 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterMT: Multi-Turn Interleaved Preference Alignment with Human Feedback
May 29, 2025As multimodal large models (MLLMs) continue to advance across challenging tasks, a key question emerges: What essential capabilities are still missing? A critical aspect of human learning is continuous interaction with the environment -- not limited to language, but also involving multimodal understanding and generation. To move closer to human-level intelligence, models must similarly support multi-turn, multimodal interaction. In particular, they should comprehend interleaved multimodal contexts and respond coherently in ongoing exchanges. In this work, we present an initial exploration through the InterMT -- the first preference dataset for multi-turn multimodal interaction, grounded in real human feedback. In this exploration, we particularly emphasize the importance of human oversight, introducing expert annotations to guide the process, motivated by the fact that current MLLMs lack such complex interactive capabilities. InterMT captures human preferences at both global and local levels into nine sub-dimensions, consists of 15.6k prompts, 52.6k multi-turn dialogue instances, and 32.4k human-labeled preference pairs. To compensate for the lack of capability for multi-modal understanding and generation, we introduce an agentic workflow that leverages tool-augmented MLLMs to construct multi-turn QA instances. To further this goal, we introduce InterMT-Bench to assess the ability of MLLMs in assisting judges with multi-turn, multimodal tasks. We demonstrate the utility of \InterMT through applications such as judge moderation and further reveal the multi-turn scaling law of judge model. We hope the open-source of our data can help facilitate further research on aligning current MLLMs to the next step. Our project website can be found at https://pku-intermt.github.io .
Generative RLHF-V: Learning Principles from Multi-modal Human Preference
May 24, 2025Training multi-modal large language models (MLLMs) that align with human intentions is a long-term challenge. Traditional score-only reward models for alignment suffer from low accuracy, weak generalization, and poor interpretability, blocking the progress of alignment methods, e.g., reinforcement learning from human feedback (RLHF). Generative reward models (GRMs) leverage MLLMs' intrinsic reasoning capabilities to discriminate pair-wise responses, but their pair-wise paradigm makes it hard to generalize to learnable rewards. We introduce Generative RLHF-V, a novel alignment framework that integrates GRMs with multi-modal RLHF. We propose a two-stage pipeline: $\textbf{multi-modal generative reward modeling from RL}$, where RL guides GRMs to actively capture human intention, then predict the correct pair-wise scores; and $\textbf{RL optimization from grouped comparison}$, which enhances multi-modal RL scoring precision by grouped responses comparison. Experimental results demonstrate that, besides out-of-distribution generalization of RM discrimination, our framework improves 4 MLLMs' performance across 7 benchmarks by $18.1\%$, while the baseline RLHF is only $5.3\%$. We further validate that Generative RLHF-V achieves a near-linear improvement with an increasing number of candidate responses. Our code and models can be found at https://generative-rlhf-v.github.io.
Mitigating Deceptive Alignment via Self-Monitoring
May 24, 2025Modern large language models rely on chain-of-thought (CoT) reasoning to achieve impressive performance, yet the same mechanism can amplify deceptive alignment, situations in which a model appears aligned while covertly pursuing misaligned goals. Existing safety pipelines treat deception as a black-box output to be filtered post-hoc, leaving the model free to scheme during its internal reasoning. We ask: Can deception be intercepted while the model is thinking? We answer this question, the first framework that embeds a Self-Monitor inside the CoT process itself, named CoT Monitor+. During generation, the model produces (i) ordinary reasoning steps and (ii) an internal self-evaluation signal trained to flag and suppress misaligned strategies. The signal is used as an auxiliary reward in reinforcement learning, creating a feedback loop that rewards honest reasoning and discourages hidden goals. To study deceptive alignment systematically, we introduce DeceptionBench, a five-category benchmark that probes covert alignment-faking, sycophancy, etc. We evaluate various LLMs and show that unrestricted CoT roughly aggravates the deceptive tendency. In contrast, CoT Monitor+ cuts deceptive behaviors by 43.8% on average while preserving task accuracy. Further, when the self-monitor signal replaces an external weak judge in RL fine-tuning, models exhibit substantially fewer obfuscated thoughts and retain transparency. Our project website can be found at cot-monitor-plus.github.io
Align Anything: Training All-Modality Models to Follow Instructions with Language Feedback
Dec 20, 2024



Reinforcement learning from human feedback (RLHF) has proven effective in enhancing the instruction-following capabilities of large language models; however, it remains underexplored in the cross-modality domain. As the number of modalities increases, aligning all-modality models with human intentions -- such as instruction following -- becomes a pressing challenge. In this work, we make the first attempt to fine-tune all-modality models (i.e. input and output with any modality, also named any-to-any models) using human preference data across all modalities (including text, image, audio, and video), ensuring its behavior aligns with human intentions. This endeavor presents several challenges. First, there is no large-scale all-modality human preference data in existing open-source resources, as most datasets are limited to specific modalities, predominantly text and image. Secondly, the effectiveness of binary preferences in RLHF for post-training alignment in complex all-modality scenarios remains an unexplored area. Finally, there is a lack of a systematic framework to evaluate the capabilities of all-modality models, particularly regarding modality selection and synergy. To address these challenges, we propose the align-anything framework, which includes meticulously annotated 200k all-modality human preference data. Then, we introduce an alignment method that learns from unified language feedback, effectively capturing complex modality-specific human preferences and enhancing the model's instruction-following capabilities. Furthermore, to assess performance improvements in all-modality models after post-training alignment, we construct a challenging all-modality capability evaluation framework -- eval-anything. All data, models, and code frameworks have been open-sourced for the community. For more details, please refer to https://github.com/PKU-Alignment/align-anything.
Representing Affect Information in Word Embeddings
Sep 21, 2022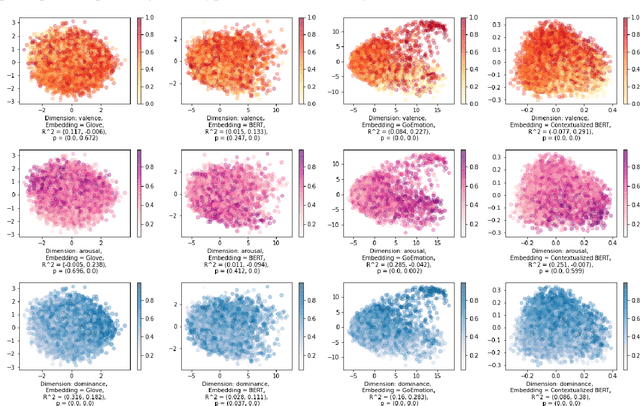
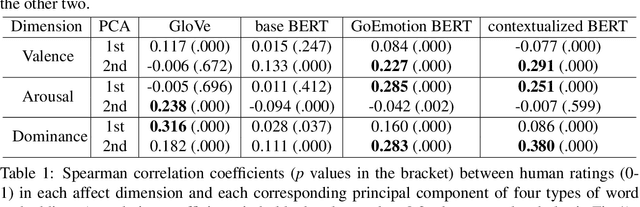

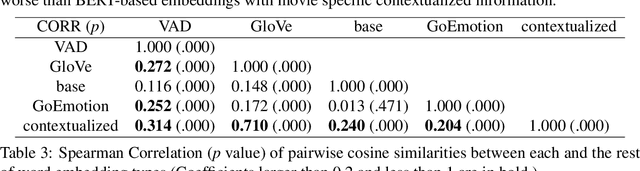
A growing body of research in natural language processing (NLP) and natural language understanding (NLU) is investigating human-like knowledge learned or encoded in the word embeddings from large language models. This is a step towards understanding what knowledge language models capture that resembles human understanding of language and communication. Here, we investigated whether and how the affect meaning of a word (i.e., valence, arousal, dominance) is encoded in word embeddings pre-trained in large neural networks. We used the human-labeled dataset as the ground truth and performed various correlational and classification tests on four types of word embeddings. The embeddings varied in being static or contextualized, and how much affect specific information was prioritized during the pre-training and fine-tuning phase. Our analyses show that word embedding from the vanilla BERT model did not saliently encode the affect information of English words. Only when the BERT model was fine-tuned on emotion-related tasks or contained extra contextualized information from emotion-rich contexts could the corresponding embedding encode more relevant affect information.
DeepAID: Interpreting and Improving Deep Learning-based Anomaly Detection in Security Applications
Sep 23, 2021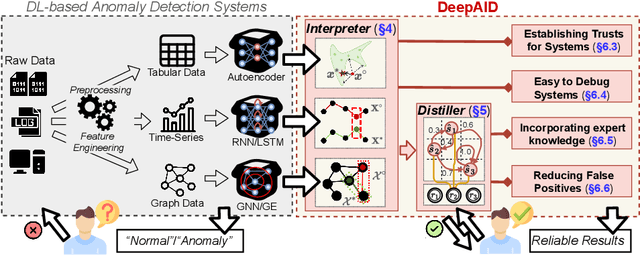

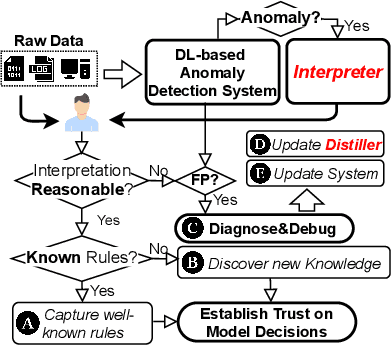

Unsupervised Deep Learning (DL) techniques have been widely used in various security-related anomaly detection applications, owing to the great promise of being able to detect unforeseen threats and superior performance provided by Deep Neural Networks (DNN). However, the lack of interpretability creates key barriers to the adoption of DL models in practice. Unfortunately, existing interpretation approaches are proposed for supervised learning models and/or non-security domains, which are unadaptable for unsupervised DL models and fail to satisfy special requirements in security domains. In this paper, we propose DeepAID, a general framework aiming to (1) interpret DL-based anomaly detection systems in security domains, and (2) improve the practicality of these systems based on the interpretations. We first propose a novel interpretation method for unsupervised DNNs by formulating and solving well-designed optimization problems with special constraints for security domains. Then, we provide several applications based on our Interpreter as well as a model-based extension Distiller to improve security systems by solving domain-specific problems. We apply DeepAID over three types of security-related anomaly detection systems and extensively evaluate our Interpreter with representative prior works. Experimental results show that DeepAID can provide high-quality interpretations for unsupervised DL models while meeting the special requirements of security domains. We also provide several use cases to show that DeepAID can help security operators to understand model decisions, diagnose system mistakes, give feedback to models, and reduce false positives.
Practical Traffic-space Adversarial Attacks on Learning-based NIDSs
May 15, 2020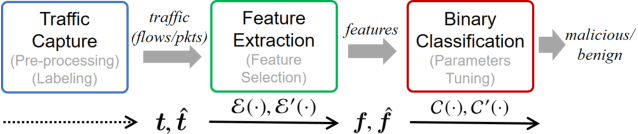
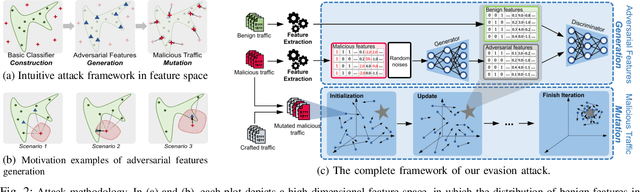
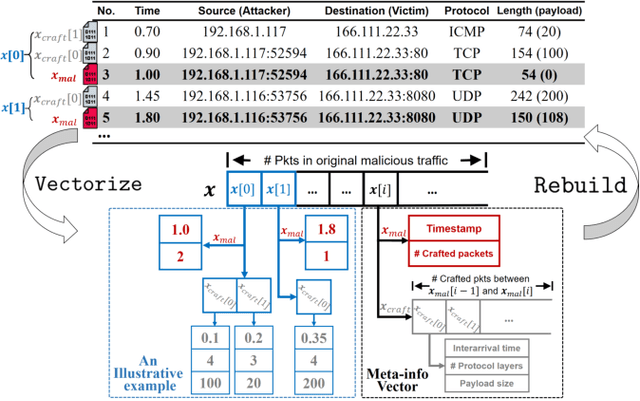
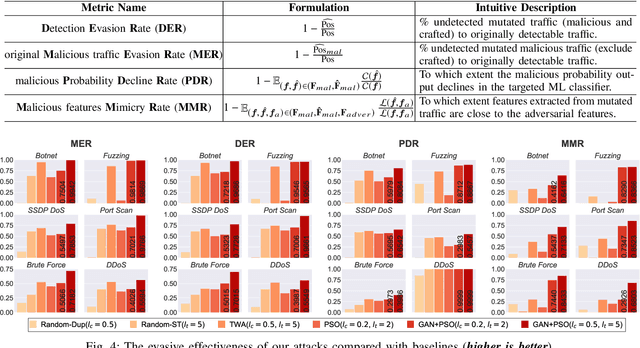
Machine learning (ML) techniques have been increasingly used in anomaly-based network intrusion detection systems (NIDS) to detect unknown attacks. However, ML has shown to be extremely vulnerable to adversarial attacks, aggravating the potential risk of evasion attacks against learning-based NIDSs. In this situation, prior studies on evading traditional anomaly-based or signature-based NIDSs are no longer valid. Existing attacks on learning-based NIDSs mostly focused on feature-space and/or white-box attacks, leaving the study on practical gray/black-box attacks largely unexplored. To bridge this gap, we conduct the first systematic study of the practical traffic-space evasion attack on learning-based NIDSs. We outperform the previous work in the following aspects: (1) practical---instead of directly modifying features, we provide a novel framework to automatically mutate malicious traffic with extremely limited knowledge while preserving its functionality; (2) generic---the proposed attack is effective for any ML classifiers (i.e., model-agnostic) and most non-payload-based features; (3) explainable---we propose a feature-based interpretation method to measure the robustness of targeted systems against such attacks. We extensively evaluate our attack and defense scheme on Kitsune, a state-of-the-art learning-based NIDS, as well as measuring the robustness of various NIDSs using diverse features and ML classifiers. Experimental results show promising results and intriguing findings.