 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Reinforcement Learning for Decentralized Linear Quadratic Control: A Derivative-Free Policy Optimization Approach
Paper and Code
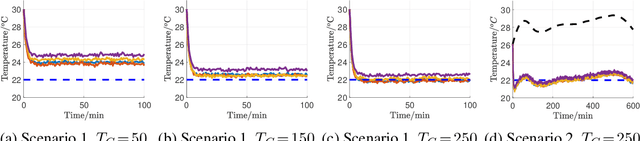
This paper considers a distributed reinforcement learning problem for decentralized linear quadratic control with partial state observations and local costs. We propose the Zero-Order Distributed Policy Optimization algorithm (ZODPO) that learns linear local controllers in a distributed fashion, leveraging the ideas of policy gradient, zero-order optimization and consensus algorithms. In ZODPO, each agent estimates the global cost by consensus, and then conducts local policy gradient in parallel based on zero-order gradient estimation. ZODPO only requires limited communication and storage even in large-scale systems. Further, we investigate the nonasymptotic performance of ZODPO and show that the sample complexity to approach a stationary point is polynomial with the error tolerance's inverse and the problem dimensions, demonstrating the scalability of ZODPO. We also show that the controllers generated by ZODPO are stabilizing with high probability. Lastly, we numerically test ZODPO on a multi-zone HVAC system.