 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace-Based Super-Resolution Sensing for Bi-Static ISAC with Clock Asynchronism
May 15, 2025Bi-static sensing is an attractive configuration for integrated sensing and communications (ISAC) systems; however, clock asynchronism between widely separated transmitters and receivers introduces time-varying time offsets (TO) and phase offsets (PO), posing significant challenges. This paper introduces a signal-subspace-based framework that estimates decoupled angles, delays, and complex gain sequences (CGS)-- the target-reflected signals -- for multiple dynamic target paths. The proposed framework begins with a novel TO alignment algorithm, leveraging signal subspace or covariance, to mitigate TO variations across temporal snapshots, enabling coherent delay-domain analysis. Subsequently, subspace-based methods are developed to compensate for TO residuals and to perform joint angle-delay estimation. Finally, leveraging the high resolution in the joint angle-delay domain, the framework compensates for the PO and estimates the CGS for each target. The framework can be applied to both single-antenna and multi-antenna systems. Extensive simulations and experiments using commercial Wi-Fi devices demonstrate that the proposed framework significantly surpasses existing solutions in parameter estimation accuracy and delay resolution. Notably, it uniquely achieves a super-resolution in the delay domain, with a probability-of-resolution curve tightly approaching that in synchronized systems.
3D Extended Object Tracking by Fusing Roadside Sparse Radar Point Clouds and Pixel Keypoints
Apr 27, 2024



Roadside perception is a key component in intelligent transportation systems. In this paper, we present a novel three-dimensional (3D) extended object tracking (EOT) method, which simultaneously estimates the object kinematics and extent state, in roadside perception using both the radar and camera data. Because of the influence of sensor viewing angle and limited angle resolution, radar measurements from objects are sparse and non-uniformly distributed, leading to inaccuracies in object extent and position estimation. To address this problem, we present a novel spherical Gaussian function weighted Gaussian mixture model. This model assumes that radar measurements originate from a series of probabilistic weighted radar reflectors on the vehicle's extent. Additionally, we utilize visual detection of vehicle keypoints to provide additional information on the positions of radar reflectors. Since keypoints may not always correspond to radar reflectors, we propose an elastic skeleton fusion mechanism, which constructs a virtual force to establish the relationship between the radar reflectors on the vehicle and its extent. Furthermore, to better describe the kinematic state of the vehicle and constrain its extent state, we develop a new 3D constant turn rate and velocity motion model, considering the complex 3D motion of the vehicle relative to the roadside sensor. Finally, we apply variational Bayesian approximation to the intractable measurement update step to enable recursive Bayesian estimation of the object's state. Simulation results using the Carla simulator and experimental results on the nuScenes dataset demonstrate the effectiveness and superiority of the proposed method in comparison to several state-of-the-art 3D EOT methods.
Performance Bounds for Passive Sensing in Asynchronous ISAC Systems -- Appendices
Mar 09, 2024This document contains the appendices for our paper titled ``Performance Bounds for Passive Sensing in Asynchronous ISAC Systems." The appendices include rigorous derivations of key formulas, detailed proofs of the theorems and propositions introduced in the paper, and details of the algorithm tested in the numerical simulation for validation. These appendices aim to support and elaborate on the findings and methodologies presented in the main text. All external references to equations, theorems, and so forth, are directed towards the corresponding elements within the main paper.
Joint Vehicular Localization and Reflective Mapping Based on Team Channel-SLAM
Jan 30, 2022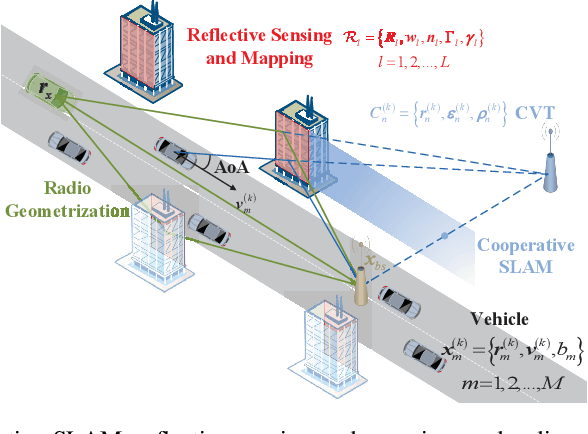
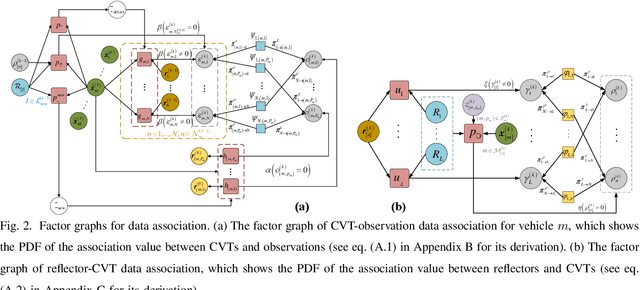
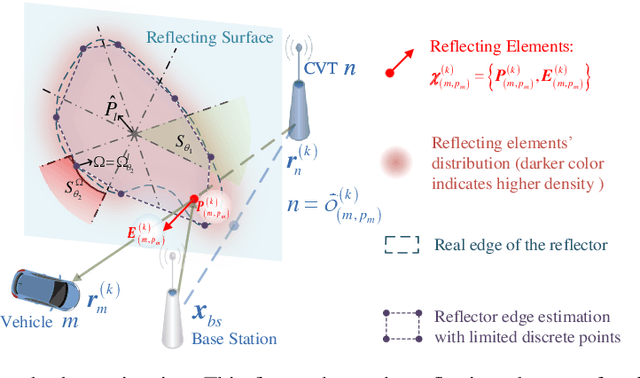
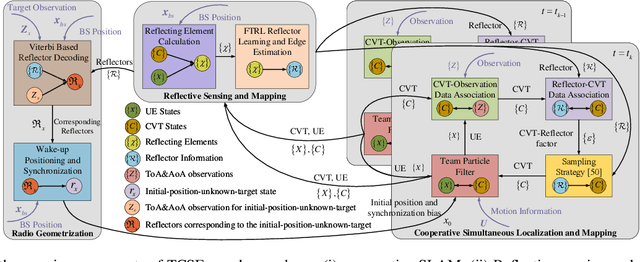
This paper addresses high-resolution vehicle positioning and tracking. In recent work, it was shown that a fleet of independent but neighboring vehicles can cooperate for the task of localization by capitalizing on the existence of common surrounding reflectors, using the concept of Team Channel-SLAM. This approach exploits an initial (e.g. GPS-based) vehicle position information and allows subsequent tracking of vehicles by exploiting the shared nature of virtual transmitters associated to the reflecting surfaces. In this paper, we show that the localization can be greatly enhanced by joint sensing and mapping of reflecting surfaces. To this end, we propose a combined approach coined Team Channel-SLAM Evolution (TCSE) which exploits the intertwined relation between (i) the position of virtual transmitters, (ii) the shape of reflecting surfaces, and (iii) the paths described by the radio propagation rays, in order to achieve high-resolution vehicle localization. Overall, TCSE yields a complete picture of the trajectories followed by dominant paths together with a mapping of reflecting surfaces. While joint localization and mapping is a well researched topic within robotics using inputs such as radar and vision, this paper is first to demonstrate such an approach within mobile networking framework based on radio data.
Leveraging Multiple Legacy Wi-Fi Links for Human Behavior Sensing
Aug 02, 2021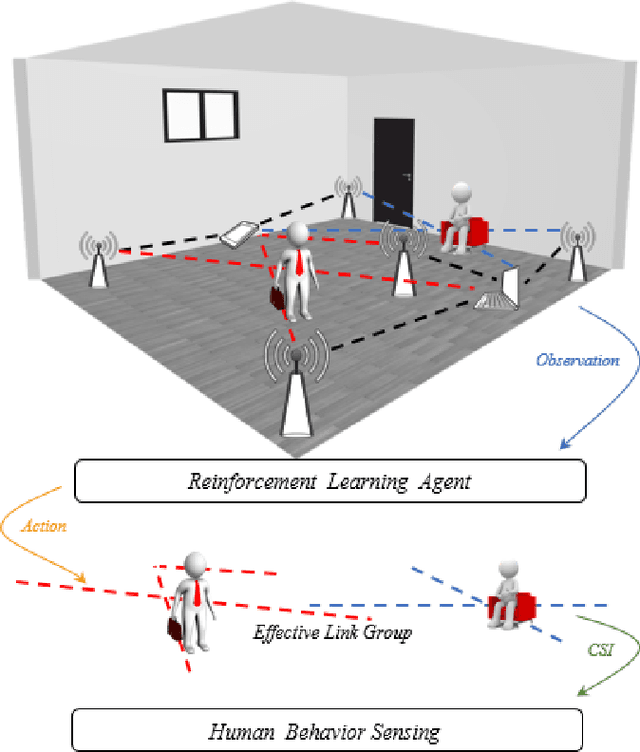
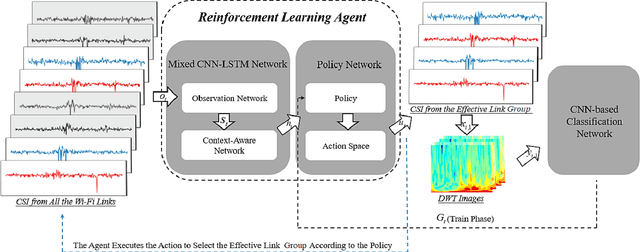

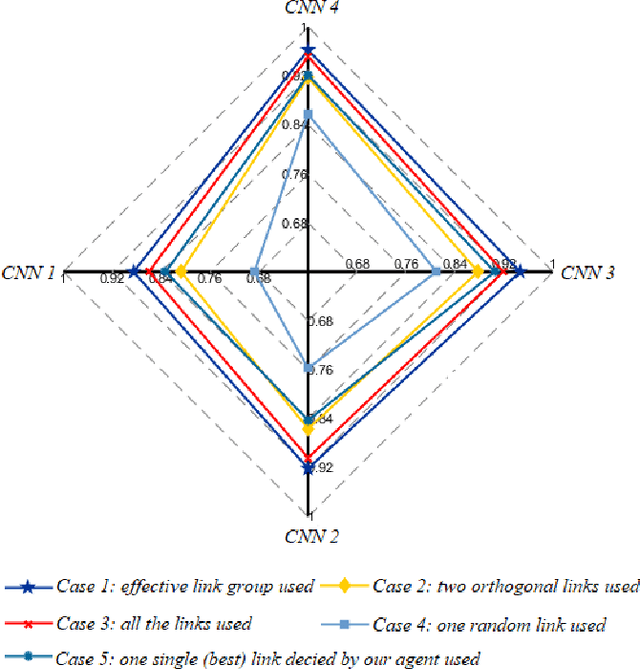
Taking advantage of the rich information provided by Wi-Fi measurement setups, Wi-Fi-based human behavior sensing leveraging Channel State Information (CSI) measurements has received a lot of research attention in recent years. The CSI-based human sensing algorithms typically either rely on an explicit channel propagation model or, more recently, adopt machine learning so as to robustify feature extraction. In most related work, the considered CSI is extracted from a single dedicated Access Point (AP) communication setup. In this paper, we consider a more realistic setting where a legacy network of multiple APs is already deployed for communications purposes and leveraged for sensing benefits using machine learning. The use of legacy network presents challenges and opportunities as many Wi-Fi links can present with richer yet unequally useful data sets. In order to break the curse of dimensionality associated with training over a too large dimensional CSI, we propose a link selection mechanism based on Reinforcement Learning (RL) which allows for dimension reduction while preserving the data that is most relevant for human behavior sensing. The method is based on a sequential state decision-making process in which the CSI is modeled as a part of the state. From actual experiment results, our method is shown to perform better than state-of-the-art approaches in a scenario with multiple available Wi-Fi links.
Vehicle Localization via Cooperative Channel Mapping
Feb 09, 2021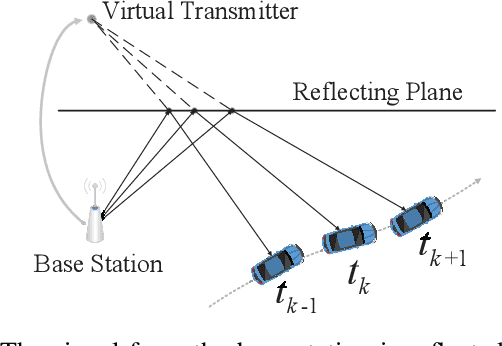

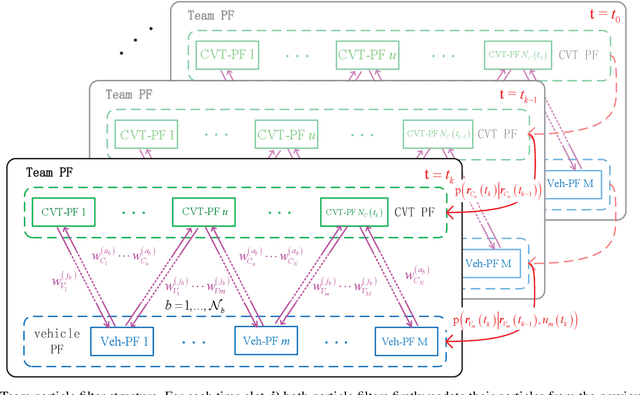
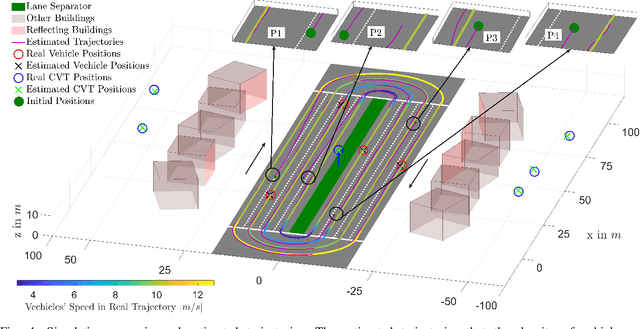
This paper addresses vehicle positioning, a topic whose importance has risen dramatically in the context of future autonomous driving systems. While classical methods that use GPS and/or beacon signals from network infrastructure for triangulation tend to be sensitive to multi-paths and signal obstruction, our method exhibits robustness with respect to such phenomena. Our approach builds on the recently proposed Channel-SLAM method which first enabled leveraging of multi-path so as to improve (single) vehicle positioning. Here, we propose a cooperative mapping approach which builds upon the Channel-SLAM concept, referred to here as Team Channel-SLAM. Team Channel-SLAM not only exploits the stationary nature of many reflecting objects around the vehicle, but also capitalizes on the multi-vehicle nature of road traffic. The key intuition behind our method is the exploitation for the first time of the correlation between reflectors around multiple neighboring vehicles. An algorithm is derived for reflector selection and estimation, combined with a team particle filter (TPF) so as to achieve high precision simultaneous multiple vehicle positioning. We obtain large improvement over the single-vehicle positioning scenario, with gains being already noticeable for moderate vehicle densities, such as over 40% improvement for a vehicle density as low as 4 vehicles in 132 meters' length road.
From Point to Space: 3D Moving Human Pose Estimation Using Commodity WiFi
Dec 28, 2020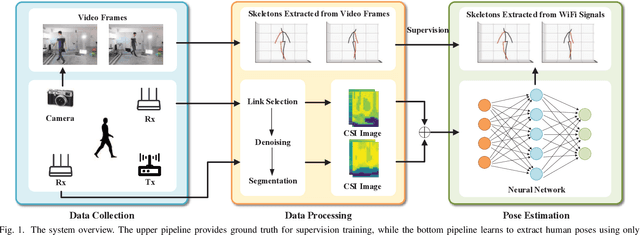

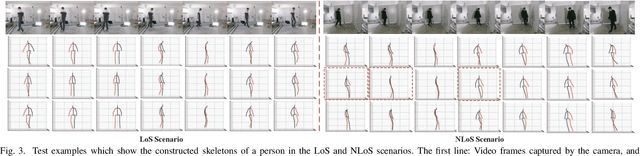
In this paper, we present Wi-Mose, the first 3D moving human pose estimation system using commodity WiFi. Previous WiFi-based works have achieved 2D and 3D pose estimation. These solutions either capture poses from one perspective or construct poses of people who are at a fixed point, preventing their wide adoption in daily scenarios. To reconstruct 3D poses of people who move throughout the space rather than a fixed point, we fuse the amplitude and phase into Channel State Information (CSI) images which can provide both pose and position information. Besides, we design a neural network to extract features that are only associated with poses from CSI images and then convert the features into key-point coordinates. Experimental results show that Wi-Mose can localize key-point with 29.7mm and 37.8mm Procrustes analysis Mean Per Joint Position Error (P-MPJPE) in the Line of Sight (LoS) and Non-Line of Sight (NLoS) scenarios, respectively, achieving higher performance than the state-of-the-art method. The results indicate that Wi-Mose can capture high-precision 3D human poses throughout the space.
Subject-independent Human Pose Image Construction with Commodity Wi-Fi
Dec 22, 2020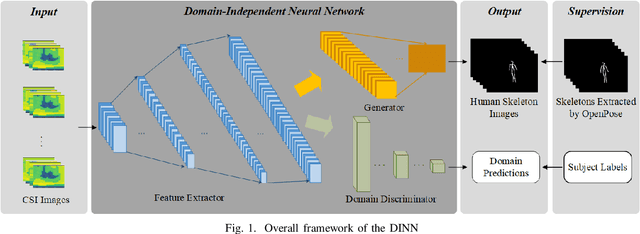

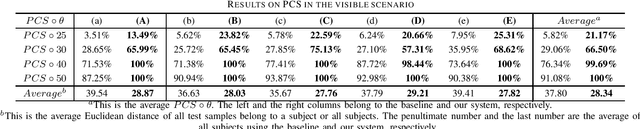
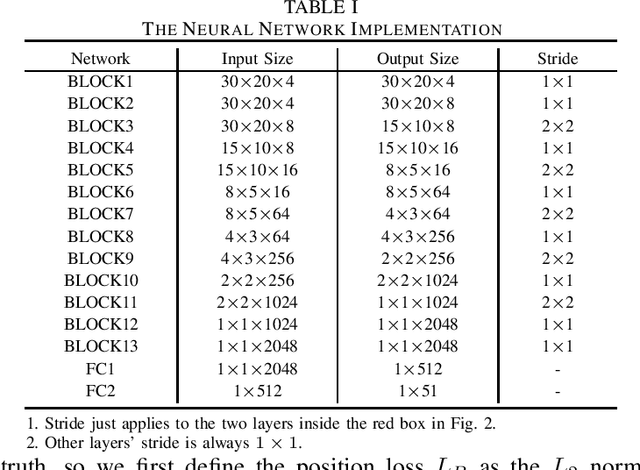
Recently, commodity Wi-Fi devices have been shown to be able to construct human pose images, i.e., human skeletons, as fine-grained as cameras. Existing papers achieve good results when constructing the images of subjects who are in the prior training samples. However, the performance drops when it comes to new subjects, i.e., the subjects who are not in the training samples. This paper focuses on solving the subject-generalization problem in human pose image construction. To this end, we define the subject as the domain. Then we design a Domain-Independent Neural Network (DINN) to extract subject-independent features and convert them into fine-grained human pose images. We also propose a novel training method to train the DINN and it has no re-training overhead comparing with the domain-adversarial approach. We build a prototype system and experimental results demonstrate that our system can construct fine-grained human pose images of new subjects with commodity Wi-Fi in both the visible and through-wall scenarios, which shows the effectiveness and the subject-generalization ability of our model.
When Healthcare Meets Off-the-Shelf WiFi: A Non-Wearable and Low-Costs Approach for In-Home Monitoring
Sep 21, 2020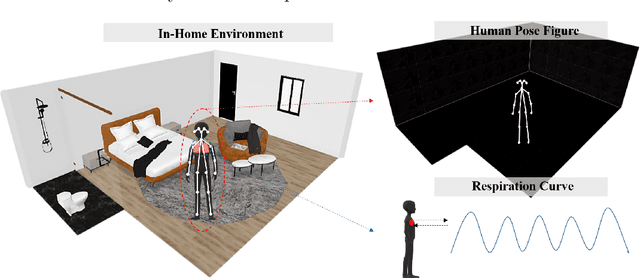
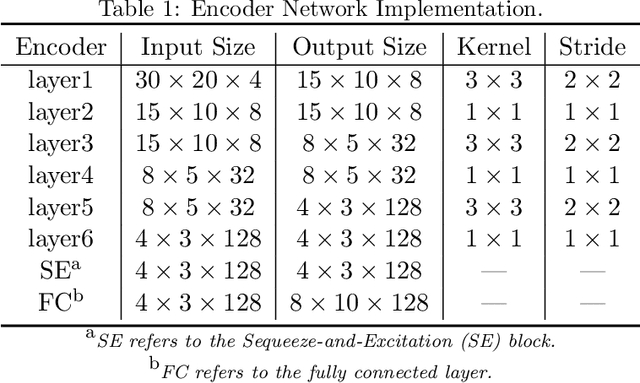


As elderly population grows, social and health care begin to face validation challenges, in-home monitoring is becoming a focus for professionals in the field. Governments urgently need to improve the quality of healthcare services at lower costs while ensuring the comfort and independence of the elderly. This work presents an in-home monitoring approach based on off-the-shelf WiFi, which is low-costs, non-wearable and makes all-round daily healthcare information available to caregivers. The proposed approach can capture fine-grained human pose figures even through a wall and track detailed respiration status simultaneously by off-the-shelf WiFi devices. Based on them, behavioral data, physiological data and the derived information (e.g., abnormal events and underlying diseases), of the elderly could be seen by caregivers directly. We design a series of signal processing methods and a neural network to capture human pose figures and extract respiration status curves from WiFi Channel State Information (CSI). Extensive experiments are conducted and according to the results, off-the-shelf WiFi devices are capable of capturing fine-grained human pose figures, similar to cameras, even through a wall and track accurate respiration status, thus demonstrating the effectiveness and feasibility of our approach for in-home monitoring.