 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvBridge: Bridging Diverse Environments with Cross-Environment Knowledge Transfer for Embodied AI
Oct 22, 2024



In recent years, Large Language Models (LLMs) have demonstrated high reasoning capabilities, drawing attention for their applications as agents in various decision-making processes. One notably promising application of LLM agents is robotic manipulation. Recent research has shown that LLMs can generate text planning or control code for robots, providing substantial flexibility and interaction capabilities. However, these methods still face challenges in terms of flexibility and applicability across different environments, limiting their ability to adapt autonomously. Current approaches typically fall into two categories: those relying on environment-specific policy training, which restricts their transferability, and those generating code actions based on fixed prompts, which leads to diminished performance when confronted with new environments. These limitations significantly constrain the generalizability of agents in robotic manipulation. To address these limitations, we propose a novel method called EnvBridge. This approach involves the retention and transfer of successful robot control codes from source environments to target environments. EnvBridge enhances the agent's adaptability and performance across diverse settings by leveraging insights from multiple environments. Notably, our approach alleviates environmental constraints, offering a more flexible and generalizable solution for robotic manipulation tasks. We validated the effectiveness of our method using robotic manipulation benchmarks: RLBench, MetaWorld, and CALVIN. Our experiments demonstrate that LLM agents can successfully leverage diverse knowledge sources to solve complex tasks. Consequently, our approach significantly enhances the adaptability and robustness of robotic manipulation agents in planning across diverse environments.
RAP: Retrieval-Augmented Planning with Contextual Memory for Multimodal LLM Agents
Feb 06, 2024



Owing to recent advancements, Large Language Models (LLMs) can now be deployed as agents for increasingly complex decision-making applications in areas including robotics, gaming, and API integration. However, reflecting past experiences in current decision-making processes, an innate human behavior, continues to pose significant challenges. Addressing this, we propose Retrieval-Augmented Planning (RAP) framework, designed to dynamically leverage past experiences corresponding to the current situation and context, thereby enhancing agents' planning capabilities. RAP distinguishes itself by being versatile: it excels in both text-only and multimodal environments, making it suitable for a wide range of tasks. Empirical evaluations demonstrate RAP's effectiveness, where it achieves SOTA performance in textual scenarios and notably enhances multimodal LLM agents' performance for embodied tasks. These results highlight RAP's potential in advancing the functionality and applicability of LLM agents in complex, real-world applications.
Deep Face Recognition Model Compression via Knowledge Transfer and Distillation
Jun 03, 2019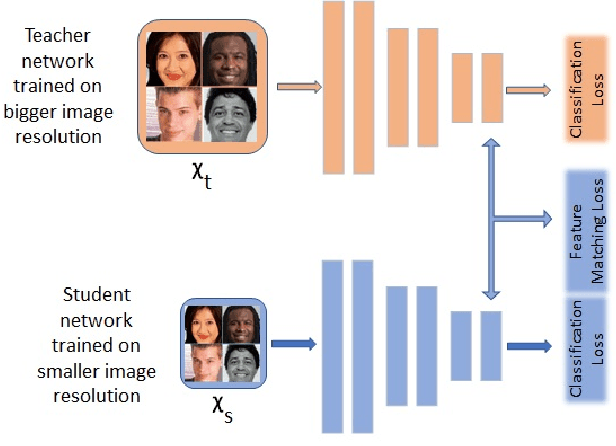
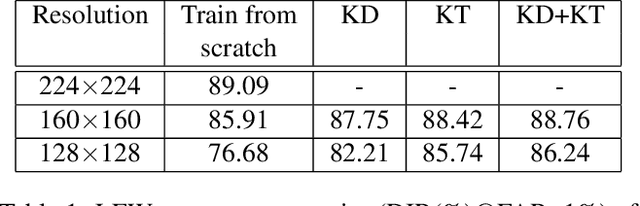
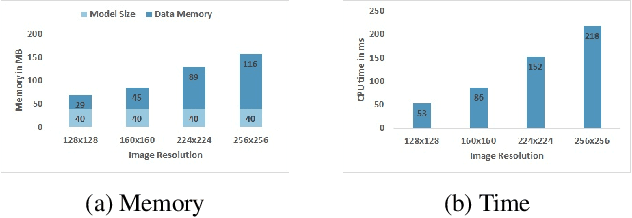
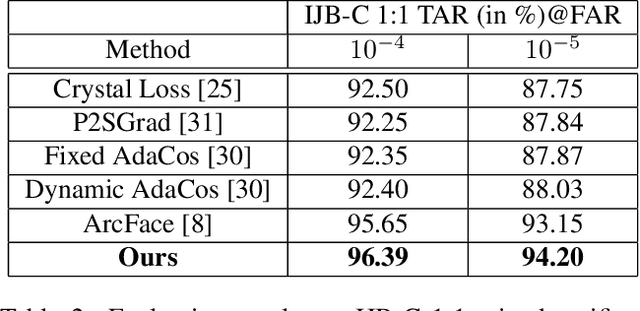
Fully convolutional networks (FCNs) have become de facto tool to achieve very high-level performance for many vision and non-vision tasks in general and face recognition in particular. Such high-level accuracies are normally obtained by very deep networks or their ensemble. However, deploying such high performing models to resource constraint devices or real-time applications is challenging. In this paper, we present a novel model compression approach based on student-teacher paradigm for face recognition applications. The proposed approach consists of training teacher FCN at bigger image resolution while student FCNs are trained at lower image resolutions than that of teacher FCN. We explored three different approaches to train student FCNs: knowledge transfer (KT), knowledge distillation (KD) and their combination. Experimental evaluation on LFW and IJB-C datasets demonstrate comparable improvements in accuracies with these approaches. Training low-resolution student FCNs from higher resolution teacher offer fourfold advantage of accelerated training, accelerated inference, reduced memory requirements and improved accuracies. We evaluated all models on IJB-C dataset and achieved state-of-the-art results on this benchmark. The teacher network and some student networks even achieved Top-1 performance on IJB-C dataset. The proposed approach is simple and hardware friendly, thus enables the deployment of high performing face recognition deep models to resource constraint devices.
A Good Practice Towards Top Performance of Face Recognition: Transferred Deep Feature Fusion
Feb 09, 2018
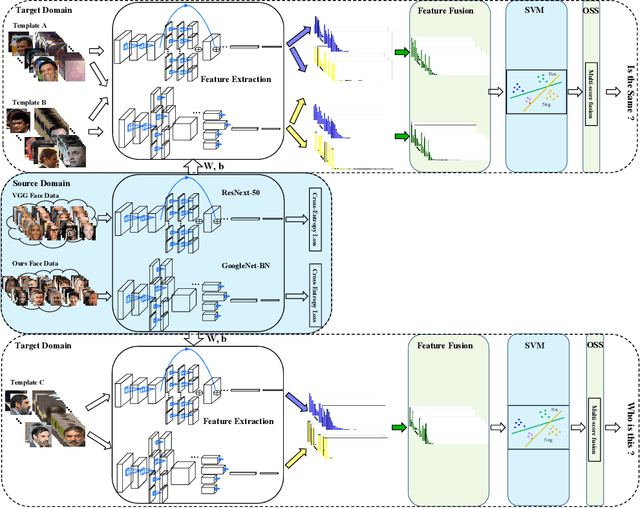
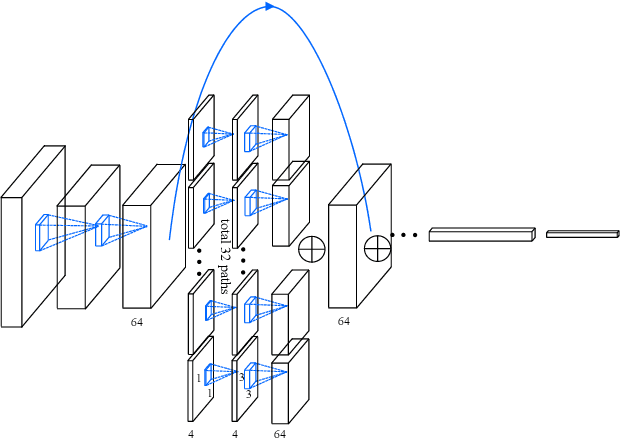
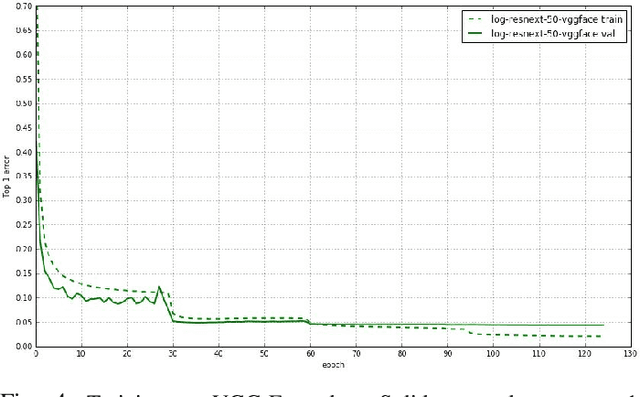
Unconstrained face recognition performance evaluations have traditionally focused on Labeled Faces in the Wild (LFW) dataset for imagery and the YouTubeFaces (YTF) dataset for videos in the last couple of years. Spectacular progress in this field has resulted in saturation on verification and identification accuracies for those benchmark datasets. In this paper, we propose a unified learning framework named Transferred Deep Feature Fusion (TDFF) targeting at the new IARPA Janus Benchmark A (IJB-A) face recognition dataset released by NIST face challenge. The IJB-A dataset includes real-world unconstrained faces from 500 subjects with full pose and illumination variations which are much harder than the LFW and YTF datasets. Inspired by transfer learning, we train two advanced deep convolutional neural networks (DCNN) with two different large datasets in source domain, respectively. By exploring the complementarity of two distinct DCNNs, deep feature fusion is utilized after feature extraction in target domain. Then, template specific linear SVMs is adopted to enhance the discrimination of framework. Finally, multiple matching scores corresponding different templates are merged as the final results. This simple unified framework exhibits excellent performance on IJB-A dataset. Based on the proposed approach, we have submitted our IJB-A results to National Institute of Standards and Technology (NIST) for official evaluation. Moreover, by introducing new data and advanced neural architecture, our method outperforms the state-of-the-art by a wide margin on IJB-A dataset.