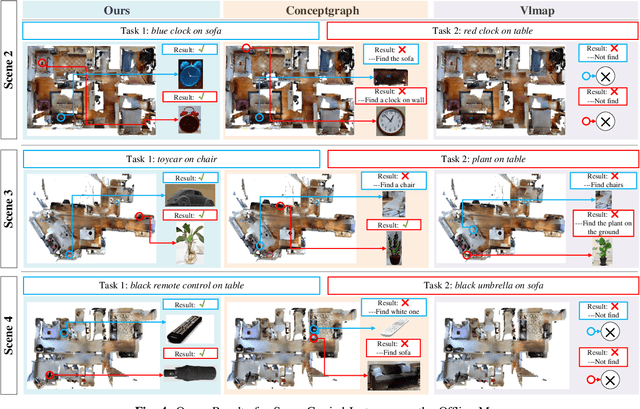
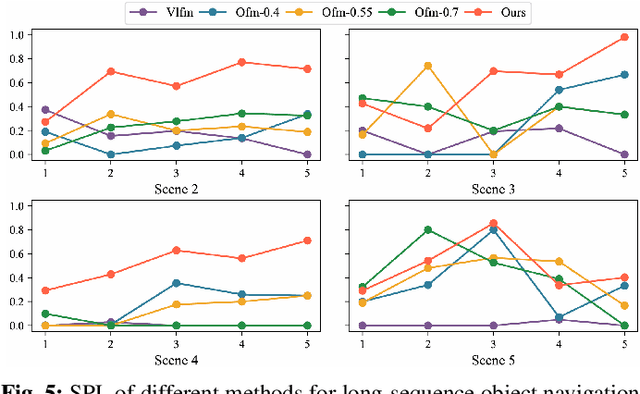
In daily domestic settings, frequently used objects like cups often have unfixed positions and multiple instances within the same category, and their carriers frequently change as well. As a result, it becomes challenging for a robot to efficiently navigate to a specific instance. To tackle this challenge, the robot must capture and update scene changes and plans continuously. However, current object navigation approaches primarily focus on the semantic level and lack the ability to dynamically update scene representation. In contrast, this paper captures the relationships between frequently used objects and their static carriers. It constructs an open-vocabulary Carrier-Relationship Scene Graph (CRSG) and updates the carrying status during robot navigation to reflect the dynamic changes of the scene. Based on the CRSG, we further propose an instance navigation strategy that models the navigation process as a Markov Decision Process. At each step, decisions are informed by the Large Language Model's commonsense knowledge and visual-language feature similarity. We designed a series of long-sequence navigation tasks for frequently used everyday items in the Habitat simulator. The results demonstrate that by updating the CRSG, the robot can efficiently navigate to moved targets. Additionally, we deployed our algorithm on a real robot and validated its practical effectiveness. The project page can be found here: https://OpenIN-nav.github.io.
OpenObject-NAV: Open-Vocabulary Object-Oriented Navigation Based on Dynamic Carrier-Relationship Scene Graph
Sep 27, 2024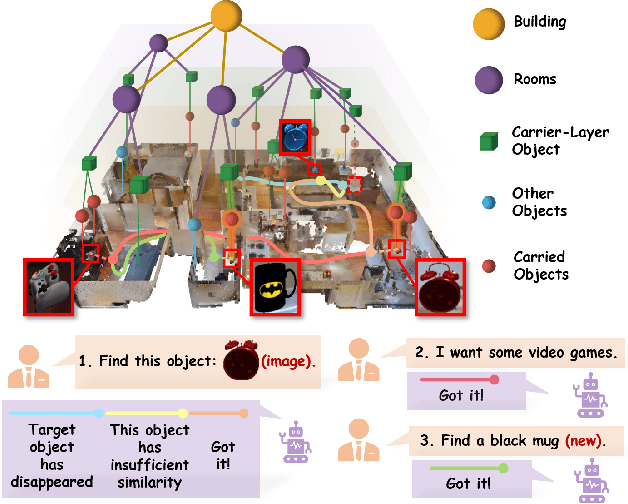
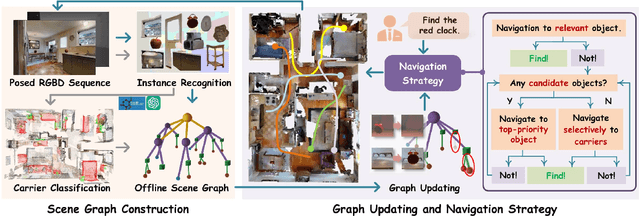
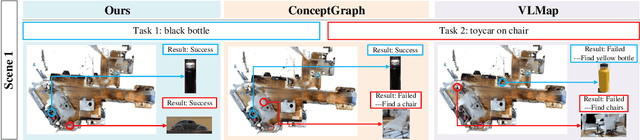
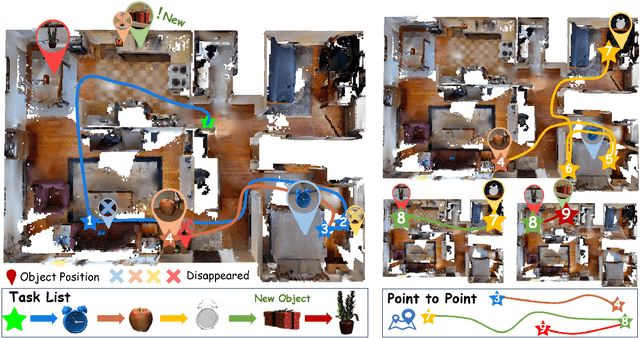
In everyday life, frequently used objects like cups often have unfixed positions and multiple instances within the same category, and their carriers frequently change as well. As a result, it becomes challenging for a robot to efficiently navigate to a specific instance. To tackle this challenge, the robot must capture and update scene changes and plans continuously. However, current object navigation approaches primarily focus on semantic-level and lack the ability to dynamically update scene representation. This paper captures the relationships between frequently used objects and their static carriers. It constructs an open-vocabulary Carrier-Relationship Scene Graph (CRSG) and updates the carrying status during robot navigation to reflect the dynamic changes of the scene. Based on the CRSG, we further propose an instance navigation strategy that models the navigation process as a Markov Decision Process. At each step, decisions are informed by Large Language Model's commonsense knowledge and visual-language feature similarity. We designed a series of long-sequence navigation tasks for frequently used everyday items in the Habitat simulator. The results demonstrate that by updating the CRSG, the robot can efficiently navigate to moved targets. Additionally, we deployed our algorithm on a real robot and validated its practical effectiveness.
Unwieldy Object Delivery with Nonholonomic Mobile Base: A Stable Pushing Approach
Sep 25, 2023
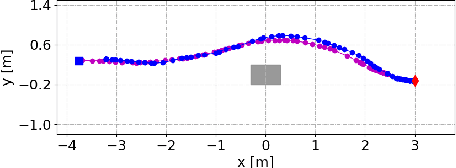

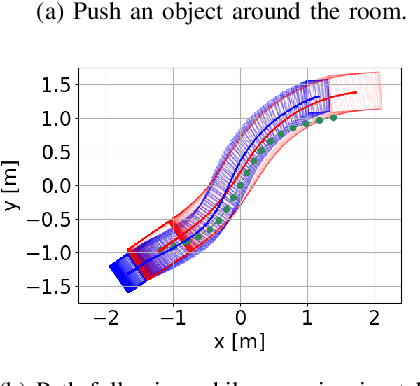
This paper addresses the problem of pushing manipulation with nonholonomic mobile robots. Pushing is a fundamental skill that enables robots to move unwieldy objects that cannot be grasped. We propose a stable pushing method that maintains stiff contact between the robot and the object to avoid consuming repositioning actions. We prove that a line contact, rather than a single point contact, is necessary for nonholonomic robots to achieve stable pushing. We also show that the stable pushing constraint and the nonholonomic constraint of the robot can be simplified as a concise linear motion constraint. Then the pushing planning problem can be formulated as a constrained optimization problem using nonlinear model predictive control (NMPC). According to the experiments, our NMPC-based planner outperforms a reactive pushing strategy in terms of efficiency, reducing the robot's traveled distance by 23.8\% and time by 77.4\%. Furthermore, our method requires four fewer hyperparameters and decision variables than the Linear Time-Varying (LTV) MPC approach, making it easier to implement. Real-world experiments are carried out to validate the proposed method with two differential-drive robots, Husky and Boxer, under different friction conditions.
Distributed Information-based Source Seeking
Sep 20, 2022

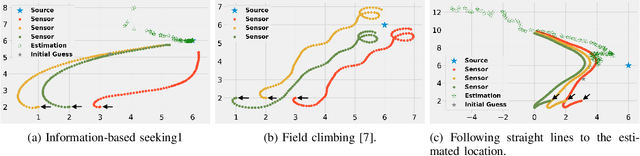
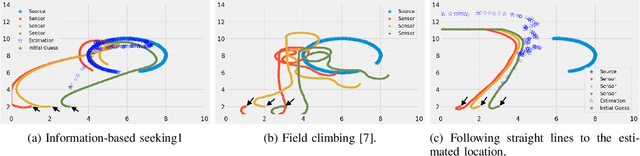
In this paper, we design an information-based multi-robot source seeking algorithm where a group of mobile sensors localizes and moves close to a single source using only local range-based measurements. In the algorithm, the mobile sensors perform source identification/localization to estimate the source location; meanwhile, they move to new locations to maximize the Fisher information about the source contained in the sensor measurements. In doing so, they improve the source location estimate and move closer to the source. Our algorithm is superior in convergence speed compared with traditional field climbing algorithms, is flexible in the measurement model and the choice of information metric, and is robust to measurement model errors. Moreover, we provide a fully distributed version of our algorithm, where each sensor decides its own actions and only shares information with its neighbors through a sparse communication network. We perform intensive simulation experiments to test our algorithms on large-scale systems and physical experiments on small ground vehicles with light sensors, demonstrating success in seeking a light source.
Communication-Efficient Distributed SGD with Compressed Sensing
Dec 15, 2021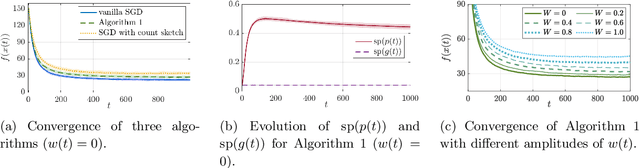
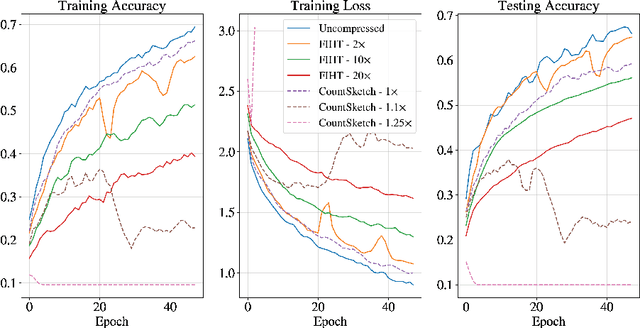
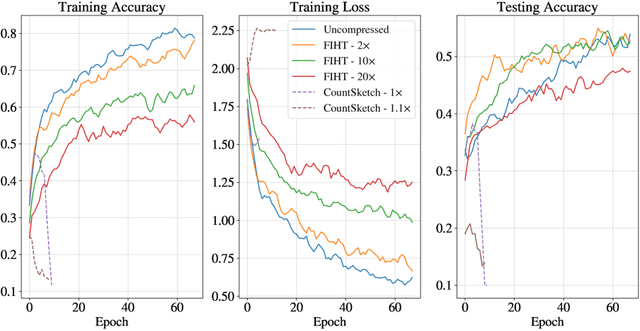
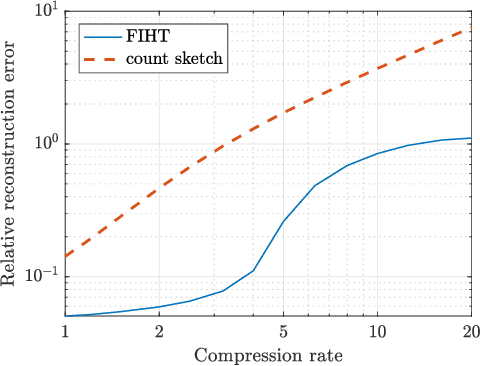
We consider large scale distributed optimization over a set of edge devices connected to a central server, where the limited communication bandwidth between the server and edge devices imposes a significant bottleneck for the optimization procedure. Inspired by recent advances in federated learning, we propose a distributed stochastic gradient descent (SGD) type algorithm that exploits the sparsity of the gradient, when possible, to reduce communication burden. At the heart of the algorithm is to use compressed sensing techniques for the compression of the local stochastic gradients at the device side; and at the server side, a sparse approximation of the global stochastic gradient is recovered from the noisy aggregated compressed local gradients. We conduct theoretical analysis on the convergence of our algorithm in the presence of noise perturbation incurred by the communication channels, and also conduct numerical experiments to corroborate its effectiveness.
Reinforcement Learning Compensated Extended Kalman Filter for Attitude Estimation
Jul 27, 2021
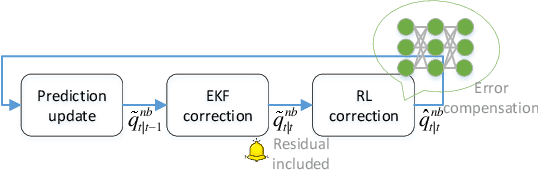
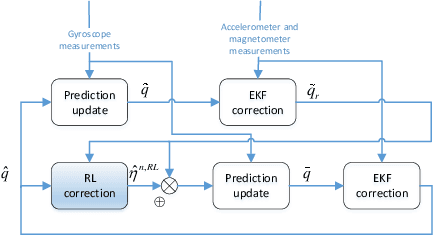
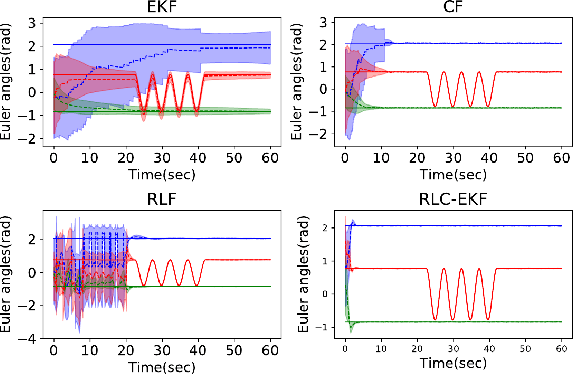
Inertial measurement units are widely used in different fields to estimate the attitude. Many algorithms have been proposed to improve estimation performance. However, most of them still suffer from 1) inaccurate initial estimation, 2) inaccurate initial filter gain, and 3) non-Gaussian process and/or measurement noise. In this paper, we leverage reinforcement learning to compensate for the classical extended Kalman filter estimation, i.e., to learn the filter gain from the sensor measurements. We also analyse the convergence of the estimate error. The effectiveness of the proposed algorithm is validated on both simulated data and real data.
Reinforcement Learning for Orientation Estimation Using Inertial Sensors with Performance Guarantee
Mar 03, 2021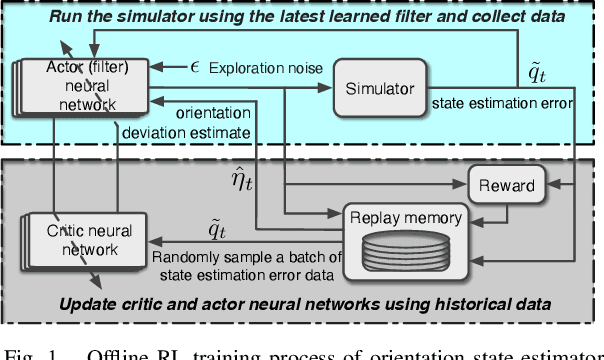
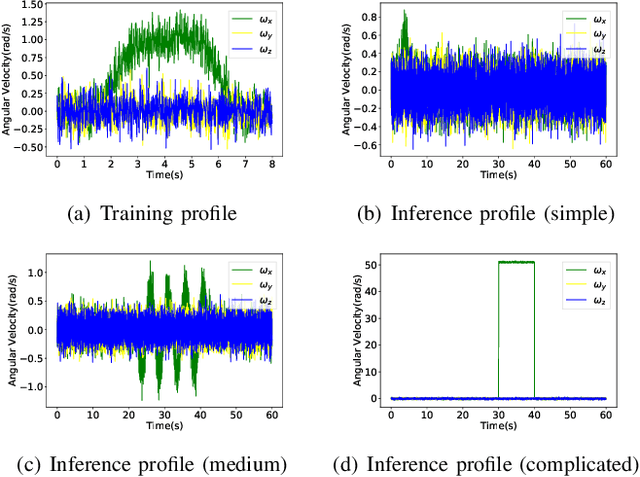
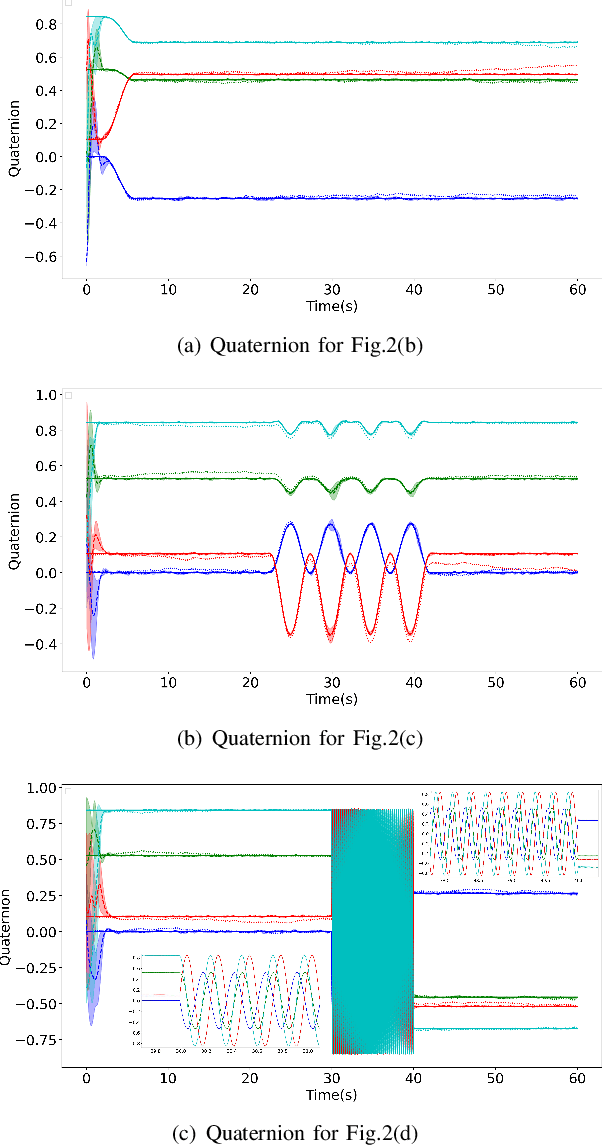
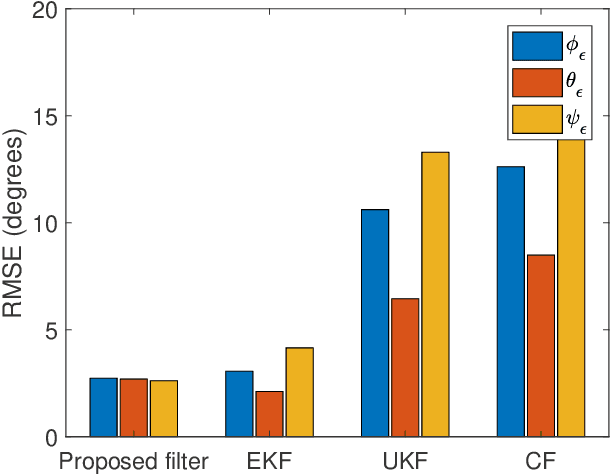
This paper presents a deep reinforcement learning (DRL) algorithm for orientation estimation using inertial sensors combined with magnetometer. The Lyapunov method in control theory is employed to prove the convergence of orientation estimation errors. Based on the theoretical results, the estimator gains and a Lyapunov function are parametrized by deep neural networks and learned from samples. The DRL estimator is compared with three well-known orientation estimation methods on both numerical simulations and real datasets collected from commercially available sensors. The results show that the proposed algorithm is superior for arbitrary estimation initialization and can adapt to very large angular velocities for which other algorithms can be hardly applicable. To the best of our knowledge, this is the first DRL-based orientation estimation method with estimation error boundedness guarantee.
Reinforcement Learning for Decision-Making and Control in Power Systems: Tutorial, Review, and Vision
Feb 05, 2021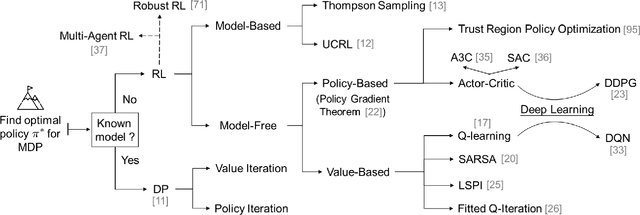
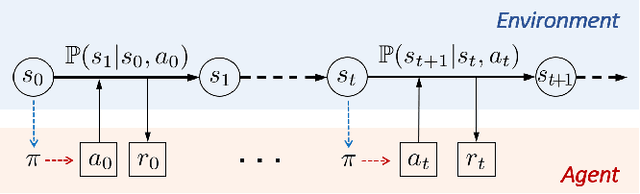
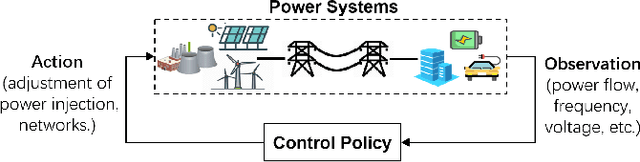
With large-scale integration of renewable generation and ubiquitous distributed energy resources (DERs), modern power systems confront a series of new challenges in operation and control, such as growing complexity, increasing uncertainty, and aggravating volatility. While the upside is that more and more data are available owing to the widely-deployed smart meters, smart sensors, and upgraded communication networks. As a result, data-driven control techniques, especially reinforcement learning (RL), have attracted surging attention in recent years. In this paper, we focus on RL and aim to provide a tutorial on various RL techniques and how they can be applied to the decision-making and control in power systems. In particular, we select three key applications, including frequency regulation, voltage control, and energy management, for illustration, and present the typical ways to model and tackle them with RL methods. We conclude by emphasizing two critical issues in the application of RL, i.e., safety and scalability. Several potential future directions are discussed as well.