 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubject-independent Human Pose Image Construction with Commodity Wi-Fi
Paper and Code
Dec 22, 2020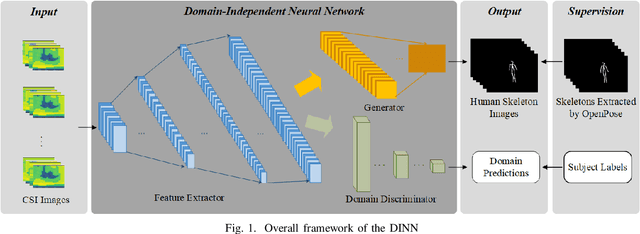

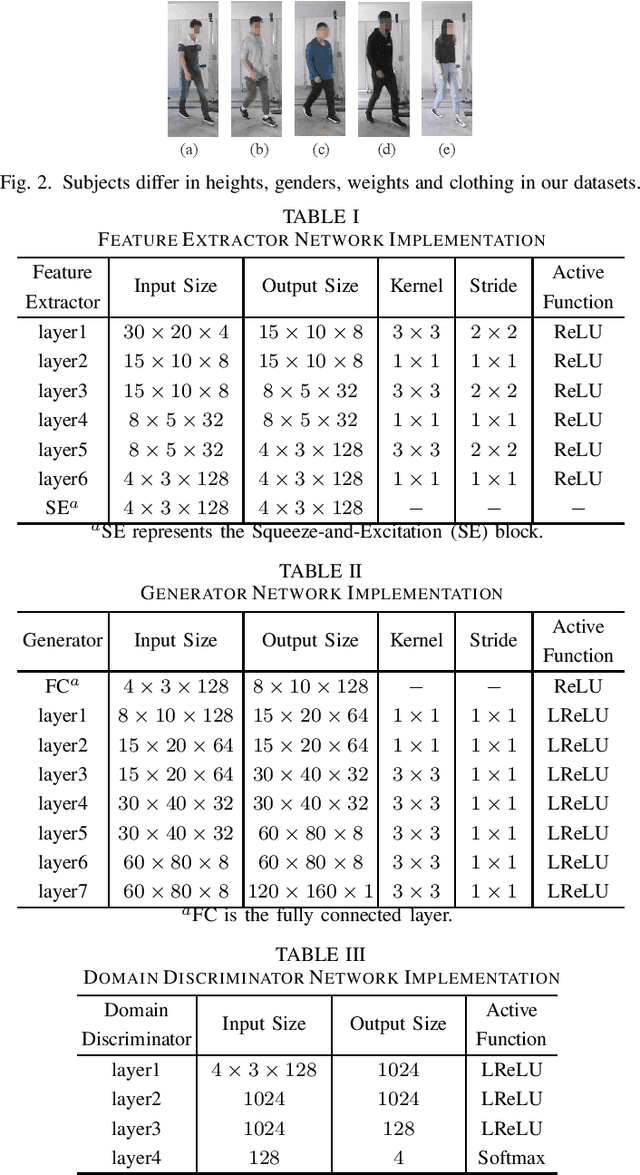
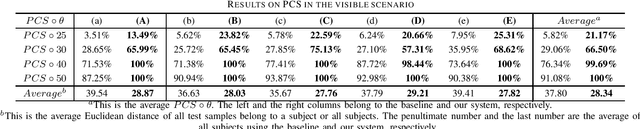
Recently, commodity Wi-Fi devices have been shown to be able to construct human pose images, i.e., human skeletons, as fine-grained as cameras. Existing papers achieve good results when constructing the images of subjects who are in the prior training samples. However, the performance drops when it comes to new subjects, i.e., the subjects who are not in the training samples. This paper focuses on solving the subject-generalization problem in human pose image construction. To this end, we define the subject as the domain. Then we design a Domain-Independent Neural Network (DINN) to extract subject-independent features and convert them into fine-grained human pose images. We also propose a novel training method to train the DINN and it has no re-training overhead comparing with the domain-adversarial approach. We build a prototype system and experimental results demonstrate that our system can construct fine-grained human pose images of new subjects with commodity Wi-Fi in both the visible and through-wall scenarios, which shows the effectiveness and the subject-generalization ability of our model.