 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor Matters: Demosaicing-Guided Color Correlation Training for Generalizable AI-Generated Image Detection
Jan 30, 2026As realistic AI-generated images threaten digital authenticity, we address the generalization failure of generative artifact-based detectors by exploiting the intrinsic properties of the camera imaging pipeline. Concretely, we investigate color correlations induced by the color filter array (CFA) and demosaicing, and propose a Demosaicing-guided Color Correlation Training (DCCT) framework for AI-generated image detection. By simulating the CFA sampling pattern, we decompose each color image into a single-channel input (as the condition) and the remaining two channels as the ground-truth targets (for prediction). A self-supervised U-Net is trained to model the conditional distribution of the missing channels from the given one, parameterized via a mixture of logistic functions. Our theoretical analysis reveals that DCCT targets a provable distributional difference in color-correlation features between photographic and AI-generated images. By leveraging these distinct features to construct a binary classifier, DCCT achieves state-of-the-art generalization and robustness, significantly outperforming prior methods across over 20 unseen generators.
Bi-Level Optimization for Self-Supervised AI-Generated Face Detection
Jul 30, 2025



AI-generated face detectors trained via supervised learning typically rely on synthesized images from specific generators, limiting their generalization to emerging generative techniques. To overcome this limitation, we introduce a self-supervised method based on bi-level optimization. In the inner loop, we pretrain a vision encoder only on photographic face images using a set of linearly weighted pretext tasks: classification of categorical exchangeable image file format (EXIF) tags, ranking of ordinal EXIF tags, and detection of artificial face manipulations. The outer loop then optimizes the relative weights of these pretext tasks to enhance the coarse-grained detection of manipulated faces, serving as a proxy task for identifying AI-generated faces. In doing so, it aligns self-supervised learning more closely with the ultimate goal of AI-generated face detection. Once pretrained, the encoder remains fixed, and AI-generated faces are detected either as anomalies under a Gaussian mixture model fitted to photographic face features or by a lightweight two-layer perceptron serving as a binary classifier. Extensive experiments demonstrate that our detectors significantly outperform existing approaches in both one-class and binary classification settings, exhibiting strong generalization to unseen generators.
Revocable Backdoor for Deep Model Trading
Aug 01, 2024



Deep models are being applied in numerous fields and have become a new important digital product. Meanwhile, previous studies have shown that deep models are vulnerable to backdoor attacks, in which compromised models return attacker-desired results when a trigger appears. Backdoor attacks severely break the trust-worthiness of deep models. In this paper, we turn this weakness of deep models into a strength, and propose a novel revocable backdoor and deep model trading scenario. Specifically, we aim to compromise deep models without degrading their performance, meanwhile, we can easily detoxify poisoned models without re-training the models. We design specific mask matrices to manage the internal feature maps of the models. These mask matrices can be used to deactivate the backdoors. The revocable backdoor can be adopted in the deep model trading scenario. Sellers train models with revocable backdoors as a trial version. Buyers pay a deposit to sellers and obtain a trial version of the deep model. If buyers are satisfied with the trial version, they pay a final payment to sellers and sellers send mask matrices to buyers to withdraw revocable backdoors. We demonstrate the feasibility and robustness of our revocable backdoor by various datasets and network architectures.
Object-oriented backdoor attack against image captioning
Jan 05, 2024



Backdoor attack against image classification task has been widely studied and proven to be successful, while there exist little research on the backdoor attack against vision-language models. In this paper, we explore backdoor attack towards image captioning models by poisoning training data. Assuming the attacker has total access to the training dataset, and cannot intervene in model construction or training process. Specifically, a portion of benign training samples is randomly selected to be poisoned. Afterwards, considering that the captions are usually unfolded around objects in an image, we design an object-oriented method to craft poisons, which aims to modify pixel values by a slight range with the modification number proportional to the scale of the current detected object region. After training with the poisoned data, the attacked model behaves normally on benign images, but for poisoned images, the model will generate some sentences irrelevant to the given image. The attack controls the model behavior on specific test images without sacrificing the generation performance on benign test images. Our method proves the weakness of image captioning models to backdoor attack and we hope this work can raise the awareness of defending against backdoor attack in the image captioning field.
Rich and Poor Texture Contrast: A Simple yet Effective Approach for AI-generated Image Detection
Nov 21, 2023Recent generative models show impressive performance in generating photographic images. Humans can hardly distinguish such incredibly realistic-looking AI-generated images from real ones. AI-generated images may lead to ubiquitous disinformation dissemination. Therefore, it is of utmost urgency to develop a detector to identify AI-generated images. Most existing detectors suffer from sharp performance drops over unseen generative models. In this paper, we propose a novel AI-generated image detector capable of identifying fake images created by a wide range of generative models. Our approach leverages the inter-pixel correlation contrast between rich and poor texture regions within an image. Pixels in rich texture regions exhibit more significant fluctuations than those in poor texture regions. This discrepancy reflects that the entropy of rich texture regions is larger than that of poor ones. Consequently, synthesizing realistic rich texture regions proves to be more challenging for existing generative models. Based on this principle, we divide an image into multiple patches and reconstruct them into two images, comprising rich-texture and poor-texture patches respectively. Subsequently, we extract the inter-pixel correlation discrepancy feature between rich and poor texture regions. This feature serves as a universal fingerprint used for AI-generated image forensics across different generative models. In addition, we build a comprehensive AI-generated image detection benchmark, which includes 16 kinds of prevalent generative models, to evaluate the effectiveness of existing baselines and our approach. Our benchmark provides a leaderboard for follow-up studies. Extensive experimental results show that our approach outperforms state-of-the-art baselines by a significant margin. Our project: https://fdmas.github.io/AIGCDetect/
Physical Invisible Backdoor Based on Camera Imaging
Sep 14, 2023Backdoor attack aims to compromise a model, which returns an adversary-wanted output when a specific trigger pattern appears yet behaves normally for clean inputs. Current backdoor attacks require changing pixels of clean images, which results in poor stealthiness of attacks and increases the difficulty of the physical implementation. This paper proposes a novel physical invisible backdoor based on camera imaging without changing nature image pixels. Specifically, a compromised model returns a target label for images taken by a particular camera, while it returns correct results for other images. To implement and evaluate the proposed backdoor, we take shots of different objects from multi-angles using multiple smartphones to build a new dataset of 21,500 images. Conventional backdoor attacks work ineffectively with some classical models, such as ResNet18, over the above-mentioned dataset. Therefore, we propose a three-step training strategy to mount the backdoor attack. First, we design and train a camera identification model with the phone IDs to extract the camera fingerprint feature. Subsequently, we elaborate a special network architecture, which is easily compromised by our backdoor attack, by leveraging the attributes of the CFA interpolation algorithm and combining it with the feature extraction block in the camera identification model. Finally, we transfer the backdoor from the elaborated special network architecture to the classical architecture model via teacher-student distillation learning. Since the trigger of our method is related to the specific phone, our attack works effectively in the physical world. Experiment results demonstrate the feasibility of our proposed approach and robustness against various backdoor defenses.
Imperceptible Backdoor Attack: From Input Space to Feature Representation
May 06, 2022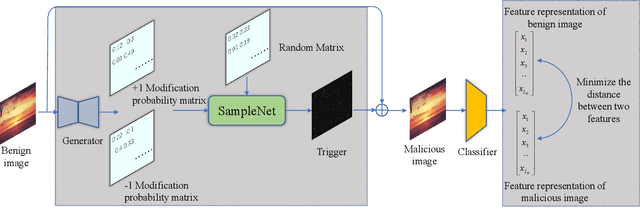

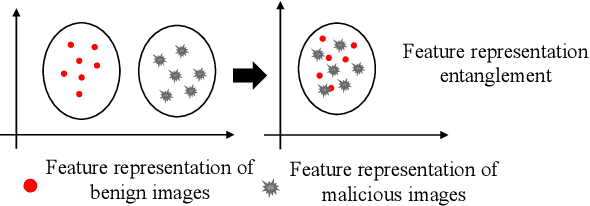
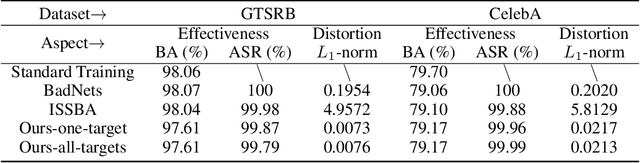
Backdoor attacks are rapidly emerging threats to deep neural networks (DNNs). In the backdoor attack scenario, attackers usually implant the backdoor into the target model by manipulating the training dataset or training process. Then, the compromised model behaves normally for benign input yet makes mistakes when the pre-defined trigger appears. In this paper, we analyze the drawbacks of existing attack approaches and propose a novel imperceptible backdoor attack. We treat the trigger pattern as a special kind of noise following a multinomial distribution. A U-net-based network is employed to generate concrete parameters of multinomial distribution for each benign input. This elaborated trigger ensures that our approach is invisible to both humans and statistical detection. Besides the design of the trigger, we also consider the robustness of our approach against model diagnose-based defences. We force the feature representation of malicious input stamped with the trigger to be entangled with the benign one. We demonstrate the effectiveness and robustness against multiple state-of-the-art defences through extensive datasets and networks. Our trigger only modifies less than 1\% pixels of a benign image while the modification magnitude is 1. Our source code is available at https://github.com/Ekko-zn/IJCAI2022-Backdoor.