 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaAttN: Revisit Attention Mechanism in Arbitrary Neural Style Transfer
Aug 11, 2021
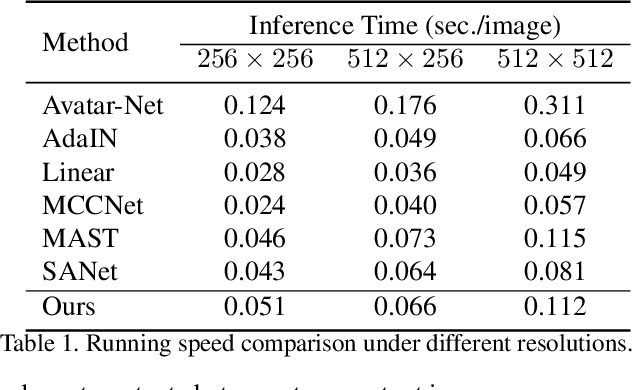


Fast arbitrary neural style transfer has attracted widespread attention from academic, industrial and art communities due to its flexibility in enabling various applications. Existing solutions either attentively fuse deep style feature into deep content feature without considering feature distributions, or adaptively normalize deep content feature according to the style such that their global statistics are matched. Although effective, leaving shallow feature unexplored and without locally considering feature statistics, they are prone to unnatural output with unpleasing local distortions. To alleviate this problem, in this paper, we propose a novel attention and normalization module, named Adaptive Attention Normalization (AdaAttN), to adaptively perform attentive normalization on per-point basis. Specifically, spatial attention score is learnt from both shallow and deep features of content and style images. Then per-point weighted statistics are calculated by regarding a style feature point as a distribution of attention-weighted output of all style feature points. Finally, the content feature is normalized so that they demonstrate the same local feature statistics as the calculated per-point weighted style feature statistics. Besides, a novel local feature loss is derived based on AdaAttN to enhance local visual quality. We also extend AdaAttN to be ready for video style transfer with slight modifications. Experiments demonstrate that our method achieves state-of-the-art arbitrary image/video style transfer. Codes and models are available.
3D Shape Segmentation via Shape Fully Convolutional Networks
May 26, 2018
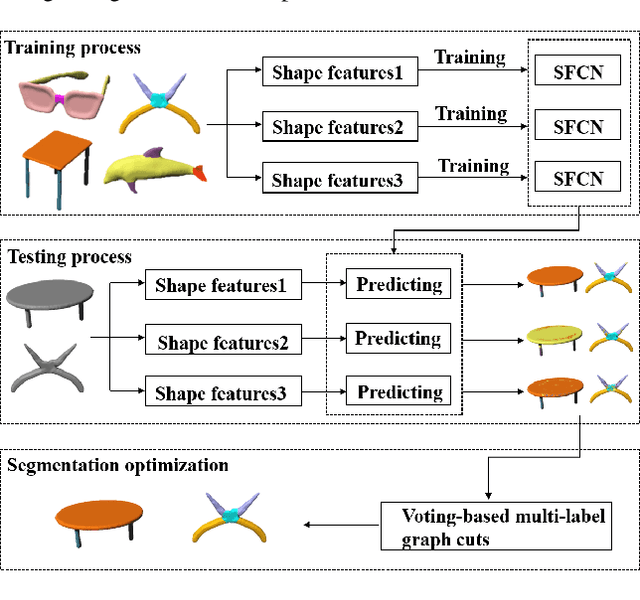
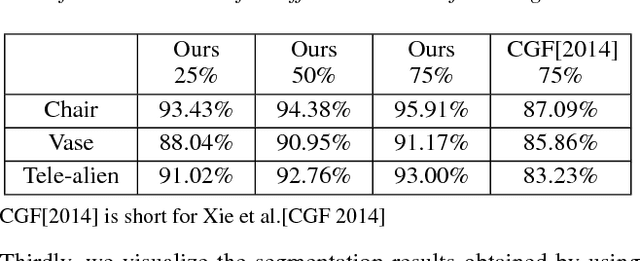
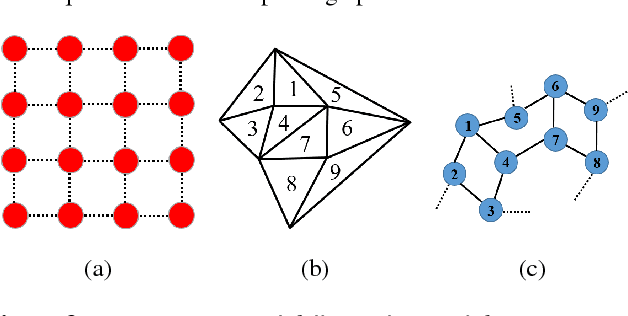
We desgin a novel fully convolutional network architecture for shapes, denoted by Shape Fully Convolutional Networks (SFCN). 3D shapes are represented as graph structures in the SFCN architecture, based on novel graph convolution and pooling operations, which are similar to convolution and pooling operations used on images. Meanwhile, to build our SFCN architecture in the original image segmentation fully convolutional network (FCN) architecture, we also design and implement a generating operation} with bridging function. This ensures that the convolution and pooling operation we have designed can be successfully applied in the original FCN architecture. In this paper, we also present a new shape segmentation approach based on SFCN. Furthermore, we allow more general and challenging input, such as mixed datasets of different categories of shapes} which can prove the ability of our generalisation. In our approach, SFCNs are trained triangles-to-triangles by using three low-level geometric features as input. Finally, the feature voting-based multi-label graph cuts is adopted to optimise the segmentation results obtained by SFCN prediction. The experiment results show that our method can effectively learn and predict mixed shape datasets of either similar or different characteristics, and achieve excellent segmentation results.
* We update some missing references about intrinsic CNNs (2018.5.24)
Progressive refinement: a method of coarse-to-fine image parsing using stacked network
Apr 23, 2018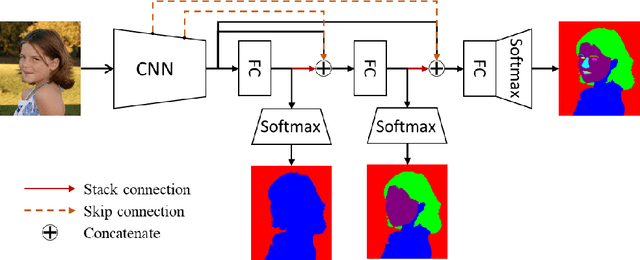


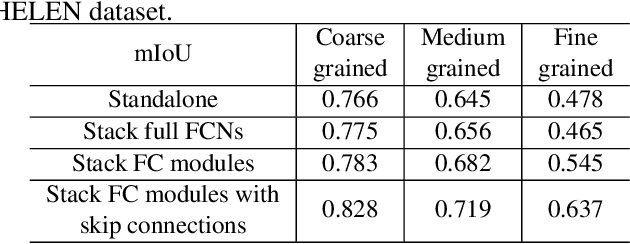
To parse images into fine-grained semantic parts, the complex fine-grained elements will put it in trouble when using off-the-shelf semantic segmentation networks. In this paper, for image parsing task, we propose to parse images from coarse to fine with progressively refined semantic classes. It is achieved by stacking the segmentation layers in a segmentation network several times. The former segmentation module parses images at a coarser-grained level, and the result will be feed to the following one to provide effective contextual clues for the finer-grained parsing. To recover the details of small structures, we add skip connections from shallow layers of the network to fine-grained parsing modules. As for the network training, we merge classes in groundtruth to get coarse-to-fine label maps, and train the stacked network with these hierarchical supervision end-to-end. Our coarse-to-fine stacked framework can be injected into many advanced neural networks to improve the parsing results. Extensive evaluations on several public datasets including face parsing and human parsing well demonstrate the superiority of our method.