 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClueTracer: Question-to-Vision Clue Tracing for Training-Free Hallucination Suppression in Multimodal Reasoning
Feb 02, 2026Large multimodal reasoning models solve challenging visual problems via explicit long-chain inference: they gather visual clues from images and decode clues into textual tokens. Yet this capability also increases hallucinations, where the model generates content that is not supported by the input image or the question. To understand this failure mode, we identify \emph{reasoning drift}: during clue gathering, the model over-focuses on question-irrelevant entities, diluting focus on task-relevant cues and gradually decoupling the reasoning trace from visual grounding. As a consequence, many inference-time localization or intervention methods developed for non-reasoning models fail to pinpoint the true clues in reasoning settings. Motivated by these insights, we introduce ClueRecall, a metric for assessing visual clue retrieval, and present ClueTracer, a training-free, parameter-free, and architecture-agnostic plugin for hallucination suppression. ClueTracer starts from the question and traces how key clues propagate along the model's reasoning pathway (question $\rightarrow$ outputs $\rightarrow$ visual tokens), thereby localizing task-relevant patches while suppressing spurious attention to irrelevant regions. Remarkably, \textbf{without any additional training}, ClueTracer improves all \textbf{reasoning} architectures (including \texttt{R1-OneVision}, \texttt{Ocean-R1}, \texttt{MM-Eureka}, \emph{etc}.) by $\mathbf{1.21\times}$ on reasoning benchmarks. When transferred to \textbf{non-reasoning} settings, it yields a $\mathbf{1.14\times}$ gain.
Deep Search with Hierarchical Meta-Cognitive Monitoring Inspired by Cognitive Neuroscience
Jan 30, 2026Deep search agents powered by large language models have demonstrated strong capabilities in multi-step retrieval, reasoning, and long-horizon task execution. However, their practical failures often stem from the lack of mechanisms to monitor and regulate reasoning and retrieval states as tasks evolve under uncertainty. Insights from cognitive neuroscience suggest that human metacognition is hierarchically organized, integrating fast anomaly detection with selectively triggered, experience-driven reflection. In this work, we propose Deep Search with Meta-Cognitive Monitoring (DS-MCM), a deep search framework augmented with an explicit hierarchical metacognitive monitoring mechanism. DS-MCM integrates a Fast Consistency Monitor, which performs lightweight checks on the alignment between external evidence and internal reasoning confidence, and a Slow Experience-Driven Monitor, which is selectively activated to guide corrective intervention based on experience memory from historical agent trajectories. By embedding monitoring directly into the reasoning-retrieval loop, DS-MCM determines both when intervention is warranted and how corrective actions should be informed by prior experience. Experiments across multiple deep search benchmarks and backbone models demonstrate that DS-MCM consistently improves performance and robustness.
Streaming Hallucination Detection in Long Chain-of-Thought Reasoning
Jan 05, 2026Long chain-of-thought (CoT) reasoning improves the performance of large language models, yet hallucinations in such settings often emerge subtly and propagate across reasoning steps. We suggest that hallucination in long CoT reasoning is better understood as an evolving latent state rather than a one-off erroneous event. Accordingly, we treat step-level hallucination judgments as local observations and introduce a cumulative prefix-level hallucination signal that tracks the global evolution of the reasoning state over the entire trajectory. Overall, our approach enables streaming hallucination detection in long CoT reasoning, providing real-time, interpretable evidence.
Advancing LLM-Based Security Automation with Customized Group Relative Policy Optimization for Zero-Touch Networks
Dec 10, 2025Zero-Touch Networks (ZTNs) represent a transformative paradigm toward fully automated and intelligent network management, providing the scalability and adaptability required for the complexity of sixth-generation (6G) networks. However, the distributed architecture, high openness, and deep heterogeneity of 6G networks expand the attack surface and pose unprecedented security challenges. To address this, security automation aims to enable intelligent security management across dynamic and complex environments, serving as a key capability for securing 6G ZTNs. Despite its promise, implementing security automation in 6G ZTNs presents two primary challenges: 1) automating the lifecycle from security strategy generation to validation and update under real-world, parallel, and adversarial conditions, and 2) adapting security strategies to evolving threats and dynamic environments. This motivates us to propose SecLoop and SA-GRPO. SecLoop constitutes the first fully automated framework that integrates large language models (LLMs) across the entire lifecycle of security strategy generation, orchestration, response, and feedback, enabling intelligent and adaptive defenses in dynamic network environments, thus tackling the first challenge. Furthermore, we propose SA-GRPO, a novel security-aware group relative policy optimization algorithm that iteratively refines security strategies by contrasting group feedback collected from parallel SecLoop executions, thereby addressing the second challenge. Extensive real-world experiments on five benchmarks, including 11 MITRE ATT&CK processes and over 20 types of attacks, demonstrate the superiority of the proposed SecLoop and SA-GRPO. We will release our platform to the community, facilitating the advancement of security automation towards next generation communications.
KGMark: A Diffusion Watermark for Knowledge Graphs
May 29, 2025Knowledge graphs (KGs) are ubiquitous in numerous real-world applications, and watermarking facilitates protecting intellectual property and preventing potential harm from AI-generated content. Existing watermarking methods mainly focus on static plain text or image data, while they can hardly be applied to dynamic graphs due to spatial and temporal variations of structured data. This motivates us to propose KGMARK, the first graph watermarking framework that aims to generate robust, detectable, and transparent diffusion fingerprints for dynamic KG data. Specifically, we propose a novel clustering-based alignment method to adapt the watermark to spatial variations. Meanwhile, we present a redundant embedding strategy to harden the diffusion watermark against various attacks, facilitating the robustness of the watermark to the temporal variations. Additionally, we introduce a novel learnable mask matrix to improve the transparency of diffusion fingerprints. By doing so, our KGMARK properly tackles the variation challenges of structured data. Experiments on various public benchmarks show the effectiveness of our proposed KGMARK.
Advancing Expert Specialization for Better MoE
May 28, 2025

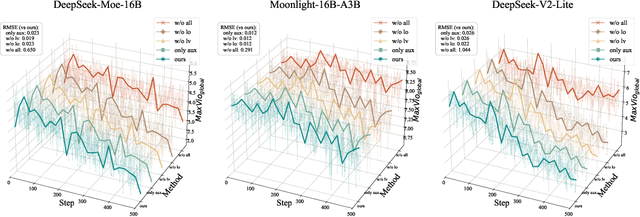

Mixture-of-Experts (MoE) models enable efficient scaling of large language models (LLMs) by activating only a subset of experts per input. However, we observe that the commonly used auxiliary load balancing loss often leads to expert overlap and overly uniform routing, which hinders expert specialization and degrades overall performance during post-training. To address this, we propose a simple yet effective solution that introduces two complementary objectives: (1) an orthogonality loss to encourage experts to process distinct types of tokens, and (2) a variance loss to encourage more discriminative routing decisions. Gradient-level analysis demonstrates that these objectives are compatible with the existing auxiliary loss and contribute to optimizing the training process. Experimental results over various model architectures and across multiple benchmarks show that our method significantly enhances expert specialization. Notably, our method improves classic MoE baselines with auxiliary loss by up to 23.79%, while also maintaining load balancing in downstream tasks, without any architectural modifications or additional components. We will release our code to contribute to the community.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
MALSIGHT: Exploring Malicious Source Code and Benign Pseudocode for Iterative Binary Malware Summarization
Jun 26, 2024Binary malware summarization aims to automatically generate human-readable descriptions of malware behaviors from executable files, facilitating tasks like malware cracking and detection. Previous methods based on Large Language Models (LLMs) have shown great promise. However, they still face significant issues, including poor usability, inaccurate explanations, and incomplete summaries, primarily due to the obscure pseudocode structure and the lack of malware training summaries. Further, calling relationships between functions, which involve the rich interactions within a binary malware, remain largely underexplored. To this end, we propose MALSIGHT, a novel code summarization framework that can iteratively generate descriptions of binary malware by exploring malicious source code and benign pseudocode. Specifically, we construct the first malware summaries, MalS and MalP, using an LLM and manually refine this dataset with human effort. At the training stage, we tune our proposed MalT5, a novel LLM-based code model, on the MalS dataset and a benign pseudocode dataset. Then, at the test stage, we iteratively feed the pseudocode functions into MalT5 to obtain the summary. Such a procedure facilitates the understanding of pseudocode structure and captures the intricate interactions between functions, thereby benefiting the usability, accuracy, and completeness of summaries. Additionally, we propose a novel evaluation benchmark, BLEURT-sum, to measure the quality of summaries. Experiments on three datasets show the effectiveness of the proposed MALSIGHT. Notably, our proposed MalT5, with only 0.77B parameters, delivers comparable performance to much larger ChatGPT3.5.