 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Dual-Path Framework for Covert Semantic Communication
May 05, 2026This paper proposes a novel adaptive dual-path framework for covert semantic communication (SemCom), which integrates covert information transmission with task-oriented semantic coding. Unlike conventional covert communication methods that embed hidden messages through power-domain signal superposition, our framework embeds covert data within task-specific features via semantic-level intrinsic encoding. This new architecture introduces dual encoding paths with adaptive block selection: an Explicit path for public task execution and a Stego path that jointly encodes both public and covert information through contrastive representation alignment. A Gumbel-Softmax enabled adaptive path selection mechanism dynamically activates network blocks based on task require- ments. We formulate a multi-objective optimization framework that simultaneously ensures accurate semantic understanding and reliable covert transmission. We rigorously evaluate our framework's security against a powerful, independently trained attacker. Experimental results on the Cityscapes dataset demon- strate a state-of-the-art level of covertness: our method suppresses the attacker's detection accuracy to a near-random guessing level of 56.12%. This robust security is achieved while simultaneously maintaining superior performance on the primary semantic tasks compared to the baselines.
Joint Routing and Model Pruning for Decentralized Federated Learning in Bandwidth-Constrained Multi-Hop Wireless Networks
Mar 16, 2026Decentralized federated learning (D-FL) enables privacy-preserving training without a central server, but multi-hop model exchanges and aggregation are often bottlenecked by communication resource constraints. To address this issue, we propose a joint routing-and-pruning framework that optimizes routing paths and pruning rates to maintain communication latency within prescribed limits. We analyze how the sum of model biases across all clients affects the convergence bound of D-FL and formulate an optimization problem that maximizes the model retention rate to minimize these biases under communication constraints. Further analysis reveals that each client's model retention rate is path-dependent, which reduces the original problem to a routing optimization. Leveraging this insight, we develop a routing algorithm that selects latency-efficient transmission paths, allowing more parameters to be delivered within the time budget and thereby improving D-FL convergence. Simulations demonstrate that, compared with unpruned systems, the proposed framework reduces average transmission latency by 27.8% and improves testing accuracy by approximately 12%. Furthermore, relative to standard benchmark routing algorithms, the proposed routing method improves accuracy by roughly 8%.
Convergence-Privacy-Fairness Trade-Off in Personalized Federated Learning
Jun 17, 2025Personalized federated learning (PFL), e.g., the renowned Ditto, strikes a balance between personalization and generalization by conducting federated learning (FL) to guide personalized learning (PL). While FL is unaffected by personalized model training, in Ditto, PL depends on the outcome of the FL. However, the clients' concern about their privacy and consequent perturbation of their local models can affect the convergence and (performance) fairness of PL. This paper presents PFL, called DP-Ditto, which is a non-trivial extension of Ditto under the protection of differential privacy (DP), and analyzes the trade-off among its privacy guarantee, model convergence, and performance distribution fairness. We also analyze the convergence upper bound of the personalized models under DP-Ditto and derive the optimal number of global aggregations given a privacy budget. Further, we analyze the performance fairness of the personalized models, and reveal the feasibility of optimizing DP-Ditto jointly for convergence and fairness. Experiments validate our analysis and demonstrate that DP-Ditto can surpass the DP-perturbed versions of the state-of-the-art PFL models, such as FedAMP, pFedMe, APPLE, and FedALA, by over 32.71% in fairness and 9.66% in accuracy.
Free Privacy Protection for Wireless Federated Learning: Enjoy It or Suffer from It?
Jun 15, 2025Inherent communication noises have the potential to preserve privacy for wireless federated learning (WFL) but have been overlooked in digital communication systems predominantly using floating-point number standards, e.g., IEEE 754, for data storage and transmission. This is due to the potentially catastrophic consequences of bit errors in floating-point numbers, e.g., on the sign or exponent bits. This paper presents a novel channel-native bit-flipping differential privacy (DP) mechanism tailored for WFL, where transmit bits are randomly flipped and communication noises are leveraged, to collectively preserve the privacy of WFL in digital communication systems. The key idea is to interpret the bit perturbation at the transmitter and bit errors caused by communication noises as a bit-flipping DP process. This is achieved by designing a new floating-point-to-fixed-point conversion method that only transmits the bits in the fraction part of model parameters, hence eliminating the need for transmitting the sign and exponent bits and preventing the catastrophic consequence of bit errors. We analyze a new metric to measure the bit-level distance of the model parameters and prove that the proposed mechanism satisfies (\lambda,\epsilon)-R\'enyi DP and does not violate the WFL convergence. Experiments validate privacy and convergence analysis of the proposed mechanism and demonstrate its superiority to the state-of-the-art Gaussian mechanisms that are channel-agnostic and add Gaussian noise for privacy protection.
Subspace-Based Super-Resolution Sensing for Bi-Static ISAC with Clock Asynchronism
May 15, 2025Bi-static sensing is an attractive configuration for integrated sensing and communications (ISAC) systems; however, clock asynchronism between widely separated transmitters and receivers introduces time-varying time offsets (TO) and phase offsets (PO), posing significant challenges. This paper introduces a signal-subspace-based framework that estimates decoupled angles, delays, and complex gain sequences (CGS)-- the target-reflected signals -- for multiple dynamic target paths. The proposed framework begins with a novel TO alignment algorithm, leveraging signal subspace or covariance, to mitigate TO variations across temporal snapshots, enabling coherent delay-domain analysis. Subsequently, subspace-based methods are developed to compensate for TO residuals and to perform joint angle-delay estimation. Finally, leveraging the high resolution in the joint angle-delay domain, the framework compensates for the PO and estimates the CGS for each target. The framework can be applied to both single-antenna and multi-antenna systems. Extensive simulations and experiments using commercial Wi-Fi devices demonstrate that the proposed framework significantly surpasses existing solutions in parameter estimation accuracy and delay resolution. Notably, it uniquely achieves a super-resolution in the delay domain, with a probability-of-resolution curve tightly approaching that in synchronized systems.
Multi-Task Semantic Communication With Graph Attention-Based Feature Correlation Extraction
Jan 02, 2025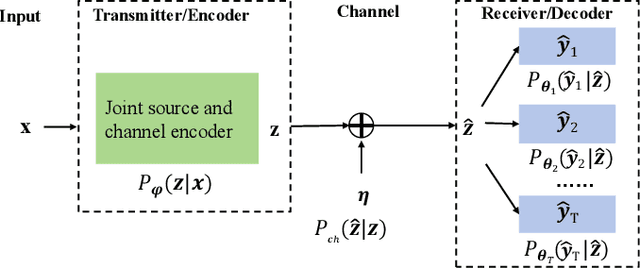
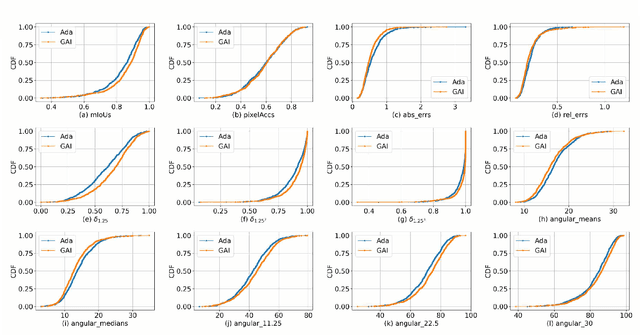
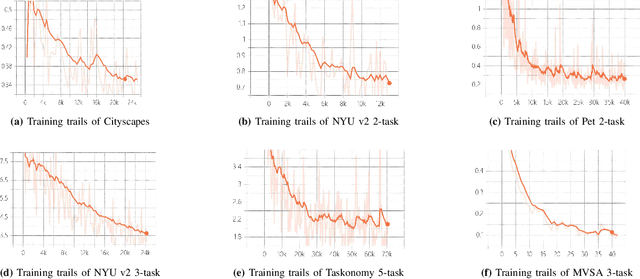
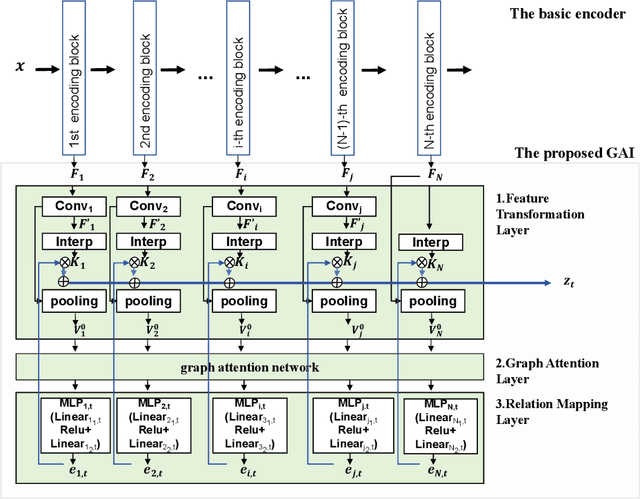
Multi-task semantic communication can serve multiple learning tasks using a shared encoder model. Existing models have overlooked the intricate relationships between features extracted during an encoding process of tasks. This paper presents a new graph attention inter-block (GAI) module to the encoder/transmitter of a multi-task semantic communication system, which enriches the features for multiple tasks by embedding the intermediate outputs of encoding in the features, compared to the existing techniques. The key idea is that we interpret the outputs of the intermediate feature extraction blocks of the encoder as the nodes of a graph to capture the correlations of the intermediate features. Another important aspect is that we refine the node representation using a graph attention mechanism to extract the correlations and a multi-layer perceptron network to associate the node representations with different tasks. Consequently, the intermediate features are weighted and embedded into the features transmitted for executing multiple tasks at the receiver. Experiments demonstrate that the proposed model surpasses the most competitive and publicly available models by 11.4% on the CityScapes 2Task dataset and outperforms the established state-of-the-art by 3.97% on the NYU V2 3Task dataset, respectively, when the bandwidth ratio of the communication channel (i.e., compression level for transmission over the channel) is as constrained as 1 12 .
Decentralized Federated Learning Over Imperfect Communication Channels
May 21, 2024This paper analyzes the impact of imperfect communication channels on decentralized federated learning (D-FL) and subsequently determines the optimal number of local aggregations per training round, adapting to the network topology and imperfect channels. We start by deriving the bias of locally aggregated D-FL models under imperfect channels from the ideal global models requiring perfect channels and aggregations. The bias reveals that excessive local aggregations can accumulate communication errors and degrade convergence. Another important aspect is that we analyze a convergence upper bound of D-FL based on the bias. By minimizing the bound, the optimal number of local aggregations is identified to balance a trade-off with accumulation of communication errors in the absence of knowledge of the channels. With this knowledge, the impact of communication errors can be alleviated, allowing the convergence upper bound to decrease throughout aggregations. Experiments validate our convergence analysis and also identify the optimal number of local aggregations on two widely considered image classification tasks. It is seen that D-FL, with an optimal number of local aggregations, can outperform its potential alternatives by over 10% in training accuracy.
Performance Bounds for Passive Sensing in Asynchronous ISAC Systems -- Appendices
Mar 09, 2024This document contains the appendices for our paper titled ``Performance Bounds for Passive Sensing in Asynchronous ISAC Systems." The appendices include rigorous derivations of key formulas, detailed proofs of the theorems and propositions introduced in the paper, and details of the algorithm tested in the numerical simulation for validation. These appendices aim to support and elaborate on the findings and methodologies presented in the main text. All external references to equations, theorems, and so forth, are directed towards the corresponding elements within the main paper.
Multi-Carrier NOMA-Empowered Wireless Federated Learning with Optimal Power and Bandwidth Allocation
Feb 13, 2023



Wireless federated learning (WFL) undergoes a communication bottleneck in uplink, limiting the number of users that can upload their local models in each global aggregation round. This paper presents a new multi-carrier non-orthogonal multiple-access (MC-NOMA)-empowered WFL system under an adaptive learning setting of Flexible Aggregation. Since a WFL round accommodates both local model training and uploading for each user, the use of Flexible Aggregation allows the users to train different numbers of iterations per round, adapting to their channel conditions and computing resources. The key idea is to use MC-NOMA to concurrently upload the local models of the users, thereby extending the local model training times of the users and increasing participating users. A new metric, namely, Weighted Global Proportion of Trained Mini-batches (WGPTM), is analytically established to measure the convergence of the new system. Another important aspect is that we maximize the WGPTM to harness the convergence of the new system by jointly optimizing the transmit powers and subchannel bandwidths. This nonconvex problem is converted equivalently to a tractable convex problem and solved efficiently using variable substitution and Cauchy's inequality. As corroborated experimentally using a convolutional neural network and an 18-layer residential network, the proposed MC-NOMA WFL can efficiently reduce communication delay, increase local model training times, and accelerate the convergence by over 40%, compared to its existing alternative.