 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Prototype Knowledge Transfer for Federated Learning with Mixed Modalities and Heterogeneous Tasks
Feb 06, 2025

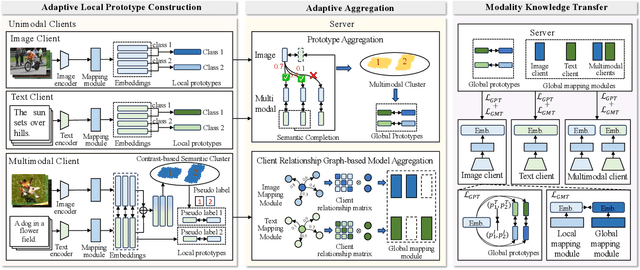

Multimodal Federated Learning (MFL) enables multiple clients to collaboratively train models on multimodal data while ensuring clients' privacy. However, modality and task heterogeneity hinder clients from learning a unified representation, weakening local model generalization, especially in MFL with mixed modalities where only some clients have multimodal data. In this work, we propose an Adaptive prototype-based Multimodal Federated Learning (AproMFL) framework for mixed modalities and heterogeneous tasks to address the aforementioned issues. Our AproMFL transfers knowledge through adaptively-constructed prototypes without a prior public dataset. Clients adaptively select prototype construction methods in line with tasks; server converts client prototypes into unified multimodal prototypes and aggregates them to form global prototypes, avoid clients keeping unified labels. We divide the model into various modules and only aggregate mapping modules to reduce communication and computation overhead. To address aggregation issues in heterogeneity, we develop a client relationship graph-based scheme to dynamically adjust aggregation weights. Extensive experiments on representative datasets evidence effectiveness of AproMFL.
Align Anything: Training All-Modality Models to Follow Instructions with Language Feedback
Dec 20, 2024



Reinforcement learning from human feedback (RLHF) has proven effective in enhancing the instruction-following capabilities of large language models; however, it remains underexplored in the cross-modality domain. As the number of modalities increases, aligning all-modality models with human intentions -- such as instruction following -- becomes a pressing challenge. In this work, we make the first attempt to fine-tune all-modality models (i.e. input and output with any modality, also named any-to-any models) using human preference data across all modalities (including text, image, audio, and video), ensuring its behavior aligns with human intentions. This endeavor presents several challenges. First, there is no large-scale all-modality human preference data in existing open-source resources, as most datasets are limited to specific modalities, predominantly text and image. Secondly, the effectiveness of binary preferences in RLHF for post-training alignment in complex all-modality scenarios remains an unexplored area. Finally, there is a lack of a systematic framework to evaluate the capabilities of all-modality models, particularly regarding modality selection and synergy. To address these challenges, we propose the align-anything framework, which includes meticulously annotated 200k all-modality human preference data. Then, we introduce an alignment method that learns from unified language feedback, effectively capturing complex modality-specific human preferences and enhancing the model's instruction-following capabilities. Furthermore, to assess performance improvements in all-modality models after post-training alignment, we construct a challenging all-modality capability evaluation framework -- eval-anything. All data, models, and code frameworks have been open-sourced for the community. For more details, please refer to https://github.com/PKU-Alignment/align-anything.
FF-LOGO: Cross-Modality Point Cloud Registration with Feature Filtering and Local to Global Optimization
Sep 16, 2023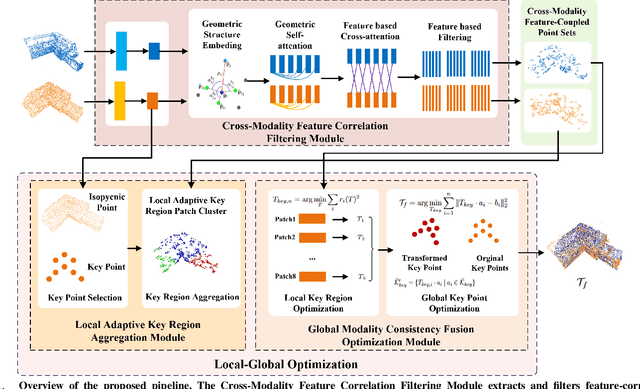
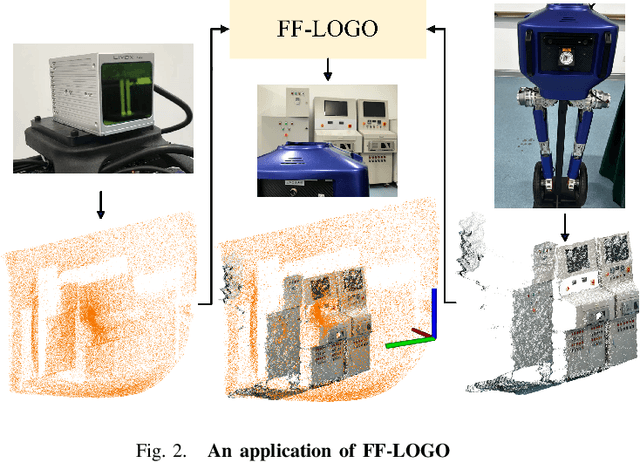
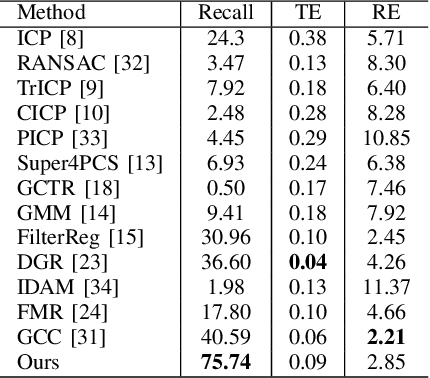
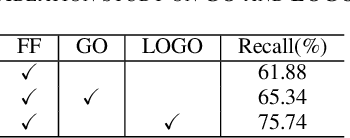
Cross-modality point cloud registration is confronted with significant challenges due to inherent differences in modalities between different sensors. We propose a cross-modality point cloud registration framework FF-LOGO: a cross-modality point cloud registration method with feature filtering and local-global optimization. The cross-modality feature correlation filtering module extracts geometric transformation-invariant features from cross-modality point clouds and achieves point selection by feature matching. We also introduce a cross-modality optimization process, including a local adaptive key region aggregation module and a global modality consistency fusion optimization module. Experimental results demonstrate that our two-stage optimization significantly improves the registration accuracy of the feature association and selection module. Our method achieves a substantial increase in recall rate compared to the current state-of-the-art methods on the 3DCSR dataset, improving from 40.59% to 75.74%. Our code will be available at https://github.com/wangmohan17/FFLOGO.