 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap Between Ideal and Real-world Evaluation: Benchmarking AI-Generated Image Detection in Challenging Scenarios
Sep 11, 2025



With the rapid advancement of generative models, highly realistic image synthesis has posed new challenges to digital security and media credibility. Although AI-generated image detection methods have partially addressed these concerns, a substantial research gap remains in evaluating their performance under complex real-world conditions. This paper introduces the Real-World Robustness Dataset (RRDataset) for comprehensive evaluation of detection models across three dimensions: 1) Scenario Generalization: RRDataset encompasses high-quality images from seven major scenarios (War and Conflict, Disasters and Accidents, Political and Social Events, Medical and Public Health, Culture and Religion, Labor and Production, and everyday life), addressing existing dataset gaps from a content perspective. 2) Internet Transmission Robustness: examining detector performance on images that have undergone multiple rounds of sharing across various social media platforms. 3) Re-digitization Robustness: assessing model effectiveness on images altered through four distinct re-digitization methods. We benchmarked 17 detectors and 10 vision-language models (VLMs) on RRDataset and conducted a large-scale human study involving 192 participants to investigate human few-shot learning capabilities in detecting AI-generated images. The benchmarking results reveal the limitations of current AI detection methods under real-world conditions and underscore the importance of drawing on human adaptability to develop more robust detection algorithms.
Online Prompt Pricing based on Combinatorial Multi-Armed Bandit and Hierarchical Stackelberg Game
May 24, 2024


Generation models have shown promising performance in various tasks, making trading around machine learning models possible. In this paper, we aim at a novel prompt trading scenario, prompt bundle trading (PBT) system, and propose an online pricing mechanism. Based on the combinatorial multi-armed bandit (CMAB) and three-stage hierarchical Stackelburg (HS) game, our pricing mechanism considers the profits of the consumer, platform, and seller, simultaneously achieving the profit satisfaction of these three participants. We break down the pricing issue into two steps, namely unknown category selection and incentive strategy optimization. The former step is to select a set of categories with the highest qualities, and the latter is to derive the optimal strategy for each participant based on the chosen categories. Unlike the existing fixed pricing mode, the PBT pricing mechanism we propose is more flexible and diverse, which is more in accord with the transaction needs of real-world scenarios. We test our method on a simulated text-to-image dataset. The experimental results demonstrate the effectiveness of our algorithm, which provides a feasible price-setting standard for the prompt marketplaces.
Regeneration Based Training-free Attribution of Fake Images Generated by Text-to-Image Generative Models
Mar 03, 2024



Text-to-image generative models have recently garnered significant attention due to their ability to generate images based on prompt descriptions. While these models have shown promising performance, concerns have been raised regarding the potential misuse of the generated fake images. In response to this, we have presented a simple yet effective training-free method to attribute fake images generated by text-to-image models to their source models. Given a test image to be attributed, we first inverse the textual prompt of the image, and then put the reconstructed prompt into different candidate models to regenerate candidate fake images. By calculating and ranking the similarity of the test image and the candidate images, we can determine the source of the image. This attribution allows model owners to be held accountable for any misuse of their models. Note that our approach does not limit the number of candidate text-to-image generative models. Comprehensive experiments reveal that (1) Our method can effectively attribute fake images to their source models, achieving comparable attribution performance with the state-of-the-art method; (2) Our method has high scalability ability, which is well adapted to real-world attribution scenarios. (3) The proposed method yields satisfactory robustness to common attacks, such as Gaussian blurring, JPEG compression, and Resizing. We also analyze the factors that influence the attribution performance, and explore the boost brought by the proposed method as a plug-in to improve the performance of existing SOTA. We hope our work can shed some light on the solutions to addressing the source of AI-generated images, as well as to prevent the misuse of text-to-image generative models.
Object-oriented backdoor attack against image captioning
Jan 05, 2024



Backdoor attack against image classification task has been widely studied and proven to be successful, while there exist little research on the backdoor attack against vision-language models. In this paper, we explore backdoor attack towards image captioning models by poisoning training data. Assuming the attacker has total access to the training dataset, and cannot intervene in model construction or training process. Specifically, a portion of benign training samples is randomly selected to be poisoned. Afterwards, considering that the captions are usually unfolded around objects in an image, we design an object-oriented method to craft poisons, which aims to modify pixel values by a slight range with the modification number proportional to the scale of the current detected object region. After training with the poisoned data, the attacked model behaves normally on benign images, but for poisoned images, the model will generate some sentences irrelevant to the given image. The attack controls the model behavior on specific test images without sacrificing the generation performance on benign test images. Our method proves the weakness of image captioning models to backdoor attack and we hope this work can raise the awareness of defending against backdoor attack in the image captioning field.
Towards Deep Network Steganography: From Networks to Networks
Jul 07, 2023With the widespread applications of the deep neural network (DNN), how to covertly transmit the DNN models in public channels brings us the attention, especially for those trained for secret-learning tasks. In this paper, we propose deep network steganography for the covert communication of DNN models. Unlike the existing steganography schemes which focus on the subtle modification of the cover data to accommodate the secrets, our scheme is learning task oriented, where the learning task of the secret DNN model (termed as secret-learning task) is disguised into another ordinary learning task conducted in a stego DNN model (termed as stego-learning task). To this end, we propose a gradient-based filter insertion scheme to insert interference filters into the important positions in the secret DNN model to form a stego DNN model. These positions are then embedded into the stego DNN model using a key by side information hiding. Finally, we activate the interference filters by a partial optimization strategy, such that the generated stego DNN model works on the stego-learning task. We conduct the experiments on both the intra-task steganography and inter-task steganography (i.e., the secret and stego-learning tasks belong to the same and different categories), both of which demonstrate the effectiveness of our proposed method for covert communication of DNN models.
Steganography of Steganographic Networks
Feb 28, 2023Steganography is a technique for covert communication between two parties. With the rapid development of deep neural networks (DNN), more and more steganographic networks are proposed recently, which are shown to be promising to achieve good performance. Unlike the traditional handcrafted steganographic tools, a steganographic network is relatively large in size. It raises concerns on how to covertly transmit the steganographic network in public channels, which is a crucial stage in the pipeline of steganography in real world applications. To address such an issue, we propose a novel scheme for steganography of steganographic networks in this paper. Unlike the existing steganographic schemes which focus on the subtle modification of the cover data to accommodate the secrets. We propose to disguise a steganographic network (termed as the secret DNN model) into a stego DNN model which performs an ordinary machine learning task (termed as the stego task). During the model disguising, we select and tune a subset of filters in the secret DNN model to preserve its function on the secret task, where the remaining filters are reactivated according to a partial optimization strategy to disguise the whole secret DNN model into a stego DNN model. The secret DNN model can be recovered from the stego DNN model when needed. Various experiments have been conducted to demonstrate the advantage of our proposed method for covert communication of steganographic networks as well as general DNN models.
Exploring Depth Information for Face Manipulation Detection
Dec 29, 2022Face manipulation detection has been receiving a lot of attention for the reliability and security of the face images. Recent studies focus on using auxiliary information or prior knowledge to capture robust manipulation traces, which are shown to be promising. As one of the important face features, the face depth map, which has shown to be effective in other areas such as the face recognition or face detection, is unfortunately paid little attention to in literature for detecting the manipulated face images. In this paper, we explore the possibility of incorporating the face depth map as auxiliary information to tackle the problem of face manipulation detection in real world applications. To this end, we first propose a Face Depth Map Transformer (FDMT) to estimate the face depth map patch by patch from a RGB face image, which is able to capture the local depth anomaly created due to manipulation. The estimated face depth map is then considered as auxiliary information to be integrated with the backbone features using a Multi-head Depth Attention (MDA) mechanism that is newly designed. Various experiments demonstrate the advantage of our proposed method for face manipulation detection.
Joint Vehicular Localization and Reflective Mapping Based on Team Channel-SLAM
Jan 30, 2022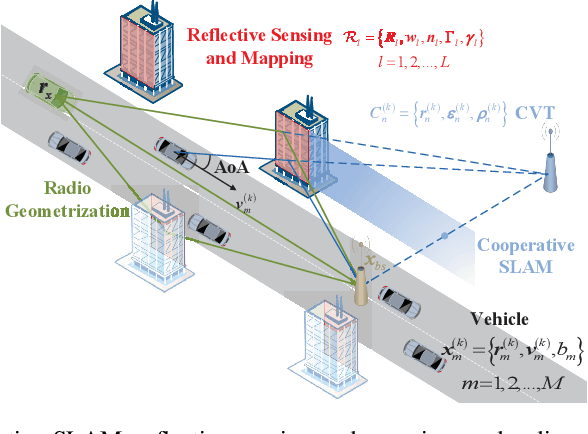
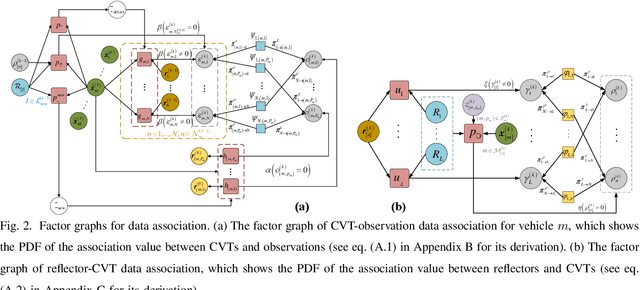
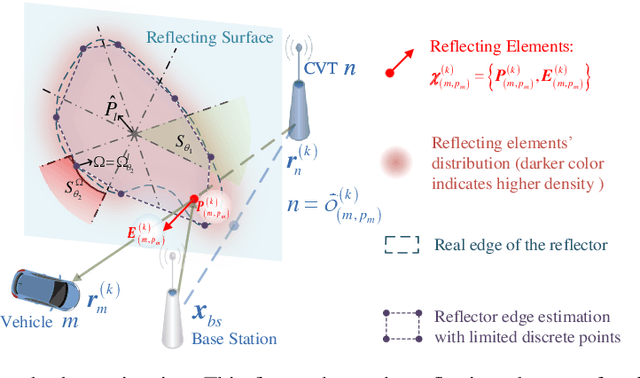
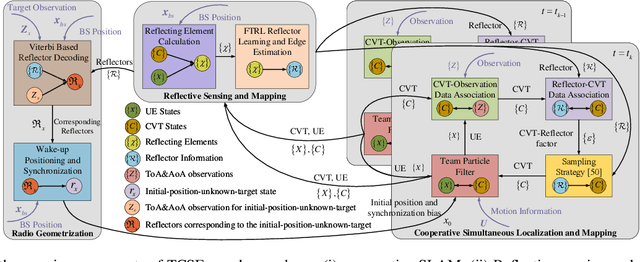
This paper addresses high-resolution vehicle positioning and tracking. In recent work, it was shown that a fleet of independent but neighboring vehicles can cooperate for the task of localization by capitalizing on the existence of common surrounding reflectors, using the concept of Team Channel-SLAM. This approach exploits an initial (e.g. GPS-based) vehicle position information and allows subsequent tracking of vehicles by exploiting the shared nature of virtual transmitters associated to the reflecting surfaces. In this paper, we show that the localization can be greatly enhanced by joint sensing and mapping of reflecting surfaces. To this end, we propose a combined approach coined Team Channel-SLAM Evolution (TCSE) which exploits the intertwined relation between (i) the position of virtual transmitters, (ii) the shape of reflecting surfaces, and (iii) the paths described by the radio propagation rays, in order to achieve high-resolution vehicle localization. Overall, TCSE yields a complete picture of the trajectories followed by dominant paths together with a mapping of reflecting surfaces. While joint localization and mapping is a well researched topic within robotics using inputs such as radar and vision, this paper is first to demonstrate such an approach within mobile networking framework based on radio data.