 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapTalk: Text-Guided Stylization and Speech-Driven 3D Head Animation
May 28, 2026Audio-driven 3D facial animation aims to generate synchronized lip movements and vivid facial expressions from arbitrary audio clips. While existing methods can produce synchronized lip motions, they often rely on predefined identity or style latent features, which limits users' ability to freely control speaking styles. Moreover, applying a fixed style or identity to an entire audio segment typically results in facial animation styles that do not adapt to the emotional content of the audio. To address these challenges, we revisit the entanglement between style and emotion, construct a large-scale dataset with textual descriptions of both style and emotion, and propose a novel talking head generation framework that enables separate control over style and emotion. Our model takes as input both textual descriptions of speaking style and character emotion, as well as the driving audio stream, enabling real-time generation of highly synchronized lip movements and facial expressions that match the provided descriptions. Furthermore, our model supports dynamic emotion control during inference, allowing it to handle scenarios where the target emotion changes throughout the speech.
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
RealX3D: A Physically-Degraded 3D Benchmark for Multi-view Visual Restoration and Reconstruction
Dec 29, 2025We introduce RealX3D, a real-capture benchmark for multi-view visual restoration and 3D reconstruction under diverse physical degradations. RealX3D groups corruptions into four families, including illumination, scattering, occlusion, and blurring, and captures each at multiple severity levels using a unified acquisition protocol that yields pixel-aligned LQ/GT views. Each scene includes high-resolution capture, RAW images, and dense laser scans, from which we derive world-scale meshes and metric depth. Benchmarking a broad range of optimization-based and feed-forward methods shows substantial degradation in reconstruction quality under physical corruptions, underscoring the fragility of current multi-view pipelines in real-world challenging environments.
Efficient Emotional Adaptation for Audio-Driven Talking-Head Generation
Sep 10, 2023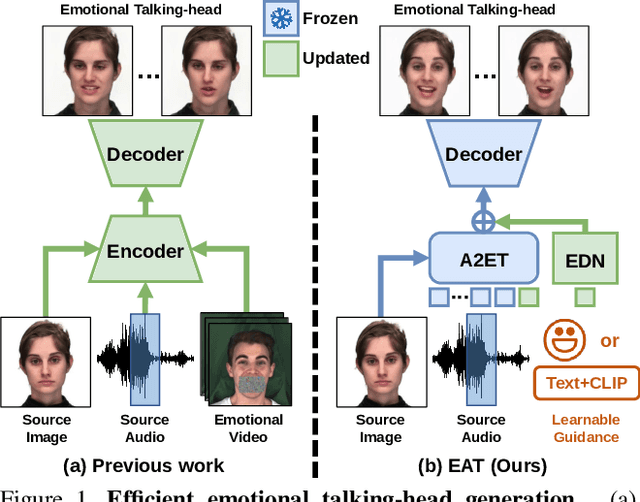
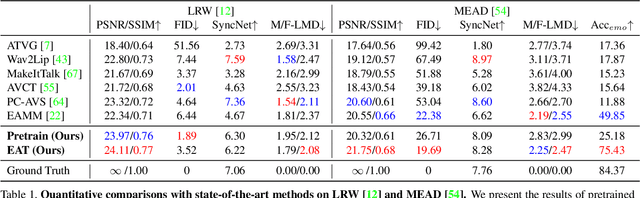
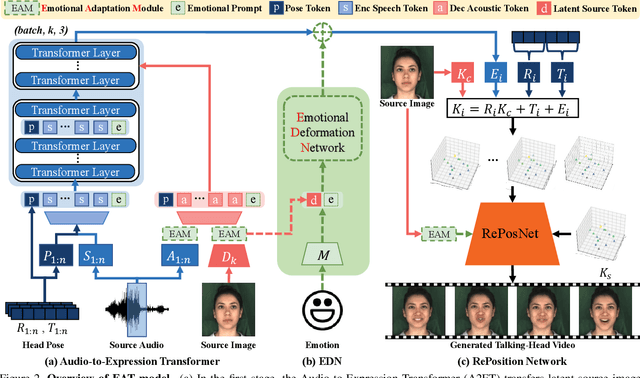
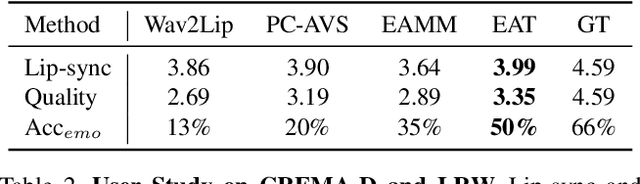
Audio-driven talking-head synthesis is a popular research topic for virtual human-related applications. However, the inflexibility and inefficiency of existing methods, which necessitate expensive end-to-end training to transfer emotions from guidance videos to talking-head predictions, are significant limitations. In this work, we propose the Emotional Adaptation for Audio-driven Talking-head (EAT) method, which transforms emotion-agnostic talking-head models into emotion-controllable ones in a cost-effective and efficient manner through parameter-efficient adaptations. Our approach utilizes a pretrained emotion-agnostic talking-head transformer and introduces three lightweight adaptations (the Deep Emotional Prompts, Emotional Deformation Network, and Emotional Adaptation Module) from different perspectives to enable precise and realistic emotion controls. Our experiments demonstrate that our approach achieves state-of-the-art performance on widely-used benchmarks, including LRW and MEAD. Additionally, our parameter-efficient adaptations exhibit remarkable generalization ability, even in scenarios where emotional training videos are scarce or nonexistent. Project website: https://yuangan.github.io/eat/
VidFace: A Full-Transformer Solver for Video FaceHallucination with Unaligned Tiny Snapshots
May 31, 2021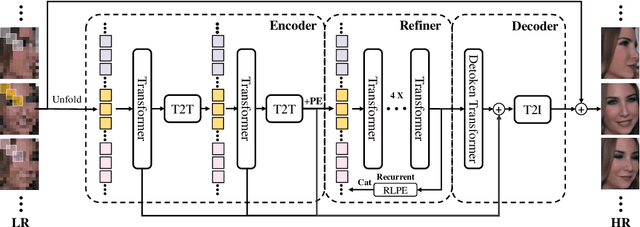
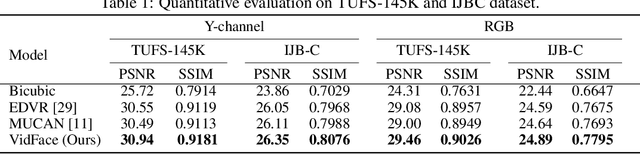


In this paper, we investigate the task of hallucinating an authentic high-resolution (HR) human face from multiple low-resolution (LR) video snapshots. We propose a pure transformer-based model, dubbed VidFace, to fully exploit the full-range spatio-temporal information and facial structure cues among multiple thumbnails. Specifically, VidFace handles multiple snapshots all at once and harnesses the spatial and temporal information integrally to explore face alignments across all the frames, thus avoiding accumulating alignment errors. Moreover, we design a recurrent position embedding module to equip our transformer with facial priors, which not only effectively regularises the alignment mechanism but also supplants notorious pre-training. Finally, we curate a new large-scale video face hallucination dataset from the public Voxceleb2 benchmark, which challenges prior arts on tackling unaligned and tiny face snapshots. To the best of our knowledge, we are the first attempt to develop a unified transformer-based solver tailored for video-based face hallucination. Extensive experiments on public video face benchmarks show that the proposed method significantly outperforms the state of the arts.
3D Shape Segmentation via Shape Fully Convolutional Networks
May 26, 2018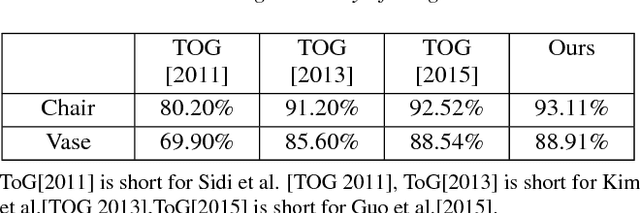
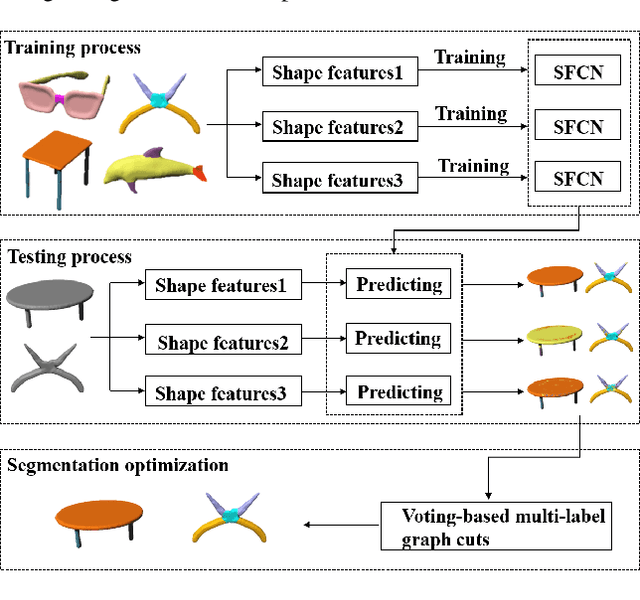
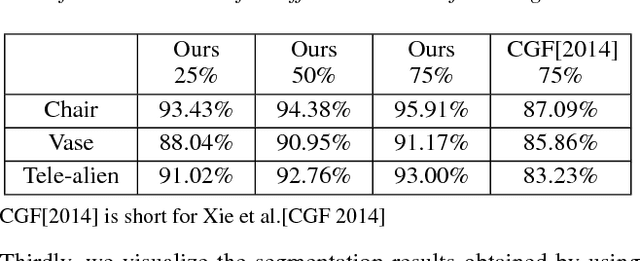
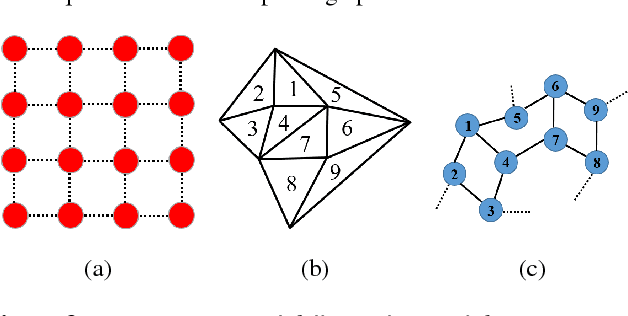
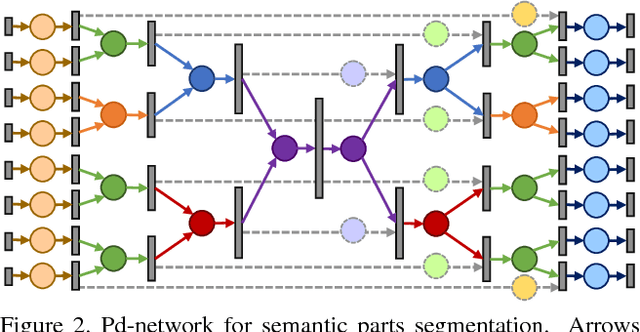
We desgin a novel fully convolutional network architecture for shapes, denoted by Shape Fully Convolutional Networks (SFCN). 3D shapes are represented as graph structures in the SFCN architecture, based on novel graph convolution and pooling operations, which are similar to convolution and pooling operations used on images. Meanwhile, to build our SFCN architecture in the original image segmentation fully convolutional network (FCN) architecture, we also design and implement a generating operation} with bridging function. This ensures that the convolution and pooling operation we have designed can be successfully applied in the original FCN architecture. In this paper, we also present a new shape segmentation approach based on SFCN. Furthermore, we allow more general and challenging input, such as mixed datasets of different categories of shapes} which can prove the ability of our generalisation. In our approach, SFCNs are trained triangles-to-triangles by using three low-level geometric features as input. Finally, the feature voting-based multi-label graph cuts is adopted to optimise the segmentation results obtained by SFCN prediction. The experiment results show that our method can effectively learn and predict mixed shape datasets of either similar or different characteristics, and achieve excellent segmentation results.
* We update some missing references about intrinsic CNNs (2018.5.24)
Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55
Oct 27, 2017
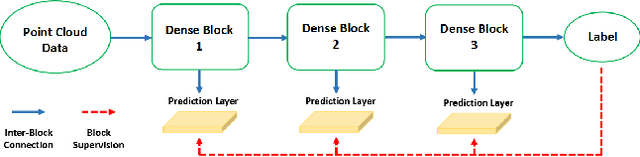
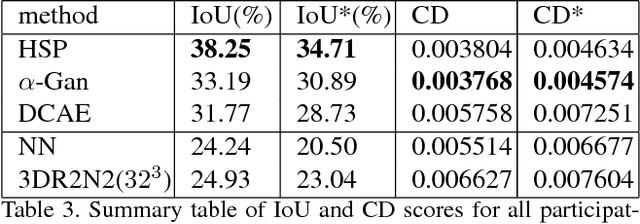
We introduce a large-scale 3D shape understanding benchmark using data and annotation from ShapeNet 3D object database. The benchmark consists of two tasks: part-level segmentation of 3D shapes and 3D reconstruction from single view images. Ten teams have participated in the challenge and the best performing teams have outperformed state-of-the-art approaches on both tasks. A few novel deep learning architectures have been proposed on various 3D representations on both tasks. We report the techniques used by each team and the corresponding performances. In addition, we summarize the major discoveries from the reported results and possible trends for the future work in the field.