 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee Once, Then Act: Vision-Language-Action Model with Task Learning from One-Shot Video Demonstrations
Dec 08, 2025Developing robust and general-purpose manipulation policies represents a fundamental objective in robotics research. While Vision-Language-Action (VLA) models have demonstrated promising capabilities for end-to-end robot control, existing approaches still exhibit limited generalization to tasks beyond their training distributions. In contrast, humans possess remarkable proficiency in acquiring novel skills by simply observing others performing them once. Inspired by this capability, we propose ViVLA, a generalist robotic manipulation policy that achieves efficient task learning from a single expert demonstration video at test time. Our approach jointly processes an expert demonstration video alongside the robot's visual observations to predict both the demonstrated action sequences and subsequent robot actions, effectively distilling fine-grained manipulation knowledge from expert behavior and transferring it seamlessly to the agent. To enhance the performance of ViVLA, we develop a scalable expert-agent pair data generation pipeline capable of synthesizing paired trajectories from easily accessible human videos, further augmented by curated pairs from publicly available datasets. This pipeline produces a total of 892,911 expert-agent samples for training ViVLA. Experimental results demonstrate that our ViVLA is able to acquire novel manipulation skills from only a single expert demonstration video at test time. Our approach achieves over 30% improvement on unseen LIBERO tasks and maintains above 35% gains with cross-embodiment videos. Real-world experiments demonstrate effective learning from human videos, yielding more than 38% improvement on unseen tasks.
FMimic: Foundation Models are Fine-grained Action Learners from Human Videos
Jul 28, 2025Visual imitation learning (VIL) provides an efficient and intuitive strategy for robotic systems to acquire novel skills. Recent advancements in foundation models, particularly Vision Language Models (VLMs), have demonstrated remarkable capabilities in visual and linguistic reasoning for VIL tasks. Despite this progress, existing approaches primarily utilize these models for learning high-level plans from human demonstrations, relying on pre-defined motion primitives for executing physical interactions, which remains a major bottleneck for robotic systems. In this work, we present FMimic, a novel paradigm that harnesses foundation models to directly learn generalizable skills at even fine-grained action levels, using only a limited number of human videos. Extensive experiments demonstrate that our FMimic delivers strong performance with a single human video, and significantly outperforms all other methods with five videos. Furthermore, our method exhibits significant improvements of over 39% and 29% in RLBench multi-task experiments and real-world manipulation tasks, respectively, and exceeds baselines by more than 34% in high-precision tasks and 47% in long-horizon tasks.
Point Tree Transformer for Point Cloud Registration
Jun 25, 2024



Point cloud registration is a fundamental task in the fields of computer vision and robotics. Recent developments in transformer-based methods have demonstrated enhanced performance in this domain. However, the standard attention mechanism utilized in these methods often integrates many low-relevance points, thereby struggling to prioritize its attention weights on sparse yet meaningful points. This inefficiency leads to limited local structure modeling capabilities and quadratic computational complexity. To overcome these limitations, we propose the Point Tree Transformer (PTT), a novel transformer-based approach for point cloud registration that efficiently extracts comprehensive local and global features while maintaining linear computational complexity. The PTT constructs hierarchical feature trees from point clouds in a coarse-to-dense manner, and introduces a novel Point Tree Attention (PTA) mechanism, which follows the tree structure to facilitate the progressive convergence of attended regions towards salient points. Specifically, each tree layer selectively identifies a subset of key points with the highest attention scores. Subsequent layers focus attention on areas of significant relevance, derived from the child points of the selected point set. The feature extraction process additionally incorporates coarse point features that capture high-level semantic information, thus facilitating local structure modeling and the progressive integration of multiscale information. Consequently, PTA empowers the model to concentrate on crucial local structures and derive detailed local information while maintaining linear computational complexity. Extensive experiments conducted on the 3DMatch, ModelNet40, and KITTI datasets demonstrate that our method achieves superior performance over the state-of-the-art methods.
OpenGraph: Open-Vocabulary Hierarchical 3D Graph Representation in Large-Scale Outdoor Environments
Mar 28, 2024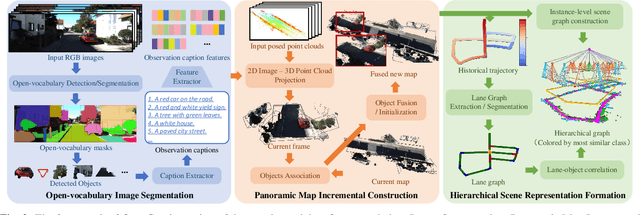
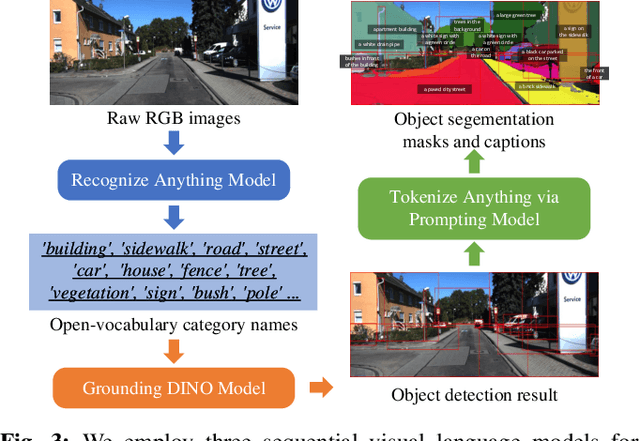

Environment representations endowed with sophisticated semantics are pivotal for facilitating seamless interaction between robots and humans, enabling them to effectively carry out various tasks. Open-vocabulary maps, powered by Visual-Language models (VLMs), possess inherent advantages, including zero-shot learning and support for open-set classes. However, existing open-vocabulary maps are primarily designed for small-scale environments, such as desktops or rooms, and are typically geared towards limited-area tasks involving robotic indoor navigation or in-place manipulation. They face challenges in direct generalization to outdoor environments characterized by numerous objects and complex tasks, owing to limitations in both understanding level and map structure. In this work, we propose OpenGraph, the first open-vocabulary hierarchical graph representation designed for large-scale outdoor environments. OpenGraph initially extracts instances and their captions from visual images, enhancing textual reasoning by encoding them. Subsequently, it achieves 3D incremental object-centric mapping with feature embedding by projecting images onto LiDAR point clouds. Finally, the environment is segmented based on lane graph connectivity to construct a hierarchical graph. Validation results from public dataset SemanticKITTI demonstrate that OpenGraph achieves the highest segmentation and query accuracy. The source code of OpenGraph is publicly available at https://github.com/BIT-DYN/OpenGraph.
Human Demonstrations are Generalizable Knowledge for Robots
Dec 05, 2023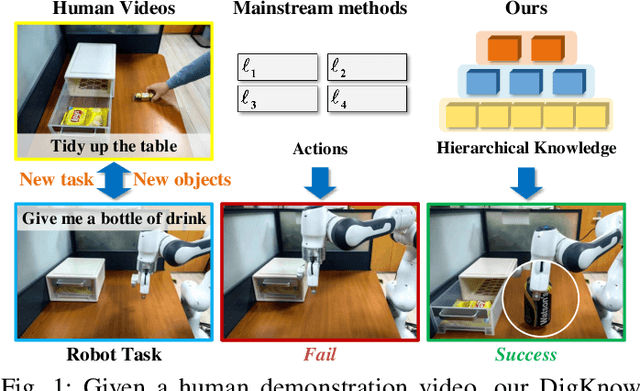
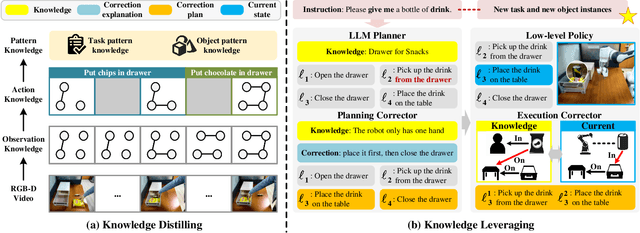


Learning from human demonstrations is an emerging trend for designing intelligent robotic systems. However, previous methods typically regard videos as instructions, simply dividing them into action sequences for robotic repetition, which poses obstacles to generalization to diverse tasks or object instances. In this paper, we propose a different perspective, considering human demonstration videos not as mere instructions, but as a source of knowledge for robots. Motivated by this perspective and the remarkable comprehension and generalization capabilities exhibited by large language models (LLMs), we propose DigKnow, a method that DIstills Generalizable KNOWledge with a hierarchical structure. Specifically, DigKnow begins by converting human demonstration video frames into observation knowledge. This knowledge is then subjected to analysis to extract human action knowledge and further distilled into pattern knowledge compassing task and object instances, resulting in the acquisition of generalizable knowledge with a hierarchical structure. In settings with different tasks or object instances, DigKnow retrieves relevant knowledge for the current task and object instances. Subsequently, the LLM-based planner conducts planning based on the retrieved knowledge, and the policy executes actions in line with the plan to achieve the designated task. Utilizing the retrieved knowledge, we validate and rectify planning and execution outcomes, resulting in a substantial enhancement of the success rate. Experimental results across a range of tasks and scenes demonstrate the effectiveness of this approach in facilitating real-world robots to accomplish tasks with the knowledge derived from human demonstrations.
PointGPT: Auto-regressively Generative Pre-training from Point Clouds
May 23, 2023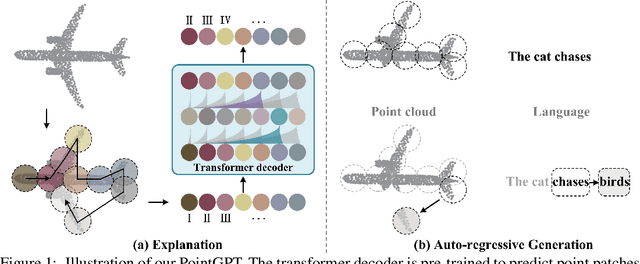
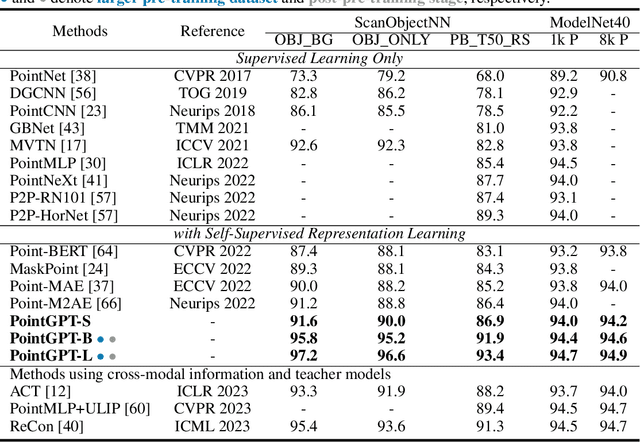
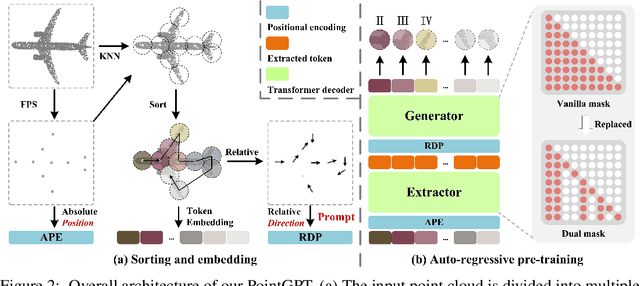
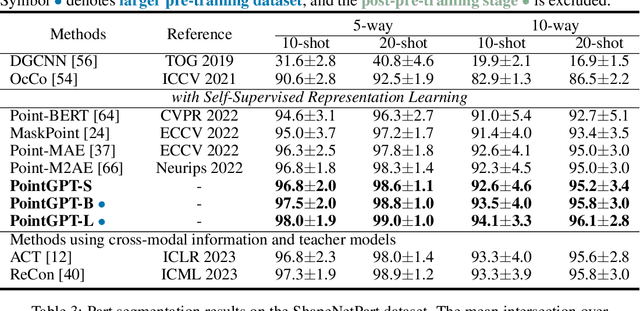
Large language models (LLMs) based on the generative pre-training transformer (GPT) have demonstrated remarkable effectiveness across a diverse range of downstream tasks. Inspired by the advancements of the GPT, we present PointGPT, a novel approach that extends the concept of GPT to point clouds, addressing the challenges associated with disorder properties, low information density, and task gaps. Specifically, a point cloud auto-regressive generation task is proposed to pre-train transformer models. Our method partitions the input point cloud into multiple point patches and arranges them in an ordered sequence based on their spatial proximity. Then, an extractor-generator based transformer decoder, with a dual masking strategy, learns latent representations conditioned on the preceding point patches, aiming to predict the next one in an auto-regressive manner. Our scalable approach allows for learning high-capacity models that generalize well, achieving state-of-the-art performance on various downstream tasks. In particular, our approach achieves classification accuracies of 94.9% on the ModelNet40 dataset and 93.4% on the ScanObjectNN dataset, outperforming all other transformer models. Furthermore, our method also attains new state-of-the-art accuracies on all four few-shot learning benchmarks.
Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction
Dec 17, 2021
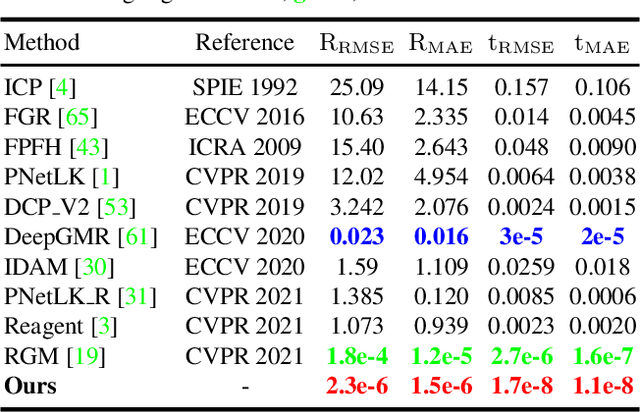
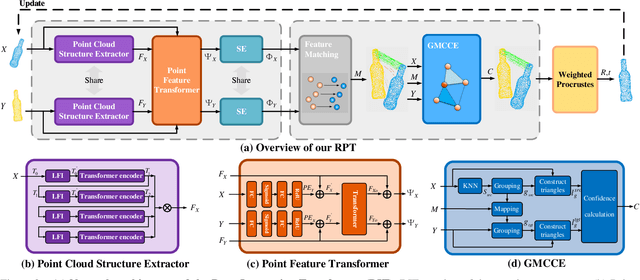
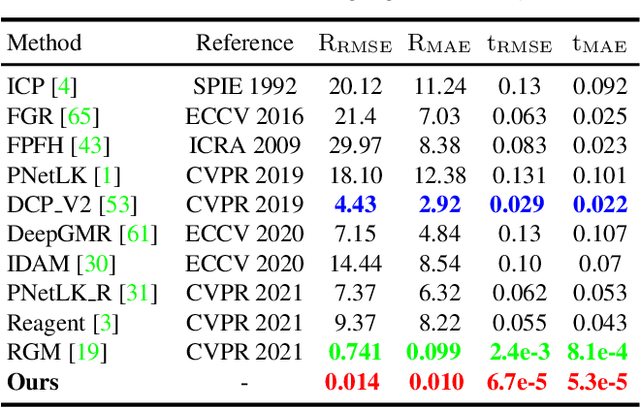
Recent Transformer-based methods have achieved advanced performance in point cloud registration by utilizing advantages of the Transformer in order-invariance and modeling dependency to aggregate information. However, they still suffer from indistinct feature extraction, sensitivity to noise, and outliers. The reasons are: (1) the adoption of CNNs fails to model global relations due to their local receptive fields, resulting in extracted features susceptible to noise; (2) the shallow-wide architecture of Transformers and lack of positional encoding lead to indistinct feature extraction due to inefficient information interaction; (3) the omission of geometrical compatibility leads to inaccurate classification between inliers and outliers. To address above limitations, a novel full Transformer network for point cloud registration is proposed, named the Deep Interaction Transformer (DIT), which incorporates: (1) a Point Cloud Structure Extractor (PSE) to model global relations and retrieve structural information with Transformer encoders; (2) a deep-narrow Point Feature Transformer (PFT) to facilitate deep information interaction across two point clouds with positional encoding, such that Transformers can establish comprehensive associations and directly learn relative position between points; (3) a Geometric Matching-based Correspondence Confidence Evaluation (GMCCE) method to measure spatial consistency and estimate inlier confidence by designing the triangulated descriptor. Extensive experiments on clean, noisy, partially overlapping point cloud registration demonstrate that our method outperforms state-of-the-art methods.