 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMimic: Foundation Models are Fine-grained Action Learners from Human Videos
Jul 28, 2025Visual imitation learning (VIL) provides an efficient and intuitive strategy for robotic systems to acquire novel skills. Recent advancements in foundation models, particularly Vision Language Models (VLMs), have demonstrated remarkable capabilities in visual and linguistic reasoning for VIL tasks. Despite this progress, existing approaches primarily utilize these models for learning high-level plans from human demonstrations, relying on pre-defined motion primitives for executing physical interactions, which remains a major bottleneck for robotic systems. In this work, we present FMimic, a novel paradigm that harnesses foundation models to directly learn generalizable skills at even fine-grained action levels, using only a limited number of human videos. Extensive experiments demonstrate that our FMimic delivers strong performance with a single human video, and significantly outperforms all other methods with five videos. Furthermore, our method exhibits significant improvements of over 39% and 29% in RLBench multi-task experiments and real-world manipulation tasks, respectively, and exceeds baselines by more than 34% in high-precision tasks and 47% in long-horizon tasks.
VLMimic: Vision Language Models are Visual Imitation Learner for Fine-grained Actions
Oct 29, 2024

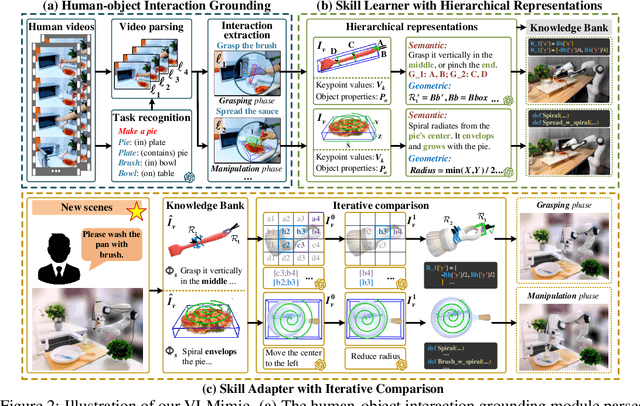

Visual imitation learning (VIL) provides an efficient and intuitive strategy for robotic systems to acquire novel skills. Recent advancements in Vision Language Models (VLMs) have demonstrated remarkable performance in vision and language reasoning capabilities for VIL tasks. Despite the progress, current VIL methods naively employ VLMs to learn high-level plans from human videos, relying on pre-defined motion primitives for executing physical interactions, which remains a major bottleneck. In this work, we present VLMimic, a novel paradigm that harnesses VLMs to directly learn even fine-grained action levels, only given a limited number of human videos. Specifically, VLMimic first grounds object-centric movements from human videos, and learns skills using hierarchical constraint representations, facilitating the derivation of skills with fine-grained action levels from limited human videos. These skills are refined and updated through an iterative comparison strategy, enabling efficient adaptation to unseen environments. Our extensive experiments exhibit that our VLMimic, using only 5 human videos, yields significant improvements of over 27% and 21% in RLBench and real-world manipulation tasks, and surpasses baselines by over 37% in long-horizon tasks.
Human Demonstrations are Generalizable Knowledge for Robots
Dec 05, 2023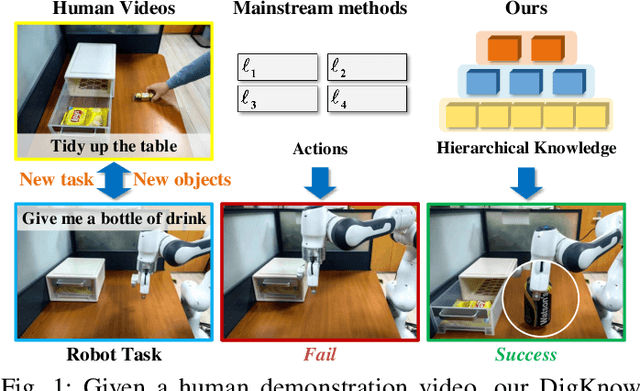
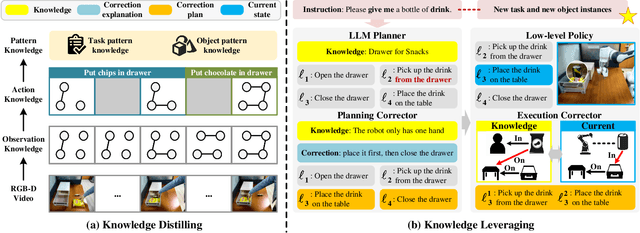


Learning from human demonstrations is an emerging trend for designing intelligent robotic systems. However, previous methods typically regard videos as instructions, simply dividing them into action sequences for robotic repetition, which poses obstacles to generalization to diverse tasks or object instances. In this paper, we propose a different perspective, considering human demonstration videos not as mere instructions, but as a source of knowledge for robots. Motivated by this perspective and the remarkable comprehension and generalization capabilities exhibited by large language models (LLMs), we propose DigKnow, a method that DIstills Generalizable KNOWledge with a hierarchical structure. Specifically, DigKnow begins by converting human demonstration video frames into observation knowledge. This knowledge is then subjected to analysis to extract human action knowledge and further distilled into pattern knowledge compassing task and object instances, resulting in the acquisition of generalizable knowledge with a hierarchical structure. In settings with different tasks or object instances, DigKnow retrieves relevant knowledge for the current task and object instances. Subsequently, the LLM-based planner conducts planning based on the retrieved knowledge, and the policy executes actions in line with the plan to achieve the designated task. Utilizing the retrieved knowledge, we validate and rectify planning and execution outcomes, resulting in a substantial enhancement of the success rate. Experimental results across a range of tasks and scenes demonstrate the effectiveness of this approach in facilitating real-world robots to accomplish tasks with the knowledge derived from human demonstrations.