 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Distributed SGD with Compressed Sensing
Paper and Code
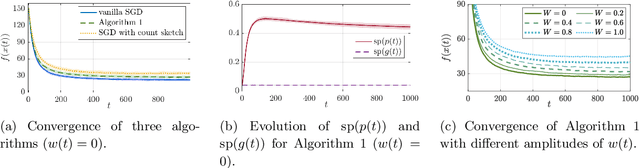
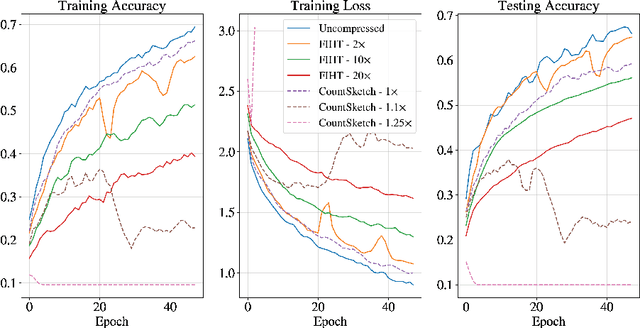
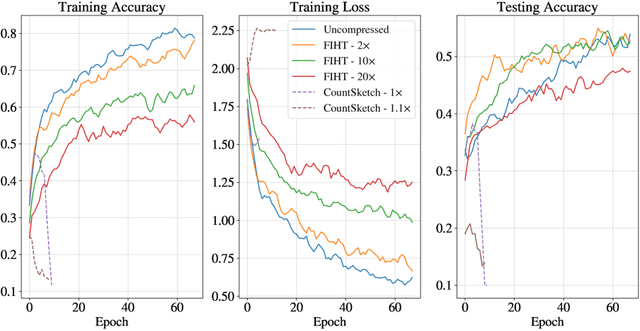
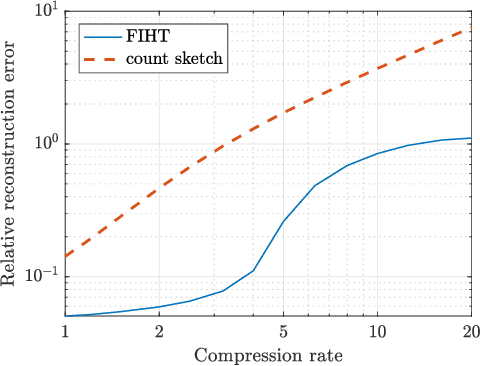
We consider large scale distributed optimization over a set of edge devices connected to a central server, where the limited communication bandwidth between the server and edge devices imposes a significant bottleneck for the optimization procedure. Inspired by recent advances in federated learning, we propose a distributed stochastic gradient descent (SGD) type algorithm that exploits the sparsity of the gradient, when possible, to reduce communication burden. At the heart of the algorithm is to use compressed sensing techniques for the compression of the local stochastic gradients at the device side; and at the server side, a sparse approximation of the global stochastic gradient is recovered from the noisy aggregated compressed local gradients. We conduct theoretical analysis on the convergence of our algorithm in the presence of noise perturbation incurred by the communication channels, and also conduct numerical experiments to corroborate its effectiveness.