 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Graph Neural Networks and Many-Body Expansion Theory for Potential Energy Surfaces
Nov 03, 2024



Rational design of next-generation functional materials relied on quantitative predictions of their electronic structures beyond single building blocks. First-principles quantum mechanical (QM) modeling became infeasible as the size of a material grew beyond hundreds of atoms. In this study, we developed a new computational tool integrating fragment-based graph neural networks (FBGNN) into the fragment-based many-body expansion (MBE) theory, referred to as FBGNN-MBE, and demonstrated its capacity to reproduce full-dimensional potential energy surfaces (FD-PES) for hierarchic chemical systems with manageable accuracy, complexity, and interpretability. In particular, we divided the entire system into basic building blocks (fragments), evaluated their single-fragment energies using a first-principles QM model and attacked many-fragment interactions using the structure-property relationships trained by FBGNNs. Our development of FBGNN-MBE demonstrated the potential of a new framework integrating deep learning models into fragment-based QM methods, and marked a significant step towards computationally aided design of large functional materials.
Domain Adaptation for Industrial Time-series Forecasting via Counterfactual Inference
Jul 19, 2024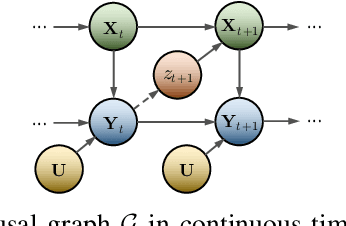
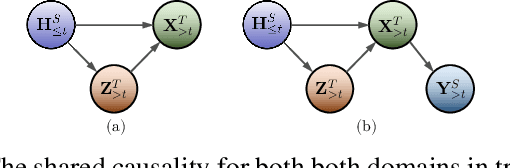
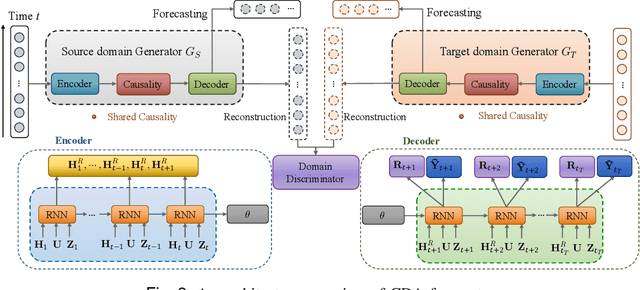
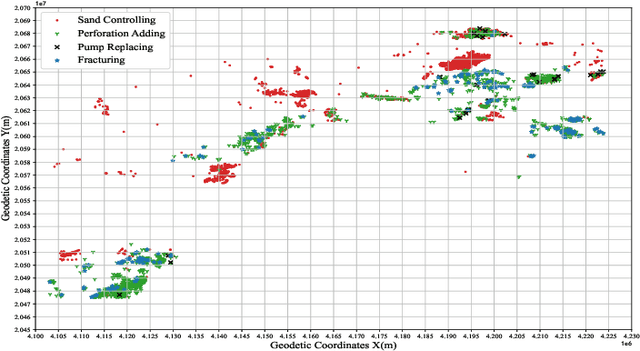
Industrial time-series, as a structural data responds to production process information, can be utilized to perform data-driven decision-making for effective monitoring of industrial production process. However, there are some challenges for time-series forecasting in industry, e.g., predicting few-shot caused by data shortage, and decision-confusing caused by unknown treatment policy. To cope with the problems, we propose a novel causal domain adaptation framework, Causal Domain Adaptation (CDA) forecaster to improve the performance on the interested domain with limited data (target). Firstly, we analyze the causality existing along with treatments, and thus ensure the shared causality over time. Subsequently, we propose an answer-based attention mechanism to achieve domain-invariant representation by the shared causality in both domains. Then, a novel domain-adaptation is built to model treatments and outcomes jointly training on source and target domain. The main insights are that our designed answer-based attention mechanism allows the target domain to leverage the existed causality in source time-series even with different treatments, and our forecaster can predict the counterfactual outcome of industrial time-series, meaning a guidance in production process. Compared with commonly baselines, our method on real-world and synthetic oilfield datasets demonstrates the effectiveness in across-domain prediction and the practicality in guiding production process
BiFeat: Supercharge GNN Training via Graph Feature Quantization
Jul 29, 2022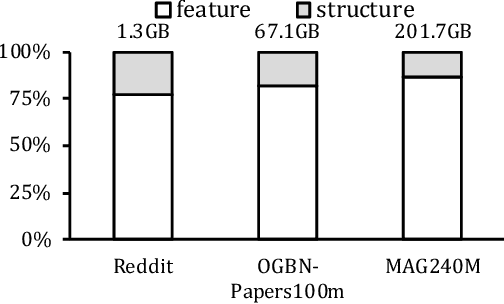
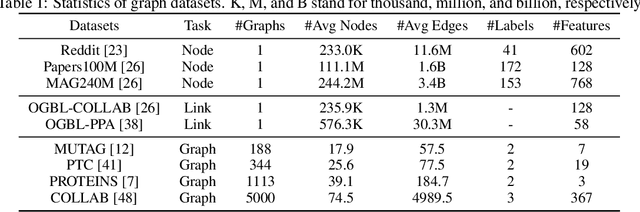
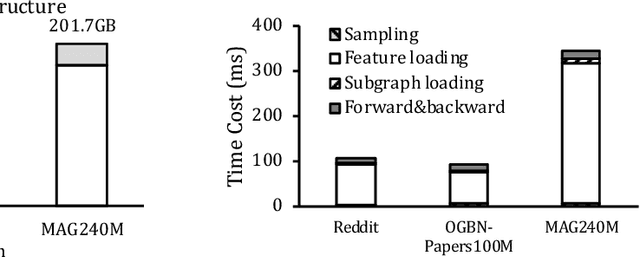
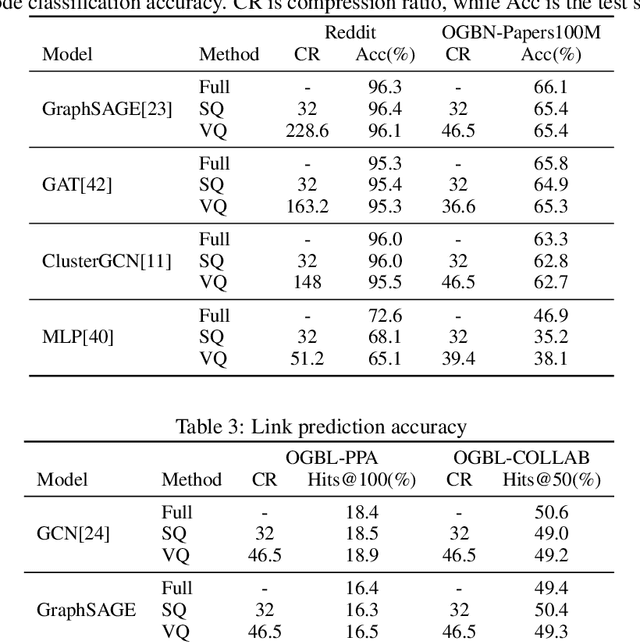
Graph Neural Networks (GNNs) is a promising approach for applications with nonEuclidean data. However, training GNNs on large scale graphs with hundreds of millions nodes is both resource and time consuming. Different from DNNs, GNNs usually have larger memory footprints, and thus the GPU memory capacity and PCIe bandwidth are the main resource bottlenecks in GNN training. To address this problem, we present BiFeat: a graph feature quantization methodology to accelerate GNN training by significantly reducing the memory footprint and PCIe bandwidth requirement so that GNNs can take full advantage of GPU computing capabilities. Our key insight is that unlike DNN, GNN is less prone to the information loss of input features caused by quantization. We identify the main accuracy impact factors in graph feature quantization and theoretically prove that BiFeat training converges to a network where the loss is within $\epsilon$ of the optimal loss of uncompressed network. We perform extensive evaluation of BiFeat using several popular GNN models and datasets, including GraphSAGE on MAG240M, the largest public graph dataset. The results demonstrate that BiFeat achieves a compression ratio of more than 30 and improves GNN training speed by 200%-320% with marginal accuracy loss. In particular, BiFeat achieves a record by training GraphSAGE on MAG240M within one hour using only four GPUs.
Improving Subgraph Representation Learning via Multi-View Augmentation
May 25, 2022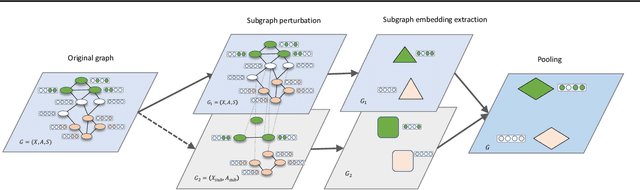

Subgraph representation learning based on Graph Neural Network (GNN) has broad applications in chemistry and biology, such as molecule property prediction and gene collaborative function prediction. On the other hand, graph augmentation techniques have shown promising results in improving graph-based and node-based classification tasks but are rarely explored in the GNN-based subgraph representation learning literature. In this work, we developed a novel multiview augmentation mechanism to improve subgraph representation learning and thus the accuracy of downstream prediction tasks. The augmentation technique creates multiple variants of subgraphs and embeds these variants into the original graph to achieve both high training efficiency, scalability, and improved accuracy. Experiments on several real-world subgraph benchmarks demonstrate the superiority of our proposed multi-view augmentation techniques.