 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting Affect Information in Word Embeddings
Paper and Code
Sep 21, 2022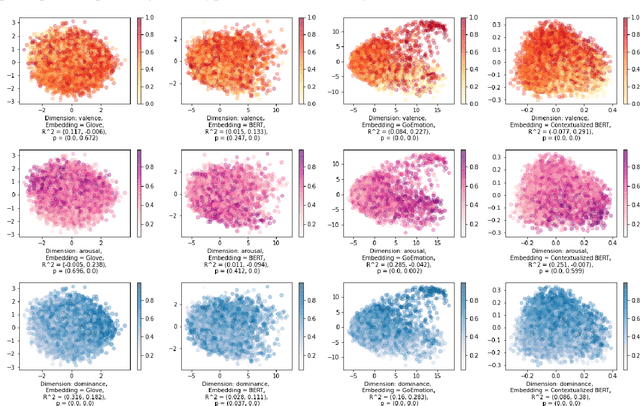
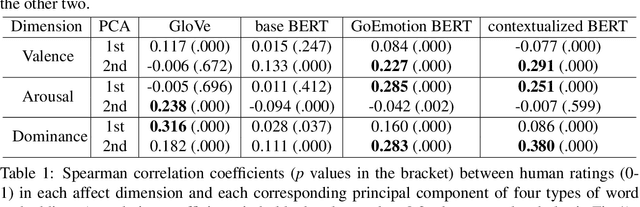

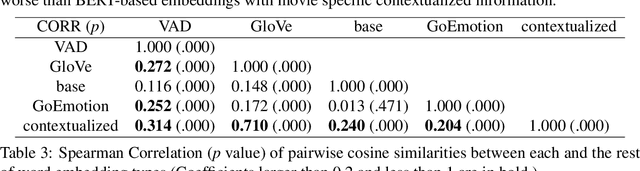
A growing body of research in natural language processing (NLP) and natural language understanding (NLU) is investigating human-like knowledge learned or encoded in the word embeddings from large language models. This is a step towards understanding what knowledge language models capture that resembles human understanding of language and communication. Here, we investigated whether and how the affect meaning of a word (i.e., valence, arousal, dominance) is encoded in word embeddings pre-trained in large neural networks. We used the human-labeled dataset as the ground truth and performed various correlational and classification tests on four types of word embeddings. The embeddings varied in being static or contextualized, and how much affect specific information was prioritized during the pre-training and fine-tuning phase. Our analyses show that word embedding from the vanilla BERT model did not saliently encode the affect information of English words. Only when the BERT model was fine-tuned on emotion-related tasks or contained extra contextualized information from emotion-rich contexts could the corresponding embedding encode more relevant affect information.