 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVP-Recon: Progressive View Planning via Warping Consistency for Sparse-View Surface Reconstruction
Sep 09, 2024



Neural implicit representations have revolutionized dense multi-view surface reconstruction, yet their performance significantly diminishes with sparse input views. A few pioneering works have sought to tackle the challenge of sparse-view reconstruction by leveraging additional geometric priors or multi-scene generalizability. However, they are still hindered by the imperfect choice of input views, using images under empirically determined viewpoints to provide considerable overlap. We propose PVP-Recon, a novel and effective sparse-view surface reconstruction method that progressively plans the next best views to form an optimal set of sparse viewpoints for image capturing. PVP-Recon starts initial surface reconstruction with as few as 3 views and progressively adds new views which are determined based on a novel warping score that reflects the information gain of each newly added view. This progressive view planning progress is interleaved with a neural SDF-based reconstruction module that utilizes multi-resolution hash features, enhanced by a progressive training scheme and a directional Hessian loss. Quantitative and qualitative experiments on three benchmark datasets show that our framework achieves high-quality reconstruction with a constrained input budget and outperforms existing baselines.
AHPPEBot: Autonomous Robot for Tomato Harvesting based on Phenotyping and Pose Estimation
May 11, 2024



To address the limitations inherent to conventional automated harvesting robots specifically their suboptimal success rates and risk of crop damage, we design a novel bot named AHPPEBot which is capable of autonomous harvesting based on crop phenotyping and pose estimation. Specifically, In phenotyping, the detection, association, and maturity estimation of tomato trusses and individual fruits are accomplished through a multi-task YOLOv5 model coupled with a detection-based adaptive DBScan clustering algorithm. In pose estimation, we employ a deep learning model to predict seven semantic keypoints on the pedicel. These keypoints assist in the robot's path planning, minimize target contact, and facilitate the use of our specialized end effector for harvesting. In autonomous tomato harvesting experiments conducted in commercial greenhouses, our proposed robot achieved a harvesting success rate of 86.67%, with an average successful harvest time of 32.46 s, showcasing its continuous and robust harvesting capabilities. The result underscores the potential of harvesting robots to bridge the labor gap in agriculture.
FF-LOGO: Cross-Modality Point Cloud Registration with Feature Filtering and Local to Global Optimization
Sep 16, 2023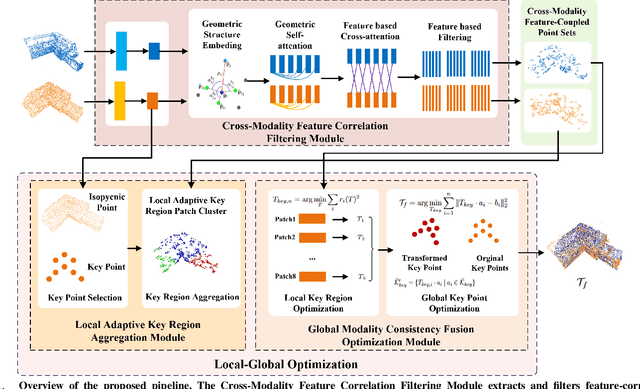
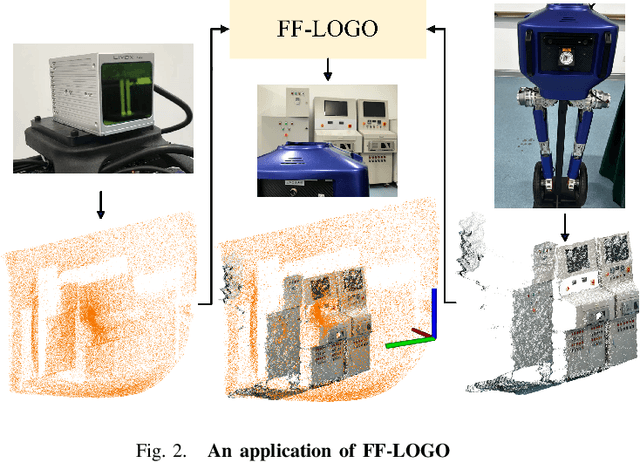
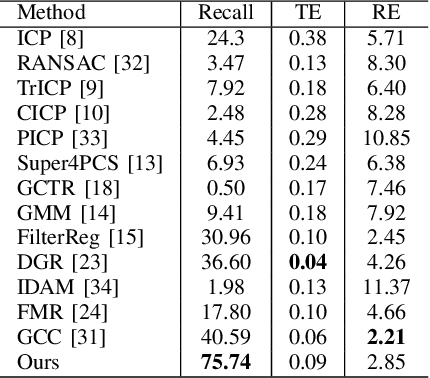
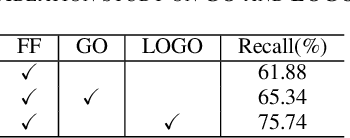
Cross-modality point cloud registration is confronted with significant challenges due to inherent differences in modalities between different sensors. We propose a cross-modality point cloud registration framework FF-LOGO: a cross-modality point cloud registration method with feature filtering and local-global optimization. The cross-modality feature correlation filtering module extracts geometric transformation-invariant features from cross-modality point clouds and achieves point selection by feature matching. We also introduce a cross-modality optimization process, including a local adaptive key region aggregation module and a global modality consistency fusion optimization module. Experimental results demonstrate that our two-stage optimization significantly improves the registration accuracy of the feature association and selection module. Our method achieves a substantial increase in recall rate compared to the current state-of-the-art methods on the 3DCSR dataset, improving from 40.59% to 75.74%. Our code will be available at https://github.com/wangmohan17/FFLOGO.
KRF: Keypoint Refinement with Fusion Network for 6D Pose Estimation
Oct 07, 2022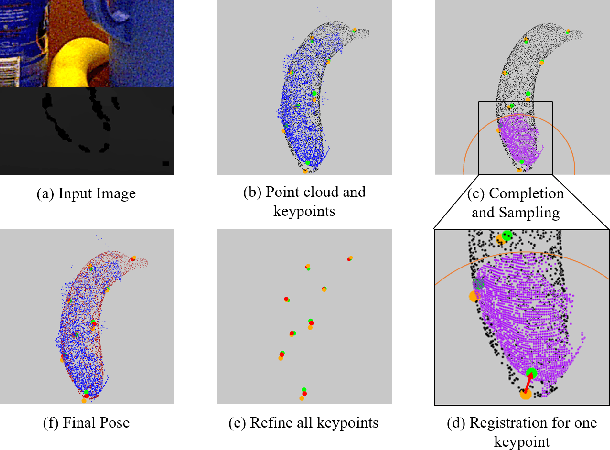
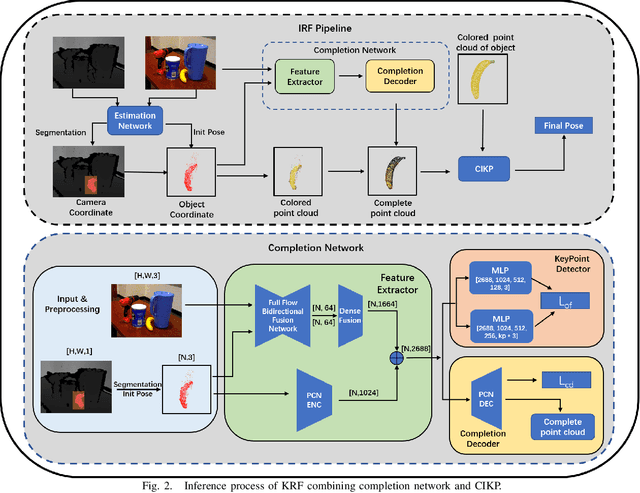

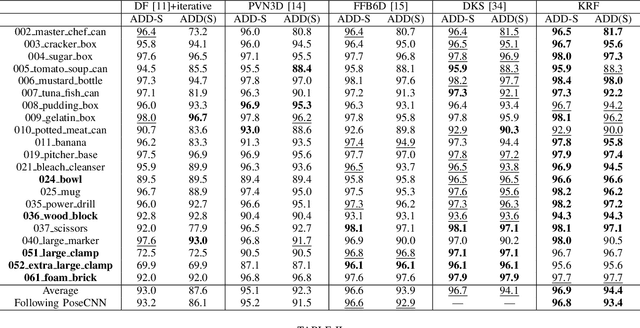
Existing refinement methods gradually lose their ability to further improve pose estimation methods' accuracy. In this paper, we propose a new refinement pipeline, Keypoint Refinement with Fusion Network (KRF), for 6D pose estimation, especially for objects with serious occlusion. The pipeline consists of two steps. It first completes the input point clouds via a novel point completion network. The network uses both local and global features, considering the pose information during point completion. Then, it registers the completed object point cloud with corresponding target point cloud by Color supported Iterative KeyPoint (CIKP). The CIKP method introduces color information into registration and registers point cloud around each keypoint to increase stability. The KRF pipeline can be integrated with existing popular 6D pose estimation methods, e.g. the full flow bidirectional fusion network, to further improved their pose estimation accuracy. Experiments show that our method outperforms the state-of-the-art method from 93.9\% to 94.4\% on YCB-Video dataset and from 64.4\% to 66.8\% on Occlusion LineMOD dataset. Our source code is available at https://github.com/zhanhz/KRF.
A Configuration-Space Decomposition Scheme for Learning-based Collision Checking
Nov 17, 2019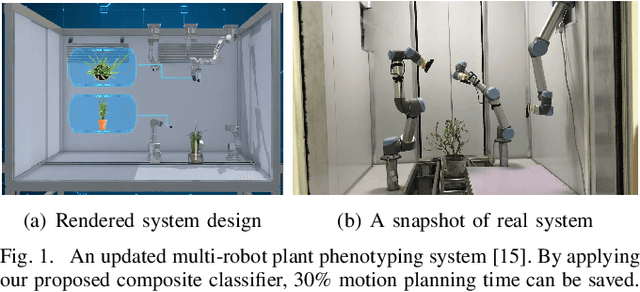
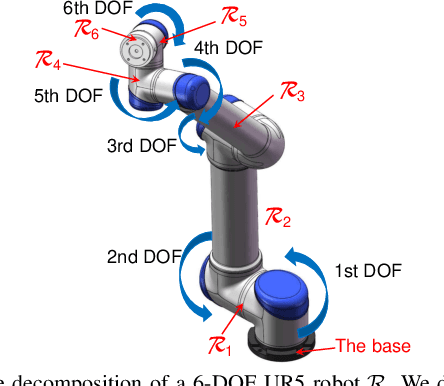
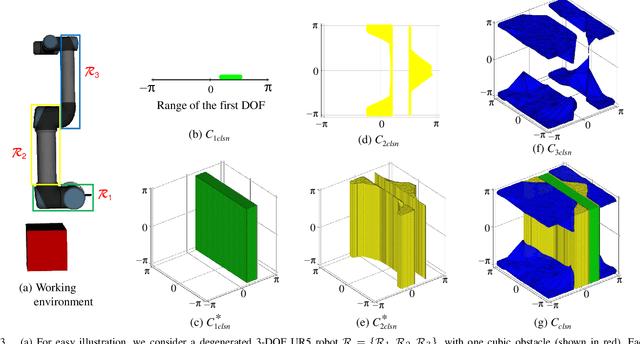

Motion planning for robots of high degrees-of-freedom (DOFs) is an important problem in robotics with sampling-based methods in configuration space C as one popular solution. Recently, machine learning methods have been introduced into sampling-based motion planning methods, which train a classifier to distinguish collision free subspace from in-collision subspace in C. In this paper, we propose a novel configuration space decomposition method and show two nice properties resulted from this decomposition. Using these two properties, we build a composite classifier that works compatibly with previous machine learning methods by using them as the elementary classifiers. Experimental results are presented, showing that our composite classifier outperforms state-of-the-art single classifier methods by a large margin. A real application of motion planning in a multi-robot system in plant phenotyping using three UR5 robotic arms is also presented.