 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeader and Follower: Interactive Motion Generation under Trajectory Constraints
Feb 17, 2025



With the rapid advancement of game and film production, generating interactive motion from texts has garnered significant attention due to its potential to revolutionize content creation processes. In many practical applications, there is a need to impose strict constraints on the motion range or trajectory of virtual characters. However, existing methods that rely solely on textual input face substantial challenges in accurately capturing the user's intent, particularly in specifying the desired trajectory. As a result, the generated motions often lack plausibility and accuracy. Moreover, existing trajectory - based methods for customized motion generation rely on retraining for single - actor scenarios, which limits flexibility and adaptability to different datasets, as well as interactivity in two-actor motions. To generate interactive motion following specified trajectories, this paper decouples complex motion into a Leader - Follower dynamic, inspired by role allocation in partner dancing. Based on this framework, this paper explores the motion range refinement process in interactive motion generation and proposes a training-free approach, integrating a Pace Controller and a Kinematic Synchronization Adapter. The framework enhances the ability of existing models to generate motion that adheres to trajectory by controlling the leader's movement and correcting the follower's motion to align with the leader. Experimental results show that the proposed approach, by better leveraging trajectory information, outperforms existing methods in both realism and accuracy.
Integrating Graph Neural Networks and Many-Body Expansion Theory for Potential Energy Surfaces
Nov 03, 2024



Rational design of next-generation functional materials relied on quantitative predictions of their electronic structures beyond single building blocks. First-principles quantum mechanical (QM) modeling became infeasible as the size of a material grew beyond hundreds of atoms. In this study, we developed a new computational tool integrating fragment-based graph neural networks (FBGNN) into the fragment-based many-body expansion (MBE) theory, referred to as FBGNN-MBE, and demonstrated its capacity to reproduce full-dimensional potential energy surfaces (FD-PES) for hierarchic chemical systems with manageable accuracy, complexity, and interpretability. In particular, we divided the entire system into basic building blocks (fragments), evaluated their single-fragment energies using a first-principles QM model and attacked many-fragment interactions using the structure-property relationships trained by FBGNNs. Our development of FBGNN-MBE demonstrated the potential of a new framework integrating deep learning models into fragment-based QM methods, and marked a significant step towards computationally aided design of large functional materials.
Adaptively Lighting up Facial Expression Crucial Regions via Local Non-Local Joint Network
Mar 26, 2022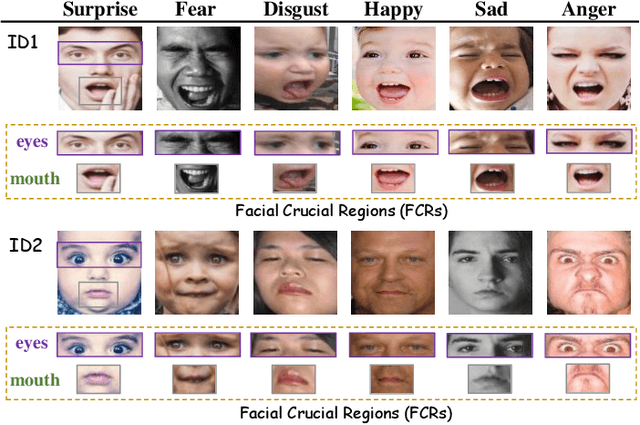
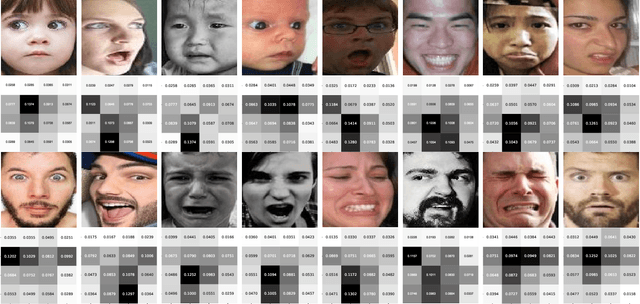
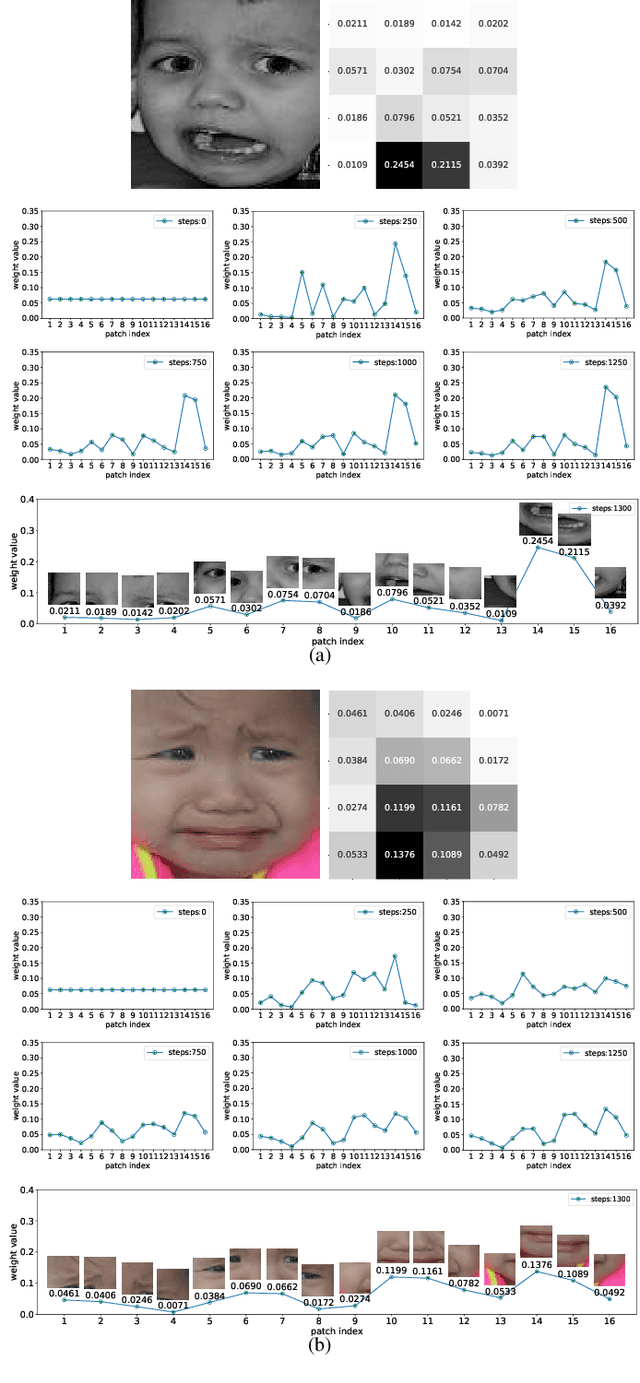
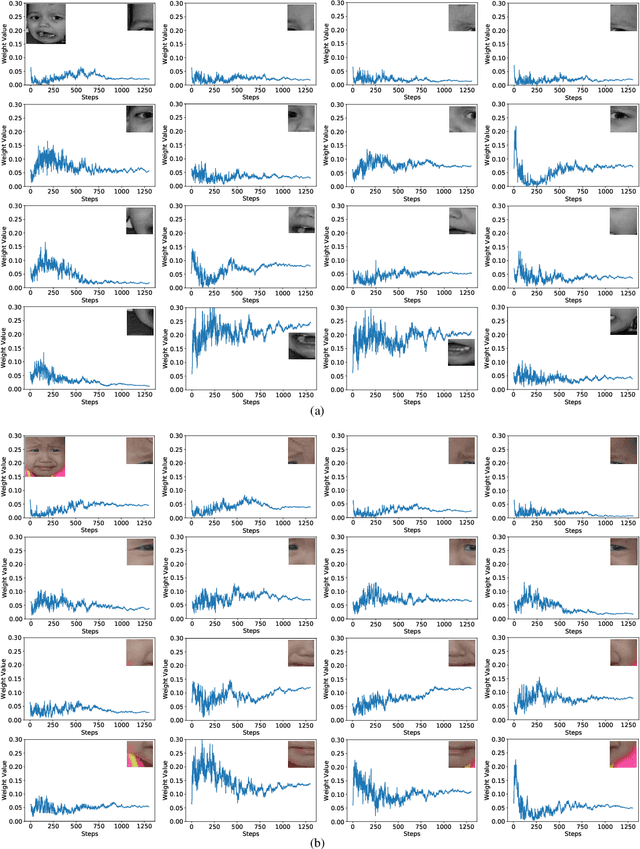
Facial expression recognition (FER) is still one challenging research due to the small inter-class discrepancy in the facial expression data. In view of the significance of facial crucial regions for FER, many existing researches utilize the prior information from some annotated crucial points to improve the performance of FER. However, it is complicated and time-consuming to manually annotate facial crucial points, especially for vast wild expression images. Based on this, a local non-local joint network is proposed to adaptively light up the facial crucial regions in feature learning of FER in this paper. In the proposed method, two parts are constructed based on facial local and non-local information respectively, where an ensemble of multiple local networks are proposed to extract local features corresponding to multiple facial local regions and a non-local attention network is addressed to explore the significance of each local region. Especially, the attention weights obtained by the non-local network is fed into the local part to achieve the interactive feedback between the facial global and local information. Interestingly, the non-local weights corresponding to local regions are gradually updated and higher weights are given to more crucial regions. Moreover, U-Net is employed to extract the integrated features of deep semantic information and low hierarchical detail information of expression images. Finally, experimental results illustrate that the proposed method achieves more competitive performance compared with several state-of-the art methods on five benchmark datasets. Noticeably, the analyses of the non-local weights corresponding to local regions demonstrate that the proposed method can automatically enhance some crucial regions in the process of feature learning without any facial landmark information.
Label Distribution Amendment with Emotional Semantic Correlations for Facial Expression Recognition
Jul 23, 2021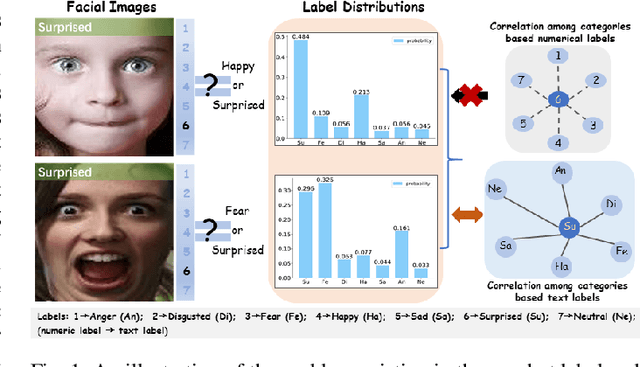
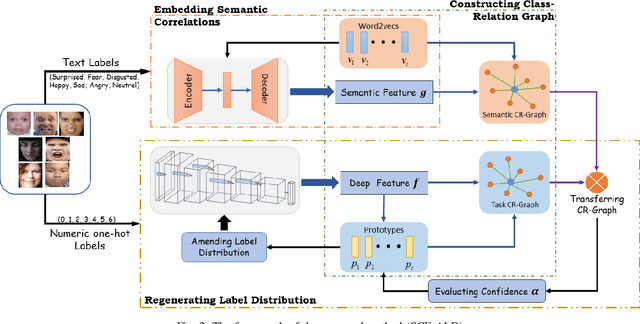
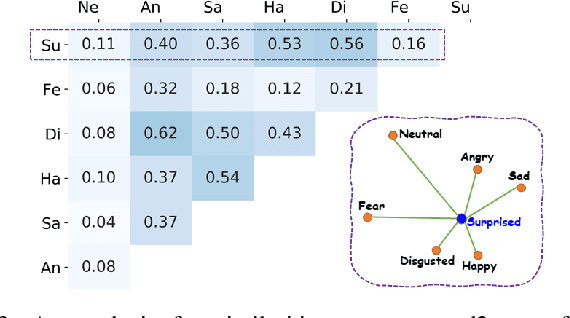
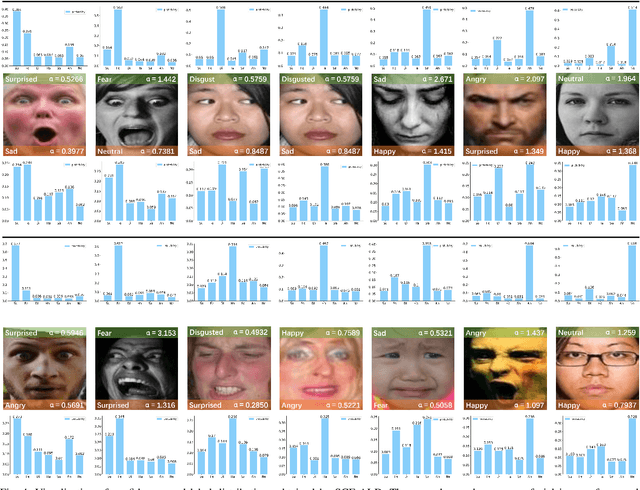
By utilizing label distribution learning, a probability distribution is assigned for a facial image to express a compound emotion, which effectively improves the problem of label uncertainties and noises occurred in one-hot labels. In practice, it is observed that correlations among emotions are inherently different, such as surprised and happy emotions are more possibly synchronized than surprised and neutral. It indicates the correlation may be crucial for obtaining a reliable label distribution. Based on this, we propose a new method that amends the label distribution of each facial image by leveraging correlations among expressions in the semantic space. Inspired by inherently diverse correlations among word2vecs, the topological information among facial expressions is firstly explored in the semantic space, and each image is embedded into the semantic space. Specially, a class-relation graph is constructed to transfer the semantic correlation among expressions into the task space. By comparing semantic and task class-relation graphs of each image, the confidence of its label distribution is evaluated. Based on the confidence, the label distribution is amended by enhancing samples with higher confidence and weakening samples with lower confidence. Experimental results demonstrate the proposed method is more effective than compared state-of-the-art methods.
Look Across Elapse: Disentangled Representation Learning and Photorealistic Cross-Age Face Synthesis for Age-Invariant Face Recognition
Oct 04, 2018
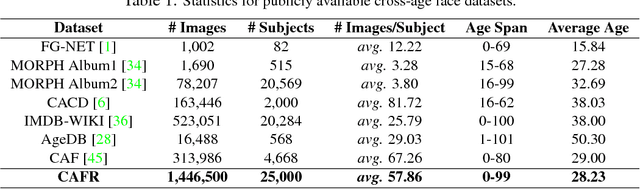
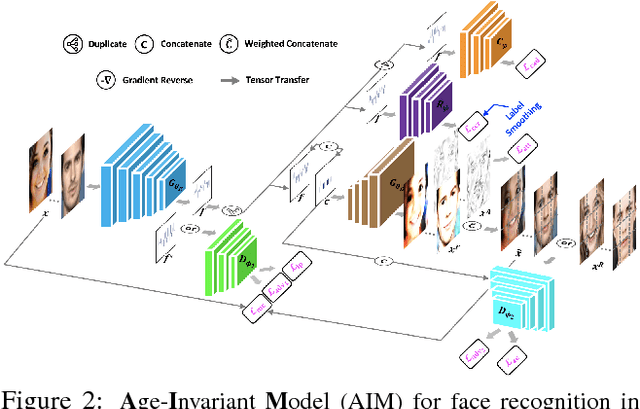
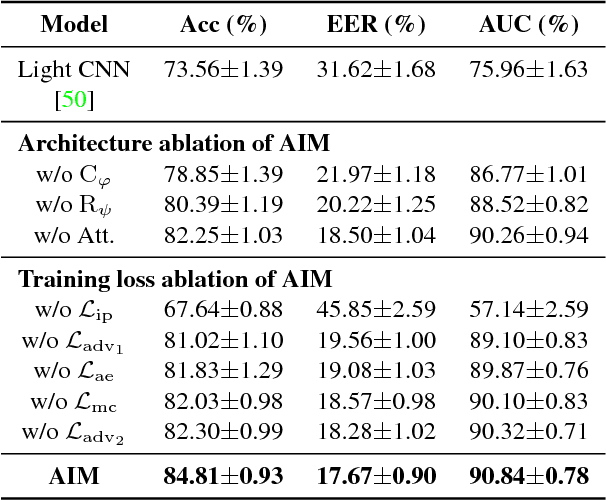
Despite the remarkable progress in face recognition related technologies, reliably recognizing faces across ages still remains a big challenge. The appearance of a human face changes substantially over time, resulting in significant intra-class variations. As opposed to current techniques for age-invariant face recognition, which either directly extract age-invariant features for recognition, or first synthesize a face that matches target age before feature extraction, we argue that it is more desirable to perform both tasks jointly so that they can leverage each other. To this end, we propose a deep Age-Invariant Model (AIM) for face recognition in the wild with three distinct novelties. First, AIM presents a novel unified deep architecture jointly performing cross-age face synthesis and recognition in a mutual boosting way. Second, AIM achieves continuous face rejuvenation/aging with remarkable photorealistic and identity-preserving properties, avoiding the requirement of paired data and the true age of testing samples. Third, we develop effective and novel training strategies for end-to-end learning the whole deep architecture, which generates powerful age-invariant face representations explicitly disentangled from the age variation. Moreover, we propose a new large-scale Cross-Age Face Recognition (CAFR) benchmark dataset to facilitate existing efforts and push the frontiers of age-invariant face recognition research. Extensive experiments on both our CAFR and several other cross-age datasets (MORPH, CACD and FG-NET) demonstrate the superiority of the proposed AIM model over the state-of-the-arts. Benchmarking our model on one of the most popular unconstrained face recognition datasets IJB-C additionally verifies the promising generalizability of AIM in recognizing faces in the wild.
A Good Practice Towards Top Performance of Face Recognition: Transferred Deep Feature Fusion
Feb 09, 2018
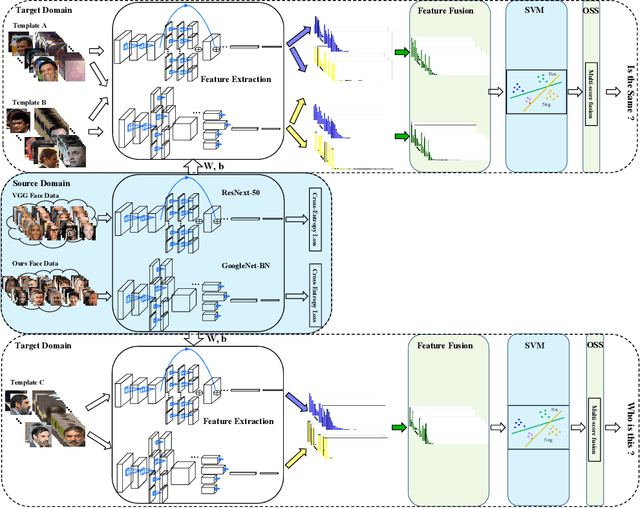
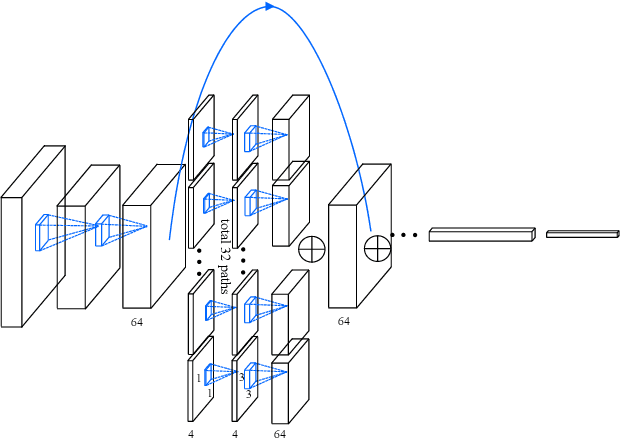
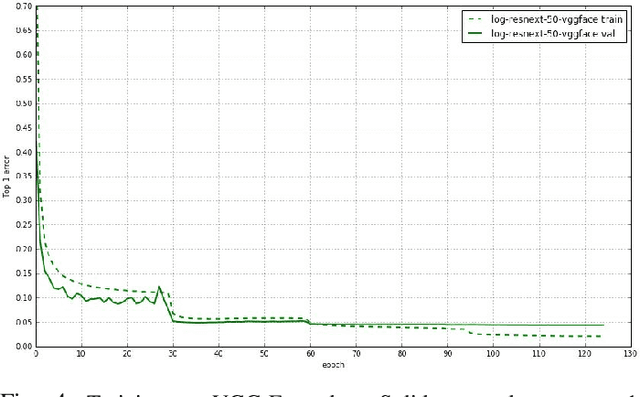
Unconstrained face recognition performance evaluations have traditionally focused on Labeled Faces in the Wild (LFW) dataset for imagery and the YouTubeFaces (YTF) dataset for videos in the last couple of years. Spectacular progress in this field has resulted in saturation on verification and identification accuracies for those benchmark datasets. In this paper, we propose a unified learning framework named Transferred Deep Feature Fusion (TDFF) targeting at the new IARPA Janus Benchmark A (IJB-A) face recognition dataset released by NIST face challenge. The IJB-A dataset includes real-world unconstrained faces from 500 subjects with full pose and illumination variations which are much harder than the LFW and YTF datasets. Inspired by transfer learning, we train two advanced deep convolutional neural networks (DCNN) with two different large datasets in source domain, respectively. By exploring the complementarity of two distinct DCNNs, deep feature fusion is utilized after feature extraction in target domain. Then, template specific linear SVMs is adopted to enhance the discrimination of framework. Finally, multiple matching scores corresponding different templates are merged as the final results. This simple unified framework exhibits excellent performance on IJB-A dataset. Based on the proposed approach, we have submitted our IJB-A results to National Institute of Standards and Technology (NIST) for official evaluation. Moreover, by introducing new data and advanced neural architecture, our method outperforms the state-of-the-art by a wide margin on IJB-A dataset.