 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor Matters: Demosaicing-Guided Color Correlation Training for Generalizable AI-Generated Image Detection
Jan 30, 2026As realistic AI-generated images threaten digital authenticity, we address the generalization failure of generative artifact-based detectors by exploiting the intrinsic properties of the camera imaging pipeline. Concretely, we investigate color correlations induced by the color filter array (CFA) and demosaicing, and propose a Demosaicing-guided Color Correlation Training (DCCT) framework for AI-generated image detection. By simulating the CFA sampling pattern, we decompose each color image into a single-channel input (as the condition) and the remaining two channels as the ground-truth targets (for prediction). A self-supervised U-Net is trained to model the conditional distribution of the missing channels from the given one, parameterized via a mixture of logistic functions. Our theoretical analysis reveals that DCCT targets a provable distributional difference in color-correlation features between photographic and AI-generated images. By leveraging these distinct features to construct a binary classifier, DCCT achieves state-of-the-art generalization and robustness, significantly outperforming prior methods across over 20 unseen generators.
SIN-Bench: Tracing Native Evidence Chains in Long-Context Multimodal Scientific Interleaved Literature
Jan 15, 2026Evaluating whether multimodal large language models truly understand long-form scientific papers remains challenging: answer-only metrics and synthetic "Needle-In-A-Haystack" tests often reward answer matching without requiring a causal, evidence-linked reasoning trace in the document. We propose the "Fish-in-the-Ocean" (FITO) paradigm, which requires models to construct explicit cross-modal evidence chains within native scientific documents. To operationalize FITO, we build SIN-Data, a scientific interleaved corpus that preserves the native interleaving of text and figures. On top of it, we construct SIN-Bench with four progressive tasks covering evidence discovery (SIN-Find), hypothesis verification (SIN-Verify), grounded QA (SIN-QA), and evidence-anchored synthesis (SIN-Summary). We further introduce "No Evidence, No Score", scoring predictions when grounded to verifiable anchors and diagnosing evidence quality via matching, relevance, and logic. Experiments on eight MLLMs show that grounding is the primary bottleneck: Gemini-3-pro achieves the best average overall score (0.573), while GPT-5 attains the highest SIN-QA answer accuracy (0.767) but underperforms on evidence-aligned overall scores, exposing a gap between correctness and traceable support.
DuetSVG: Unified Multimodal SVG Generation with Internal Visual Guidance
Dec 11, 2025Recent vision-language model (VLM)-based approaches have achieved impressive results on SVG generation. However, because they generate only text and lack visual signals during decoding, they often struggle with complex semantics and fail to produce visually appealing or geometrically coherent SVGs. We introduce DuetSVG, a unified multimodal model that jointly generates image tokens and corresponding SVG tokens in an end-to-end manner. DuetSVG is trained on both image and SVG datasets. At inference, we apply a novel test-time scaling strategy that leverages the model's native visual predictions as guidance to improve SVG decoding quality. Extensive experiments show that our method outperforms existing methods, producing visually faithful, semantically aligned, and syntactically clean SVGs across a wide range of applications.
Flash-Splat: 3D Reflection Removal with Flash Cues and Gaussian Splats
Oct 03, 2024We introduce a simple yet effective approach for separating transmitted and reflected light. Our key insight is that the powerful novel view synthesis capabilities provided by modern inverse rendering methods (e.g.,~3D Gaussian splatting) allow one to perform flash/no-flash reflection separation using unpaired measurements -- this relaxation dramatically simplifies image acquisition over conventional paired flash/no-flash reflection separation methods. Through extensive real-world experiments, we demonstrate our method, Flash-Splat, accurately reconstructs both transmitted and reflected scenes in 3D. Our method outperforms existing 3D reflection separation methods, which do not leverage illumination control, by a large margin. Our project webpage is at https://flash-splat.github.io/.
Anno-incomplete Multi-dataset Detection
Aug 29, 2024

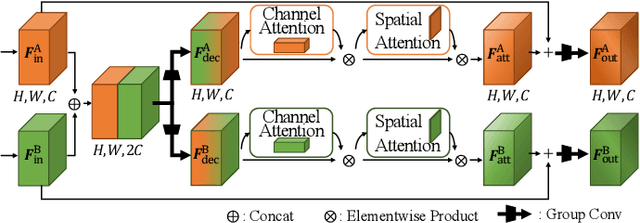
Object detectors have shown outstanding performance on various public datasets. However, annotating a new dataset for a new task is usually unavoidable in real, since 1) a single existing dataset usually does not contain all object categories needed; 2) using multiple datasets usually suffers from annotation incompletion and heterogeneous features. We propose a novel problem as "Annotation-incomplete Multi-dataset Detection", and develop an end-to-end multi-task learning architecture which can accurately detect all the object categories with multiple partially annotated datasets. Specifically, we propose an attention feature extractor which helps to mine the relations among different datasets. Besides, a knowledge amalgamation training strategy is incorporated to accommodate heterogeneous features from different sources. Extensive experiments on different object detection datasets demonstrate the effectiveness of our methods and an improvement of 2.17%, 2.10% in mAP can be achieved on COCO and VOC respectively.
Revocable Backdoor for Deep Model Trading
Aug 01, 2024Deep models are being applied in numerous fields and have become a new important digital product. Meanwhile, previous studies have shown that deep models are vulnerable to backdoor attacks, in which compromised models return attacker-desired results when a trigger appears. Backdoor attacks severely break the trust-worthiness of deep models. In this paper, we turn this weakness of deep models into a strength, and propose a novel revocable backdoor and deep model trading scenario. Specifically, we aim to compromise deep models without degrading their performance, meanwhile, we can easily detoxify poisoned models without re-training the models. We design specific mask matrices to manage the internal feature maps of the models. These mask matrices can be used to deactivate the backdoors. The revocable backdoor can be adopted in the deep model trading scenario. Sellers train models with revocable backdoors as a trial version. Buyers pay a deposit to sellers and obtain a trial version of the deep model. If buyers are satisfied with the trial version, they pay a final payment to sellers and sellers send mask matrices to buyers to withdraw revocable backdoors. We demonstrate the feasibility and robustness of our revocable backdoor by various datasets and network architectures.
VideoGigaGAN: Towards Detail-rich Video Super-Resolution
Apr 18, 2024

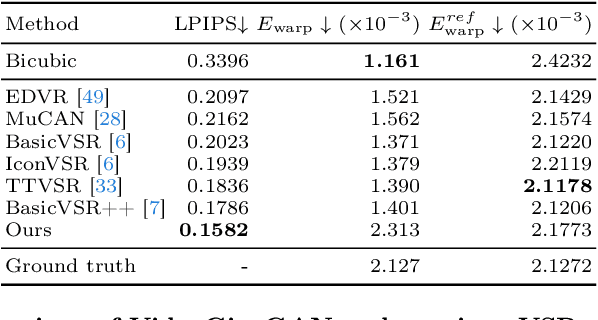

Video super-resolution (VSR) approaches have shown impressive temporal consistency in upsampled videos. However, these approaches tend to generate blurrier results than their image counterparts as they are limited in their generative capability. This raises a fundamental question: can we extend the success of a generative image upsampler to the VSR task while preserving the temporal consistency? We introduce VideoGigaGAN, a new generative VSR model that can produce videos with high-frequency details and temporal consistency. VideoGigaGAN builds upon a large-scale image upsampler -- GigaGAN. Simply inflating GigaGAN to a video model by adding temporal modules produces severe temporal flickering. We identify several key issues and propose techniques that significantly improve the temporal consistency of upsampled videos. Our experiments show that, unlike previous VSR methods, VideoGigaGAN generates temporally consistent videos with more fine-grained appearance details. We validate the effectiveness of VideoGigaGAN by comparing it with state-of-the-art VSR models on public datasets and showcasing video results with $8\times$ super-resolution.
Rich and Poor Texture Contrast: A Simple yet Effective Approach for AI-generated Image Detection
Nov 21, 2023Recent generative models show impressive performance in generating photographic images. Humans can hardly distinguish such incredibly realistic-looking AI-generated images from real ones. AI-generated images may lead to ubiquitous disinformation dissemination. Therefore, it is of utmost urgency to develop a detector to identify AI-generated images. Most existing detectors suffer from sharp performance drops over unseen generative models. In this paper, we propose a novel AI-generated image detector capable of identifying fake images created by a wide range of generative models. Our approach leverages the inter-pixel correlation contrast between rich and poor texture regions within an image. Pixels in rich texture regions exhibit more significant fluctuations than those in poor texture regions. This discrepancy reflects that the entropy of rich texture regions is larger than that of poor ones. Consequently, synthesizing realistic rich texture regions proves to be more challenging for existing generative models. Based on this principle, we divide an image into multiple patches and reconstruct them into two images, comprising rich-texture and poor-texture patches respectively. Subsequently, we extract the inter-pixel correlation discrepancy feature between rich and poor texture regions. This feature serves as a universal fingerprint used for AI-generated image forensics across different generative models. In addition, we build a comprehensive AI-generated image detection benchmark, which includes 16 kinds of prevalent generative models, to evaluate the effectiveness of existing baselines and our approach. Our benchmark provides a leaderboard for follow-up studies. Extensive experimental results show that our approach outperforms state-of-the-art baselines by a significant margin. Our project: https://fdmas.github.io/AIGCDetect/
Boosting Fair Classifier Generalization through Adaptive Priority Reweighing
Sep 30, 2023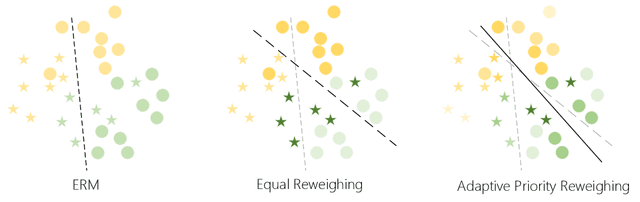
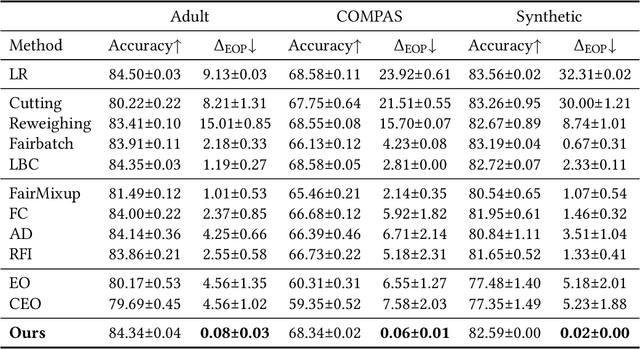
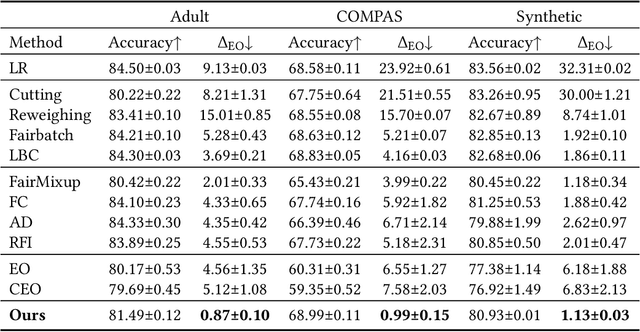
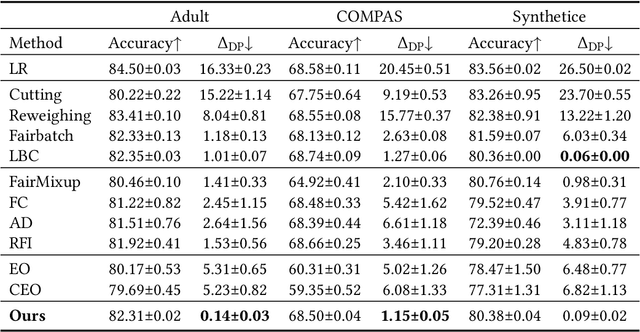
With the increasing penetration of machine learning applications in critical decision-making areas, calls for algorithmic fairness are more prominent. Although there have been various modalities to improve algorithmic fairness through learning with fairness constraints, their performance does not generalize well in the test set. A performance-promising fair algorithm with better generalizability is needed. This paper proposes a novel adaptive reweighing method to eliminate the impact of the distribution shifts between training and test data on model generalizability. Most previous reweighing methods propose to assign a unified weight for each (sub)group. Rather, our method granularly models the distance from the sample predictions to the decision boundary. Our adaptive reweighing method prioritizes samples closer to the decision boundary and assigns a higher weight to improve the generalizability of fair classifiers. Extensive experiments are performed to validate the generalizability of our adaptive priority reweighing method for accuracy and fairness measures (i.e., equal opportunity, equalized odds, and demographic parity) in tabular benchmarks. We also highlight the performance of our method in improving the fairness of language and vision models. The code is available at https://github.com/che2198/APW.
Dynamic Mesh-Aware Radiance Fields
Sep 08, 2023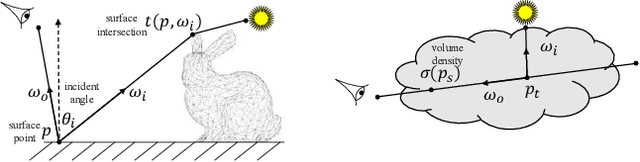



Embedding polygonal mesh assets within photorealistic Neural Radience Fields (NeRF) volumes, such that they can be rendered and their dynamics simulated in a physically consistent manner with the NeRF, is under-explored from the system perspective of integrating NeRF into the traditional graphics pipeline. This paper designs a two-way coupling between mesh and NeRF during rendering and simulation. We first review the light transport equations for both mesh and NeRF, then distill them into an efficient algorithm for updating radiance and throughput along a cast ray with an arbitrary number of bounces. To resolve the discrepancy between the linear color space that the path tracer assumes and the sRGB color space that standard NeRF uses, we train NeRF with High Dynamic Range (HDR) images. We also present a strategy to estimate light sources and cast shadows on the NeRF. Finally, we consider how the hybrid surface-volumetric formulation can be efficiently integrated with a high-performance physics simulator that supports cloth, rigid and soft bodies. The full rendering and simulation system can be run on a GPU at interactive rates. We show that a hybrid system approach outperforms alternatives in visual realism for mesh insertion, because it allows realistic light transport from volumetric NeRF media onto surfaces, which affects the appearance of reflective/refractive surfaces and illumination of diffuse surfaces informed by the dynamic scene.