 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulticast Scheduling for Multi-Message over Multi-Channel: A Permutation-based Wolpertinger Deep Reinforcement Learning Method
Paper and Code
May 19, 2022

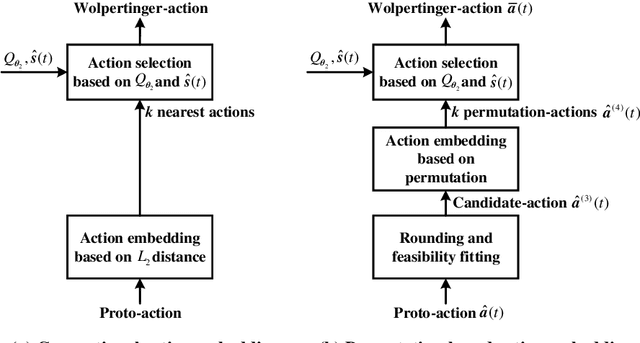
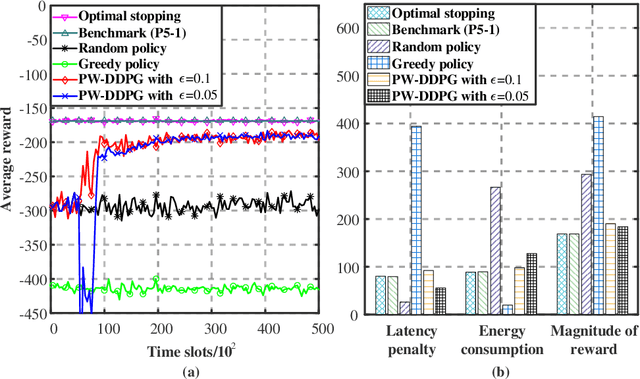
Multicasting is an efficient technique to simultaneously transmit common messages from the base station (BS) to multiple mobile users (MUs). The multicast scheduling problem for multiple messages over multiple channels, which jointly minimizes the energy consumption of the BS and the latency of serving asynchronized requests from the MUs, is formulated as an infinite-horizon Markov decision process (MDP) with large discrete action space and multiple time-varying constraints, which has not been efficiently addressed in the literatures. By studying the intrinsic features of this MDP under stationary policies and refining the reward function, we first simplify it to an equivalent form with a much smaller state space. Then, we propose a modified deep reinforcement learning (DRL) algorithm, namely the permutation-based Wolpertinger deep deterministic policy gradient (PW-DDPG), to solve the simplified problem. Specifically, PW-DDPG utilizes a permutation-based action embedding module to address the large discrete action space issue and a feasible exploration module to deal with the time-varying constraints. Moreover, as a benchmark, an upper bound of the considered MDP is derived by solving an integer programming problem. Numerical results validate that the proposed algorithm achieves close performance to the derived benchmark.