 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Rewards in Text Summarization: Multi-Objective Reinforcement Learning via HyperVolume Optimization
Oct 22, 2025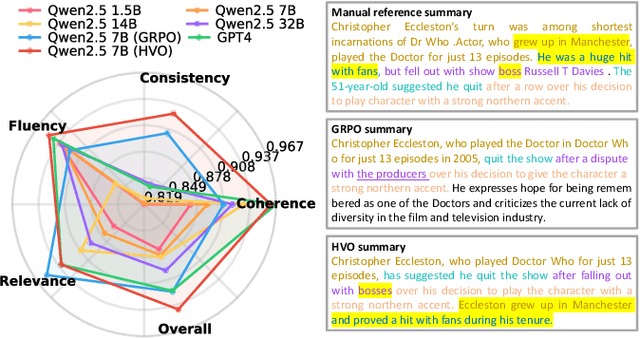
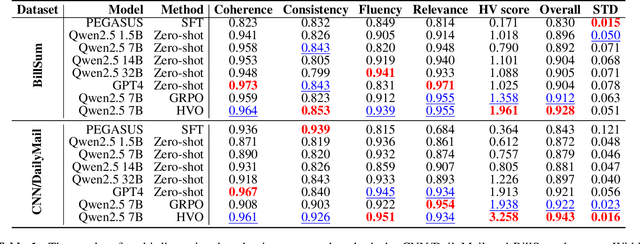
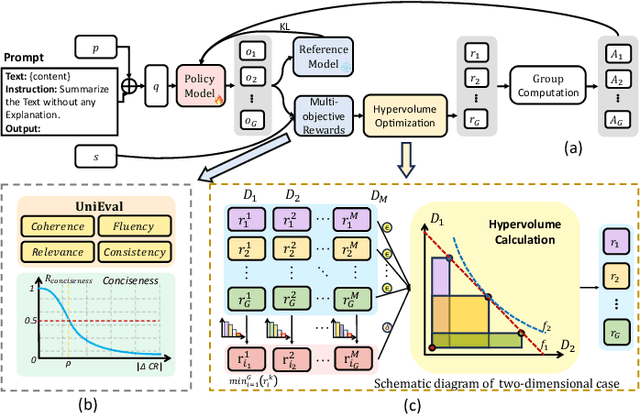

Text summarization is a crucial task that requires the simultaneous optimization of multiple objectives, including consistency, coherence, relevance, and fluency, which presents considerable challenges. Although large language models (LLMs) have demonstrated remarkable performance, enhanced by reinforcement learning (RL), few studies have focused on optimizing the multi-objective problem of summarization through RL based on LLMs. In this paper, we introduce hypervolume optimization (HVO), a novel optimization strategy that dynamically adjusts the scores between groups during the reward process in RL by using the hypervolume method. This method guides the model's optimization to progressively approximate the pareto front, thereby generating balanced summaries across multiple objectives. Experimental results on several representative summarization datasets demonstrate that our method outperforms group relative policy optimization (GRPO) in overall scores and shows more balanced performance across different dimensions. Moreover, a 7B foundation model enhanced by HVO performs comparably to GPT-4 in the summarization task, while maintaining a shorter generation length. Our code is publicly available at https://github.com/ai4business-LiAuto/HVO.git
MoFE-Time: Mixture of Frequency Domain Experts for Time-Series Forecasting Models
Jul 09, 2025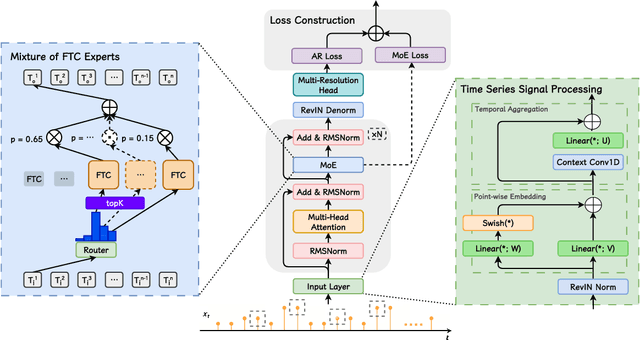



As a prominent data modality task, time series forecasting plays a pivotal role in diverse applications. With the remarkable advancements in Large Language Models (LLMs), the adoption of LLMs as the foundational architecture for time series modeling has gained significant attention. Although existing models achieve some success, they rarely both model time and frequency characteristics in a pretraining-finetuning paradigm leading to suboptimal performance in predictions of complex time series, which requires both modeling periodicity and prior pattern knowledge of signals. We propose MoFE-Time, an innovative time series forecasting model that integrates time and frequency domain features within a Mixture of Experts (MoE) network. Moreover, we use the pretraining-finetuning paradigm as our training framework to effectively transfer prior pattern knowledge across pretraining and finetuning datasets with different periodicity distributions. Our method introduces both frequency and time cells as experts after attention modules and leverages the MoE routing mechanism to construct multidimensional sparse representations of input signals. In experiments on six public benchmarks, MoFE-Time has achieved new state-of-the-art performance, reducing MSE and MAE by 6.95% and 6.02% compared to the representative methods Time-MoE. Beyond the existing evaluation benchmarks, we have developed a proprietary dataset, NEV-sales, derived from real-world business scenarios. Our method achieves outstanding results on this dataset, underscoring the effectiveness of the MoFE-Time model in practical commercial applications.
Quantum Learning and Estimation for Distribution Networks and Energy Communities Coordination
Jun 13, 2025Price signals from distribution networks (DNs) guide energy communities (ECs) to adjust energy usage, enabling effective coordination for reliable power system operation. However, this coordination faces significant challenges due to the limited availability of information (i.e., only the aggregated energy usage of ECs is available to DNs), and the high computational burden of accounting for uncertainties and the associated risks through numerous scenarios. To address these challenges, we propose a quantum learning and estimation approach to enhance coordination between DNs and ECs. Specifically, leveraging advanced quantum properties such as quantum superposition and entanglement, we develop a hybrid quantum temporal convolutional network-long short-term memory (Q-TCN-LSTM) model to establish an end-to-end mapping between ECs' responses and the price incentives from DNs. Moreover, we develop a quantum estimation method based on quantum amplitude estimation (QAE) and two phase-rotation circuits to significantly accelerate the optimization process under numerous uncertainty scenarios. Numerical experiments demonstrate that, compared to classical neural networks, the proposed Q-TCN-LSTM model improves the mapping accuracy by 69.2% while reducing the model size by 99.75% and the computation time by 93.9%. Compared to classical Monte Carlo simulation, QAE achieves comparable accuracy with a dramatic reduction in computational time (up to 99.99%) and requires significantly fewer computational resources.
Coordinated Power Smoothing Control for Wind Storage Integrated System with Physics-informed Deep Reinforcement Learning
Dec 17, 2024



The Wind Storage Integrated System with Power Smoothing Control (PSC) has emerged as a promising solution to ensure both efficient and reliable wind energy generation. However, existing PSC strategies overlook the intricate interplay and distinct control frequencies between batteries and wind turbines, and lack consideration of wake effect and battery degradation cost. In this paper, a novel coordinated control framework with hierarchical levels is devised to address these challenges effectively, which integrates the wake model and battery degradation model. In addition, after reformulating the problem as a Markov decision process, the multi-agent reinforcement learning method is introduced to overcome the bi-level characteristic of the problem. Moreover, a Physics-informed Neural Network-assisted Multi-agent Deep Deterministic Policy Gradient (PAMA-DDPG) algorithm is proposed to incorporate the power fluctuation differential equation and expedite the learning process. The effectiveness of the proposed methodology is evaluated through simulations conducted in four distinct scenarios using WindFarmSimulator (WFSim). The results demonstrate that the proposed algorithm facilitates approximately an 11% increase in total profit and a 19% decrease in power fluctuation compared to the traditional methods, thereby addressing the dual objectives of economic efficiency and grid-connected energy reliability.
ElecBench: a Power Dispatch Evaluation Benchmark for Large Language Models
Jul 07, 2024In response to the urgent demand for grid stability and the complex challenges posed by renewable energy integration and electricity market dynamics, the power sector increasingly seeks innovative technological solutions. In this context, large language models (LLMs) have become a key technology to improve efficiency and promote intelligent progress in the power sector with their excellent natural language processing, logical reasoning, and generalization capabilities. Despite their potential, the absence of a performance evaluation benchmark for LLM in the power sector has limited the effective application of these technologies. Addressing this gap, our study introduces "ElecBench", an evaluation benchmark of LLMs within the power sector. ElecBench aims to overcome the shortcomings of existing evaluation benchmarks by providing comprehensive coverage of sector-specific scenarios, deepening the testing of professional knowledge, and enhancing decision-making precision. The framework categorizes scenarios into general knowledge and professional business, further divided into six core performance metrics: factuality, logicality, stability, security, fairness, and expressiveness, and is subdivided into 24 sub-metrics, offering profound insights into the capabilities and limitations of LLM applications in the power sector. To ensure transparency, we have made the complete test set public, evaluating the performance of eight LLMs across various scenarios and metrics. ElecBench aspires to serve as the standard benchmark for LLM applications in the power sector, supporting continuous updates of scenarios, metrics, and models to drive technological progress and application.
Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods
Mar 30, 2024With extensive pre-trained knowledge and high-level general capabilities, large language models (LLMs) emerge as a promising avenue to augment reinforcement learning (RL) in aspects such as multi-task learning, sample efficiency, and task planning. In this survey, we provide a comprehensive review of the existing literature in $\textit{LLM-enhanced RL}$ and summarize its characteristics compared to conventional RL methods, aiming to clarify the research scope and directions for future studies. Utilizing the classical agent-environment interaction paradigm, we propose a structured taxonomy to systematically categorize LLMs' functionalities in RL, including four roles: information processor, reward designer, decision-maker, and generator. Additionally, for each role, we summarize the methodologies, analyze the specific RL challenges that are mitigated, and provide insights into future directions. Lastly, potential applications, prospective opportunities and challenges of the $\textit{LLM-enhanced RL}$ are discussed.
Understanding Semantics from Speech Through Pre-training
Sep 24, 2019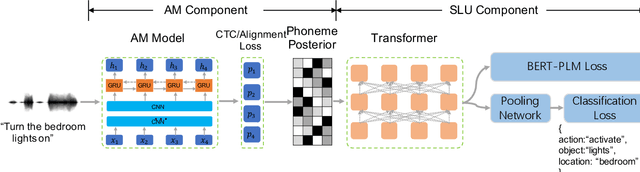


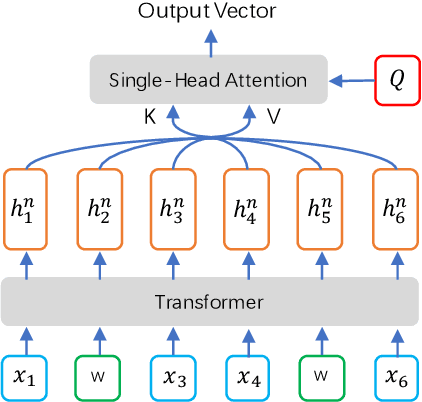
End-to-end Spoken Language Understanding (SLU) is proposed to infer the semantic meaning directly from audio features without intermediate text representation. Although the acoustic model component of an end-to-end SLU system can be pre-trained with Automatic Speech Recognition (ASR) targets, the SLU component can only learn semantic features from limited task-specific training data. In this paper, for the first time we propose to do large-scale unsupervised pre-training for the SLU component of an end-to-end SLU system, so that the SLU component may preserve semantic features from massive unlabeled audio data. As the output of the acoustic model component, i.e. phoneme posterior sequences, has much different characteristic from text sequences, we propose a novel pre-training model called BERT-PLM, which stands for Bidirectional Encoder Representations from Transformers through Permutation Language Modeling. BERT-PLM trains the SLU component on unlabeled data through a regression objective equivalent to the partial permutation language modeling objective, while leverages full bi-directional context information with BERT networks. The experiment results show that our approach out-perform the state-of-the-art end-to-end systems with over 12.5% error reduction.